1.Spark 消费Kafka,分布式的情况下,如何保证消息的顺序?
Kafka分布式的单位是Partition,如何保证消息有序,需要分一下几个条件讨论。
- 同一个Partition用一个 write ahead log 组织,所以可以保证FIFO的顺序。
- 不同Partition之间不能保证顺序但是绝大多数用户可以通过 message key 来定义,因为同一个key的 message 可以保证只发送到同一个Partition。如果说key是user id, table row id 等等,所以同一个user 或者同一个 record 的消息永远只会发送到同一个 Partition 上,保证了同一个 user 或 record 的顺序。
- 当然,如果你有 key skewnes就有些麻烦,需要谨慎处理。
实际情况中,(1)不关注顺序的业务大量存在,队列无序不代表消息无序。(2)我们不保证队列的全局有序,但可以保证消息的局部有序,举个例子:保证来自同一个order id 的消息,是有序的。Kafka中发送1条消息的时候,可以指定(topic,partition,key) 3个参数。partition和key是可选的,如果你指partition,那就是所有消息发往同一个partition,就是有序的,而且在消费端,Kafka保证,1个partition只能被一个consumer消费。或者你指定key(比如order id),具有同一个key的所有消息,会发往同一个partition,也就是有序。
2.对于Spark中的数据倾斜问题好的法案。
简单一句: Spark 数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义 Partitioner,使用 Map 侧 Join 代替 Reduce 侧 Join(内存表合并),给倾斜 Key 加上随机前缀等。
什么是数据倾斜 对 Spark/Hadoop 这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。数据倾斜指的是,并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈(木桶效应)。
数据倾斜是如何造成的 在 Spark 中,同一个 Stage 的不同 Partition 可以并行处理,而具有依赖关系的不同 Stage 之间是串行处理的。假设某个 Spark Job 分为 Stage 0和 Stage 1两个 Stage,且 Stage 1依赖于 Stage 0,那 Stage 0完全处理结束之前不会处理Stage 1。而 Stage 0可能包含 N 个 Task,这 N 个 Task 可以并行进行。如果其中 N-1个 Task 都在10秒内完成,而另外一个 Task 却耗时1分钟,那该 Stage 的总时间至少为1分钟。换句话说,一个 Stage 所耗费的时间,主要由最慢的那个 Task 决定。由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。
具体解决方案 :
1. 调整并行度分散同一个 Task 的不同 Key: Spark 在做 Shuffle 时,默认使用 HashPartitioner对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的数据远大于其它 Task,从而造成数据倾斜。如果调整 Shuffle 时的并行度,使得原本被分配到同一 Task 的不同 Key 发配到不同 Task 上处理,则可降低原 Task 所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。图中左边绿色框表示 kv 样式的数据,key 可以理解成 name。可以看到 Task0 分配了许多的 key,调整并行度,多了几个 Task,那么每个 Task 处理的数据量就分散了。
2. 自定义Partitioner: 使用自定义的 Partitioner(默认为 HashPartitioner),将原本被分配到同一个 Task 的不同 Key 分配到不同 Task,可以拿上图继续想象一下,通过自定义 Partitioner 可以把原本分到 Task0 的 Key 分到 Task1,那么 Task0 的要处理的数据量就少了。
3. 将 Reduce side(侧) Join 转变为 Map side(侧) Join: 通过 Spark 的 Broadcast 机制,将 Reduce 侧 Join 转化为 Map 侧 Join,避免 Shuffle 从而完全消除 Shuffle 带来的数据倾斜。可以看到 RDD2 被加载到内存中了。
4. 为 skew 的 key 增加随机前/后缀: 为数据量特别大的 Key 增加随机前/后缀,使得原来 Key 相同的数据变为 Key 不相同的数据,从而使倾斜的数据集分散到不同的 Task 中,彻底解决数据倾斜问题。Join 另一则的数据中,与倾斜 Key 对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜 Key 如何加前缀,都能与之正常 Join。
5. 大表随机添加 N 种随机前缀,小表扩大 N 倍: 如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大(很难一个 Key 一个 Key 都加上后缀)。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍),可以看到 RDD2 扩大了 N 倍了,再和加完前缀的大数据做笛卡尔积。
3. 你所理解的 Spark 的 shuffle 过程?
Spark shuffle 处于一个宽依赖,可以实现类似混洗的功能,将相同的 Key 分发至同一个 Reducer上进行处理。
4. Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
在我们的开发过程中,能避免则尽可能避免使用 reduceByKey、join、distinct、repartition 等会进行 shuffle 的算子,尽量使用 map 类的非 shuffle 算子。这 样的话,没有 shuffle 操作或者仅有较少 shuffle 操作的 Spark 作业,可以大大减少性能开销。
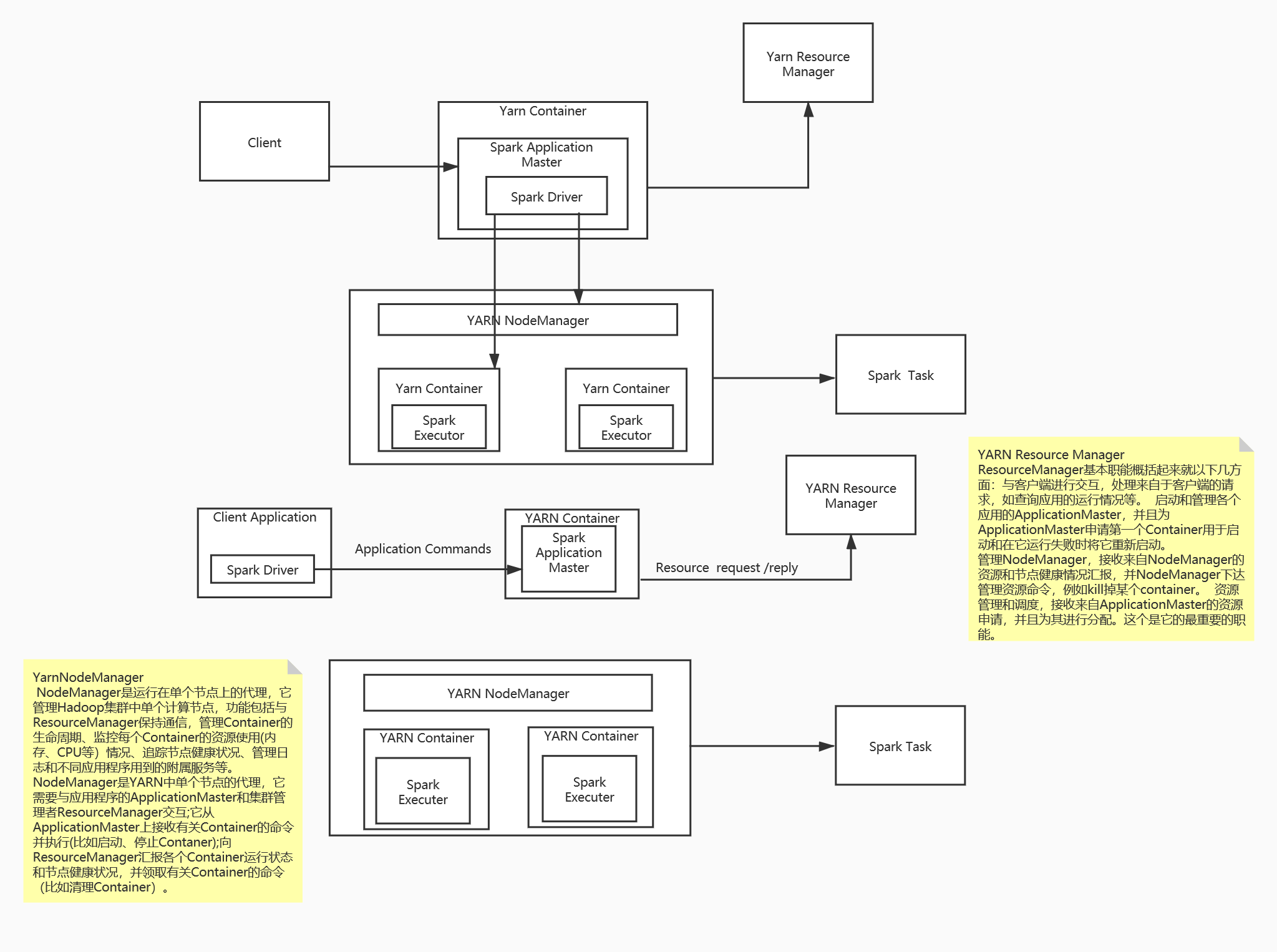
5. Spark on yarn 作业执行流程,yarn-client 和 yarn cluster 有什么区别。
1. Spark 支持资源动态共享,运行于 Yarn 的框架都共享一个集中配置好的资源池 。
2. 可以很方便的利用 Yarn 的资源调度特性来做分类·,隔离以及优先级控制负载,拥有更灵活的调度策略 。
3. Yarn 可以自由地选择 executor 数量 。
4. Yarn 是唯一支持 Spark 安全的集群管理器,使用 Yarn,Spark 可以运行于 Kerberized Hadoop 之上,在它们进程之间进行安全认证。
yarn-client 和 yarn cluster 的异同 1. 从广义上讲,yarn-cluster 适用于生产环境。而 yarn-client 适用于交互和调试,也就是希望快速地看到 application 的输出。2. 从深层次的含义讲,yarn-cluster 和 yarn-client 模式的区别其实就是 Application Master 进程的区别,yarn-cluster 模式下,driver 运行在 AM(Application Master)中,它负责向 YARN 申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉 Client,作业会继续在 YARN 上运行。然而 yarn-cluster 模式不适合运行交互类型的作业。而 yarn-client 模式下,Application Master 仅仅向 YARN 请求 executor,Client 会和请求的 container 通信来调度他们工作,也就是说 Client 不能离开。
6. Spark为什么快,Spark SQL 一定比 Hive 快吗
Spark SQL 比 Hadoop Hive 快,是有一定条件的,而且不是 Spark SQL 的引擎比 Hive 的引擎快,相反,Hive 的 HQL 引擎还比 Spark SQL 的引擎更快。其 实,关键还是在于 Spark 本身快。
-
消除了冗余的 HDFS 读写: Hadoop 每次 shuffle 操作后,必须写到磁盘,而 Spark 在 shuffle 后不一定落盘,可以 cache 到内存中,以便迭代时使用。如果操作复杂,很多的 shufle 操作,那么 Hadoop 的读写 IO 时间会大大增加,也是 Hive 更慢的主要原因了。
-
消除了冗余的 MapReduce 阶段: Hadoop 的 shuffle 操作一定连着完整的 MapReduce 操作,冗余繁琐。而 Spark 基于 RDD 提供了丰富的算子操作,且 reduce 操作产生 shuffle 数据,可以缓存在内存中。
-
JVM 的优化: Hadoop 每次 MapReduce 操作,启动一个 Task 便会启动一次 JVM,基于进程的操作。而 Spark 每次 MapReduce 操作是基于线程的,只在启动 Executor 是启动一次 JVM,内存的 Task 操作是在线程复用的。每次启动 JVM 的时间可能就需要几秒甚至十几秒,那么当 Task 多了,这个时间 Hadoop 不知道比 Spark 慢了多少。
记住一种反例 考虑一种极端查询:
Select month_id, sum(sales) from T group by month_id;这个查询只有一次 shuffle 操作,此时,也许 Hive HQL 的运行时间也许比 Spark 还快,反正 shuffle 完了都会落一次盘,或者都不落盘。
结论 Spark 快不是绝对的,但是绝大多数,Spark 都比 Hadoop 计算要快。这主要得益于其对 mapreduce 操作的优化以及对 JVM 使用的优化。
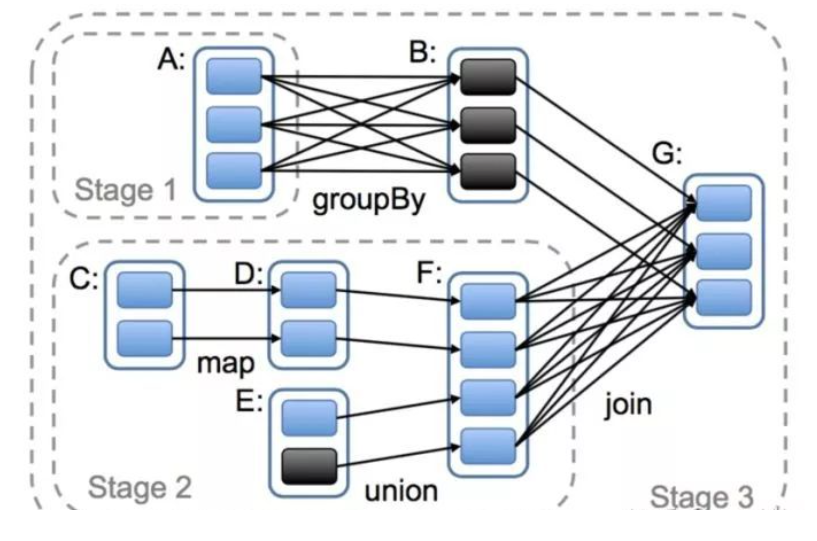
7. RDD, DAG, Stage怎么理解?
DAG Spark 中使用 DAG 对 RDD 的关系进行建模,描述了 RDD 的依赖关系,这种关系也被称之为 lineage(血缘),RDD 的依赖关系使用 Dependency 维护。DAG 在 Spark 中的对应的实现为 DAGScheduler。
RDD RDD 是 Spark 的灵魂,也称为弹性分布式数据集。一个 RDD 代表一个可以被分区的只读数据集。RDD 内部可以有许多分区(partitions),每个分区又拥有大量的记录(records)。Rdd的五个特征:1. dependencies: 建立 RDD 的依赖关系,主要 RDD 之间是宽窄依赖的关系,具有窄依赖关系的 RDD 可以在同一个 stage 中进行计算。2. partition: 一个 RDD 会有若干个分区,分区的大小决定了对这个 RDD 计算的粒度,每个 RDD 的分区的计算都在一个单独的任务中进行。3. preferedlocations: 按照“移动数据不如移动计算”原则,在 Spark 进行任务调度的时候,优先将任务分配到数据块存储的位置。4. compute: Spark 中的计算都是以分区为基本单位的,compute 函数只是对迭代器进行复合,并不保存单次计算的结果。5. partitioner: 只存在于(K,V)类型的 RDD 中,非(K,V)类型的 partitioner 的值就是 None。
RDD 的算子主要分成2类,action 和 transformation。这里的算子概念,可以理解成就是对数据集的变换。action 会触发真正的作业提交,而 transformation 算子是不会立即触发作业提交的。每一个 transformation 方法返回一个新的 RDD。只是某些 transformation 比较复杂,会包含多个子 transformation,因而会生成多个 RDD。这就是实际 RDD 个数比我们想象的多一些 的原因。通常是,当遇到 action 算子时会触发一个job的提交,然后反推回去看前面的 transformation 算子,进而形成一张有向无环图。
Stage 在 DAG 中又进行 stage 的划分,划分的依据是依赖是否是 shuffle 的,每个 stage 又可以划分成若干 task。接下来的事情就是 driver 发送 task 到 executor,executor 自己的线程池去执行这些 task,完成之后将结果返回给 driver。action 算子是划分不同 job 的依据。
8. RDD 如何通过记录更新的方式容错
RDD 的容错机制实现分布式数据集容错方法有两种: 1. 数据检查点 2. 记录更新。
RDD 采用记录更新的方式:记录所有更新点的成本很高。所以,RDD只支持粗颗粒变换,即只记录单个块(分区)上执行的单个操作,然后创建某个 RDD 的变换序列(血统 lineage)存储下来;变换序列指,每个 RDD 都包含了它是如何由其他 RDD 变换过来的以及如何重建某一块数据的信息。因此 RDD 的容错机制又称“血统”容错。
9. 宽依赖、窄依赖怎么理解?
窄依赖指的是每一个 parent RDD 的 partition 最多被子 RDD 的一个 partition 使用(一子一亲)。
宽依赖指的是多个子 RDD 的 partition 会依赖同一个 parent RDD的 partition(多子一亲)。
RDD 作为数据结构,本质上是一个只读的分区记录集合。一个 RDD 可以包含多个分区,每个分区就是一个 dataset 片段。RDD 可以相互依赖。
首先,窄依赖可以支持在同一个 cluster node上,以 pipeline 形式执行多条命令(也叫同一个 stage 的操作),例如在执行了 map 后,紧接着执行 filter。相反,宽依赖需要所有的父分区都是可用的,可能还需要调用类似 MapReduce 之类的操作进行跨节点传递。
其次,则是从失败恢复的角度考虑。窄依赖的失败恢复更有效,因为它只需要重新计算丢失的 parent partition 即可,而且可以并行地在不同节点进行重计算(一台机器太慢就会分配到多个节点进行),相反,宽依赖牵涉 RDD 各级的多个 parent partition。
10. Job 和 Task 怎么理解
Job Spark 的 Job 来源于用户执行 action 操作(这是 Spark 中实际意义的 Job),就是从 RDD 中获取结果的操作,而不是将一个 RDD 转换成另一个 RDD 的 transformation 操作。
Task 一个 Stage 内,最终的 RDD 有多少个 partition,就会产生多少个 task。看一看图就明白了,可以数一数每个 Stage 有多少个 Task。
11. Spark 血统的概念
RDD 的 lineage 记录的是粗颗粒度的特定数据转换(transformation)操作(filter, map, join etc.)行为。当这个 RDD 的部分分区数据丢失时,它可以通过 lineage 获取足够的信息来重新运算和恢复丢失的数据分区。这种粗颗粒的数据模型,限制了 Spark 的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
12. 任务的概念
包含很多 task 的并行计算,可以认为是 Spark RDD 里面的 action,每个 action 的计算会生成一个 job。用户提交的 job 会提交给 DAGScheduler,job 会被分解成 Stage 和 Task。
13. 容错方法
Spark 选择记录更新的方式。但是,如果更新粒度太细太多,那么记录更新成本也不低。因此,RDD只支持粗粒度转换,即只记录单个块上执行的单个操作,然后将创建 RDD 的一系列变换序列(每个 RDD 都包含了他是如何由其他 RDD 变换过来的以及如何重建某一块数据的信息。因此 RDD 的容错机制又称血统容错)记录下来,以便恢复丢失的分区。lineage本质上很类似于数据库中的重做日志(Redo Log),只不过这个重做日志粒度很大,是对全局数据做同样的重做进而恢复数据。
相比其他系统的细颗粒度的内存数据更新级别的备份或者 LOG 机制,RDD 的 lineage 记录的是粗颗粒度的特定数据 transformation 操作行为。当这个 RDD 的部分分区数据丢失时,它可以通过 lineage 获取足够的信息来重新运算和恢复丢失的数据分区。
14. Spark 粗粒度和细粒度
如果问的是操作的粗细粒度,应该是,Spark 在错误恢复的时候,只需要粗粒度的记住 lineage,就可实现容错。
关于 Mesos 1. 粗粒度模式(Coarse-grained Mode): 每个应用程序的运行环境由一个 dirver 和若干个 executor 组成,其中,每个 executor 占用若干资源,内部可运行多个 task(对应多少个 slot)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用5个 executor 运行你的应用程序,每个 executor 占用5GB内存和5个 CPU,每个 executor 内部设置了5个 slot,则 Mesos 需要先为 executor 分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,Mesos 的 master 和 slave 并不知道 executor 内部各个 task 的运行情况,executor 直接将任务状态通过内部的通信机制汇报给 driver,从一定程度上可以认为,每个应用程序利用 Mesos 搭建了一个虚拟集群自己使用。2. 细粒度模式(Fine-grained Mode): 鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos 还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动 executor,但每个 executor 占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,Mesos 会为每个 executor 动态分配资源,每分配一些,便可以运行一个新任务,单个 Task 运行完之后可以马上释放对应的资源。每个 Task 会汇报状态给 Mesos slave 和 Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于 MapReduce 调度模式,每个 task 完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
Spark中,每个 application 对应一个 SparkContext。对于 SparkContext 之间的调度关系,取决于 Spark 的运行模式。对 Standalone 模式而言,Spark Master 节点先计算集群内的计算资源能否满足等待队列中的应用对内存和 CPU 资源的需求,如果可以,则 Master 创建 Spark Driver,启动应用的执行。宏观上来讲,这种对应用的调度类似于 FIFO 策略。在 Mesos 和 Yarn 模式下,底层的资源调度系统的调度策略都是由 Mesos 和 Yarn 决定的。具体分类描述如下:
Standalone 模式: 默认以用户提交 Applicaiton 的顺序来调度,即 FIFO 策略。每个应用执行时独占所有资源。如果有多个用户要共享集群资源,则可以使用参数 spark.cores.max 来配置应用在集群中可以使用的最大 CPU 核的数量。如果不配置,则采用默认参数 spark.deploy.defaultCore 的值来确定。Mesos 模式: 如果在 Mesos 上运行 Spark,用户想要静态配置资源的话,可以设置 spark.mesos.coarse 为 true,这样 Mesos 变为粗粒度调度模式。然后可以设置 spark.cores.max 指定集群中可以使用的最大核数,与上面 Standalone 模式类似。同时,在 Mesos 模式下,用户还可以设置参数 spark.executor.memory 来配置每个 executor 的内存使用量。如果想使 Mesos 在细粒度模式下运行,可以通过 mesos://<url-info> 设置动态共享 CPU core 的执行模式。在这种模式下,应用不执行时的空闲 CPU 资源得以被其他用户使用,提升了 CPU 使用率。
15. Spark优越性
一、Spark 的5大优势:1. 更高的性能。因为数据被加载到集群主机的分布式内存中。数据可以被快速的转换迭代,并缓存用以后续的频繁访问需求。在数据全部加载到内存的情况下,Spark可以比Hadoop快100倍,在内存不够存放所有数据的情况下快hadoop10倍。2. 通过建立在Java,Scala,Python,SQL(应对交互式查询)的标准API以方便各行各业使用,同时还含有大量开箱即用的机器学习库。3. 与现有Hadoop 1和2.x(YARN)生态兼容,因此机构可以无缝迁移。4. 方便下载和安装。方便的shell(REPL: Read-Eval-Print-Loop)可以对API进行交互式的学习。5. 借助高等级的架构提高生产力,从而可以讲精力放到计算上。
二、MapReduce与Spark相比,有哪些异同点:1、基本原理上:(1) MapReduce:基于磁盘的大数据批量处理系统 (2)Spark:基于RDD(弹性分布式数据集)数据处理,显示将RDD数据存储到磁盘和内存中。2、模型上:(1) MapReduce可以处理超大规模的数据,适合日志分析挖掘等较少的迭代的长任务需求,结合了数据的分布式的计算。(2) Spark:适合数据的挖掘,机器学习等多轮迭代式计算任务。
16. Transformation和action是什么?区别?举几个常用方法
RDD 创建后就可以在 RDD 上进行数据处理。RDD 支持两种操作: 1. 转换(transformation): 即从现有的数据集创建一个新的数据集 2. 动作(action): 即在数据集上进行计算后,返回一个值给 Driver 程序
RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter() ,而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first() 。Spark 对待转化操作和行动操作的方式很不一样,因此理解你正在进行的操作的类型是很重要的。如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,你可以看看它的返回值类型:转化操作返回的是 RDD,而行动操作返回的是其他的数据类型。
RDD 中所有的 Transformation 都是惰性的,也就是说,它们并不会直接计算结果。相反的它们只是记住了这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给 Driver 的 Action 时,这些 Transformation 才会真正运行。
这个设计让 Spark 更加有效的运行。
17. Spark作业提交流程是怎么样的
-
spark-submit提交代码,执行new SparkContext(),在 SparkContext 里构造DAGScheduler和TaskScheduler。 -
TaskScheduler 会通过后台的一个进程,连接 Master,向 Master 注册 Application。
-
Master 接收到 Application 请求后,会使用相应的资源调度算法,在 Worker 上为这个 Application 启动多个 Executer。
-
Executor 启动后,会自己反向注册到 TaskScheduler 中。所有 Executor 都注册到 Driver 上之后,SparkContext 结束初始化,接下来往下执行我们自己的代码。
-
每执行到一个 Action,就会创建一个 Job。Job 会提交给 DAGScheduler。
-
DAGScheduler 会将 Job划分为多个 stage,然后每个 stage 创建一个 TaskSet。
-
TaskScheduler 会把每一个 TaskSet 里的 Task,提交到 Executor 上执行。
-
Executor 上有线程池,每接收到一个 Task,就用 TaskRunner 封装,然后从线程池里取出一个线程执行这个 task。(TaskRunner 将我们编写的代码,拷贝,反序列化,执行 Task,每个 Task 执行 RDD 里的一个 partition)
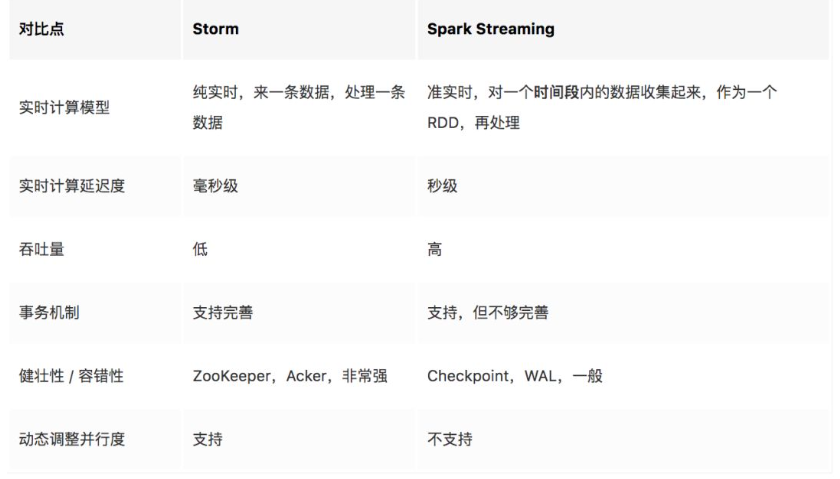
18. Spark streamning工作流程是怎么样的,和Storm比有什么区别
Spark Streaming 与 Storm 都可以用于进行实时流计算。但是他们两者的区别是非常大的。其中区别之一,就是,Spark Streaming 和 Storm 的计算模型完全不一样,Spark Streaming 是基于 RDD 的,因此需要将一小段时间内的,比如1秒内的数据,收集起来,作为一个 RDD,然后再针对这个 batch 的数据进行处理。而 Storm 却可以做到每来一条数据,都可以立即进行处理和计算。因此,Spark Streaming 实际上严格意义上来说,只能称作准实时的流计算框架;而 Storm 是真正意义上的实时计算框架。此外,Storm 支持的一项高级特性,是 Spark Streaming 暂时不具备的,即 Storm 支持在分布式流式计算程序(Topology)在运行过程中,可以动态地调整并行度,从而动态提高并发处理能力。而 Spark Streaming 是无法动态调整并行度的。但是 Spark Streaming 也有其优点,首先 Spark Streaming 由于是基于 batch 进行处理的,因此相较于 Storm 基于单条数据进行处理,具有数倍甚至数十倍的吞吐量。此外,Spark Streaming 由于也身处于 Spark 生态圈内,因此Spark Streaming可以与Spark Core、Spark SQL,甚至是Spark MLlib、Spark GraphX进行无缝整合。流式处理完的数据,可以立即进行各种map、reduce转换操作,可以立即使用sql进行查询,甚至可以立即使用machine learning或者图计算算法进行处理。这种一站式的大数据处理功能和优势,是Storm无法匹敌的。因此,综合上述来看,通常在对实时性要求特别高,而且实时数据量不稳定,比如在白天有高峰期的情况下,可以选择使用Storm。但是如果是对实时性要求一般,允许1秒的准实时处理,而且不要求动态调整并行度的话,选择Spark Streaming是更好的选择。
19. Spark sql你使用过没有,在哪个项目里面使用的
离线 ETL 之类的,结合机器学习等
20. Spark 机器学习和 Spark 图计算接触过没有,举例说明你用它做过什么?
Spark 提供了很多机器学习库,我们只需要填入数据,设置参数就可以用了。使用起来非常方便。另外一方面,由于它把所有的东西都写到了内部,我们无法修改其实现过程。要想修改里面的某个环节,还的修改源码,重新编译。比如 kmeans 算法,如果没有特殊需求,很方便。但是spark内部使用的两个向量间的距离是欧式距离。如果你想改为余弦或者马氏距离,就的重新编译源码了。Spark 里面的机器学习库都是一些经典的算法,这些代码网上也好找。这些代码使用起来叫麻烦,但是很灵活。Spark 有一个很大的优势,那就是 RDD。模型的训练完全是并行的。
Spark 的 ML 和 MLLib 两个包区别和联系
-
技术角度上,面向的数据集类型不一样: ML 的 API 是面向 Dataset 的(Dataframe 是 Dataset 的子集,也就是 Dataset[Row]), mllib 是面对 RDD 的。Dataset 和 RDD 有啥不一样呢?Dataset 的底端是 RDD。Dataset 对 RDD 进行了更深一层的优化,比如说有 sql 语言类似的黑魔法,Dataset 支持静态类型分析所以在 compile time 就能报错,各种 combinators(map,foreach 等)性能会更好,等等。
-
编程过程上,构建机器学习算法的过程不一样: ML 提倡使用 pipelines,把数据想成水,水从管道的一段流入,从另一端流出。ML 是1.4比 Mllib 更高抽象的库,它解决如果简洁的设计一个机器学习工作流的问题,而不是具体的某种机器学习算法。未来这两个库会并行发展。
21. Spark RDD是怎么容错的,基本原理是什么?
一般来说,分布式数据集的容错性有两种方式:数据检查点和记录数据的更新。
面向大规模数据分析,数据检查点操作成本很高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗更多的存储资源。 因此,Spark选择记录更新的方式。但是,如果更新粒度太细太多,那么记录更新成本也不低。因此,RDD只支持粗粒度转换,即只记录单个块上执行的单个操作,然后将创建RDD的一系列变换序列(每个RDD都包含了他是如何由其他RDD变换过来的以及如何重建某一块数据的信息。因此RDD的容错机制又称“血统(Lineage)”容错)记录下来,以便恢复丢失的分区。 Lineage本质上很类似于数据库中的重做日志(Redo Log),只不过这个重做日志粒度很大,是对全局数据做同样的重做进而恢复数据。
Lineage机制
Lineage简介
相比其他系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据Transformation操作(如filter、map、join等)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。因为这种粗颗粒的数据模型,限制了Spark的运用场合,所以Spark并不适用于所有高性能要求的场景,但同时相比细颗粒度的数据模型,也带来了性能的提升。
两种依赖关系
RDD在Lineage依赖方面分为两种:窄依赖(Narrow Dependencies)与宽依赖(Wide Dependencies,源码中称为Shuffle
Dependencies),用来解决数据容错的高效性。
-
窄依赖是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。1个父RDD分区对应1个子RDD分区,这其中又分两种情况:1个子RDD分区对应1个父RDD分区(如map、filter等算子),1个子RDD分区对应N个父RDD分区(如co-paritioned(协同划分)过的Join)。
-
宽依赖是指子RDD的分区依赖于父RDD的多个分区或所有分区,即存在一个父RDD的一个分区对应一个子RDD的多个分区。1个父RDD分区对应多个子RDD分区,这其中又分两种情况:1个父RDD对应所有子RDD分区(未经协同划分的Join)或者1个父RDD对应非全部的多个RDD分区(如groupByKey)。
本质理解:根据父RDD分区是对应1个还是多个子RDD分区来区分窄依赖(父分区对应一个子分区)和宽依赖(父分区对应多个子分
区)。如果对应多个,则当容错重算分区时,因为父分区数据只有一部分是需要重算子分区的,其余数据重算就造成了冗余计算。
对于宽依赖,Stage计算的输入和输出在不同的节点上,对于输入节点完好,而输出节点死机的情况,通过重新计算恢复数据这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上追溯其祖先看是否可以重试(这就是lineage,血统的意思),窄依赖对于数据的重算开销要远小于宽依赖的数据重算开销。窄依赖和宽依赖的概念主要用在两个地方:一个是容错中相当于Redo日志的功能;另一个是在调度中构建DAG作为不同Stage的划分点。
依赖关系的特性
第一,窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;宽依赖则要等到父RDD所有数据都计算完成之后,并且父RDD的计算结果进行hash并传到对应节点上之后才能计算子RDD。
第二,数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;对于宽依赖则要将祖先RDD中的所有数据块全部重新计算来恢复。所以在长“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点。也是这两个特性要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
容错原理
在容错机制中,如果一个节点死机了,而且运算窄依赖,则只要把丢失的父RDD分区重算即可,不依赖于其他节点。而宽依赖需要父RDD的所有分区都存在,重算就很昂贵了。可以这样理解开销的经济与否:在窄依赖中,在子RDD的分区丢失、重算父RDD分区时,父RDD相应分区的所有数据都是子RDD分区的数据,并不存在冗余计算。在宽依赖情况下,丢失一个子RDD分区重算的每个父RDD的每个分区的所有数据并不是都给丢失的子RDD分区用的,会有一部分数据相当于对应的是未丢失的子RDD分区中需要的数据,这样就会产生冗余计算开销,这也是宽依赖开销更大的原因。因此如果使用Checkpoint算子来做检查点,不仅要考虑Lineage是否足够长,也要考虑是否有宽依赖,对宽依赖加Checkpoint是最物有所值的。
Checkpoint机制
通过上述分析可以看出在以下两种情况下,RDD需要加检查点。
-
DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)。
-
在宽依赖上做Checkpoint获得的收益更大。
由于RDD是只读的,所以Spark的RDD计算中一致性不是主要关心的内容,内存相对容易管理,这也是设计者很有远见的地方,这样减少了框架的复杂性,提升了性能和可扩展性,为以后上层框架的丰富奠定了强有力的基础。
在RDD计算中,通过检查点机制进行容错,传统做检查点有两种方式:通过冗余数据和日志记录更新操作。在RDD中的doCheckPoint方法相当于通过冗余数据来缓存数据,而之前介绍的血统就是通过相当粗粒度的记录更新操作来实现容错的。
检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
一个 Streaming Application 往往需要7*24不间断的跑,所以需要有抵御意外的能力(比如机器或者系统挂掉,JVM crash等)。为了让这成为可能,Spark Streaming需要 checkpoint 足够多信息至一个具有容错设计的存储系统才能让 Application 从失败中恢复。Spark Streaming 会 checkpoint 两种类型的数据。
Metadata(元数据) checkpointing - 保存定义了 Streaming 计算逻辑至类似 HDFS 的支持容错的存储系统。用来恢复 driver,元数据包括:
-
-
配置 - 用于创建该 streaming application 的所有配置
-
DStream 操作 - DStream 一些列的操作
-
未完成的 batches - 那些提交了 job 但尚未执行或未完成的 batches
-
Data checkpointing - 保存已生成的RDDs至可靠的存储。这在某些 stateful 转换中是需要的,在这种转换中,生成 RDD 需要依赖前面的 batches,会导致依赖链随着时间而变长。为了避免这种没有尽头的变长,要定期将中间生成的 RDDs 保存到可靠存储来切断依赖链具体来说,metadata checkpointing主要还是从drvier失败中恢复,而Data Checkpoing用于对有状态的transformation操作进行checkpointing
Checkpointing具体的使用方式时通过下列方法:
//checkpointDirectory为checkpoint文件保存目录
streamingContext.checkpoint(checkpointDirectory)什么时候需要启用 checkpoint?
什么时候该启用 checkpoint 呢?满足以下任一条件:
-
使用了 stateful 转换 - 如果 application 中使用了
updateStateByKey或reduceByKeyAndWindow等 stateful 操作,必须提供 checkpoint 目录来允许定时的 RDD checkpoint -
希望能从意外中恢复 driver
如果 streaming app 没有 stateful 操作,也允许 driver 挂掉后再次重启的进度丢失,就没有启用 checkpoint的必要了。
如何使用 checkpoint?
启用 checkpoint,需要设置一个支持容错 的、可靠的文件系统(如 HDFS、s3 等)目录来保存 checkpoint 数据。通过调用 streamingContext.checkpoint(checkpointDirectory) 来完成。另外,如果你想让你的 application 能从 driver 失败中恢复,你的 application 要满足:
-
若 application 为首次重启,将创建一个新的 StreamContext 实例
-
如果 application 是从失败中重启,将会从 checkpoint 目录导入 checkpoint 数据来重新创建 StreamingContext 实例
通过 StreamingContext.getOrCreate 可以达到目的:
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()context.awaitTermination()如果 checkpointDirectory 存在,那么 context 将导入 checkpoint 数据。如果目录不存在,函数 functionToCreateContext 将被调用并创建新的 context除调用 getOrCreate 外,还需要你的集群模式支持 driver 挂掉之后重启之。例如,在 yarn 模式下,driver 是运行在 ApplicationMaster 中,若 ApplicationMaster 挂掉,yarn 会自动在另一个节点上启动一个新的 ApplicationMaster。需要注意的是,随着 streaming application 的持续运行,checkpoint 数据占用的存储空间会不断变大。因此,需要小心设置checkpoint 的时间间隔。设置得越小,checkpoint 次数会越多,占用空间会越大;如果设置越大,会导致恢复时丢失的数据和进度越多。一般推荐设置为 batch duration 的5~10倍。
导出 checkpoint 数据
上文提到,checkpoint 数据会定时导出到可靠的存储系统,那么
-
在什么时机进行 checkpoint
-
checkpoint 的形式是怎么样的
checkpoint 的时机
在 Spark Streaming 中,JobGenerator 用于生成每个 batch 对应的 jobs,它有一个定时器,定时器的周期即初始化 StreamingContext 时设置的 batchDuration。这个周期一到,JobGenerator 将调用generateJobs方法来生成并提交 jobs,这之后调用 doCheckpoint 方法来进行 checkpoint。doCheckpoint 方法中,会判断当前时间与 streaming application start 的时间之差是否是 checkpoint duration 的倍数,只有在是的情况下才进行 checkpoint。
checkpoint 的形式
最终 checkpoint 的形式是将类 Checkpoint的实例序列化后写入外部存储,值得一提的是,有专门的一条线程来做将序列化后的 checkpoint 写入外部存储。类 Checkpoint 包含以下数据:
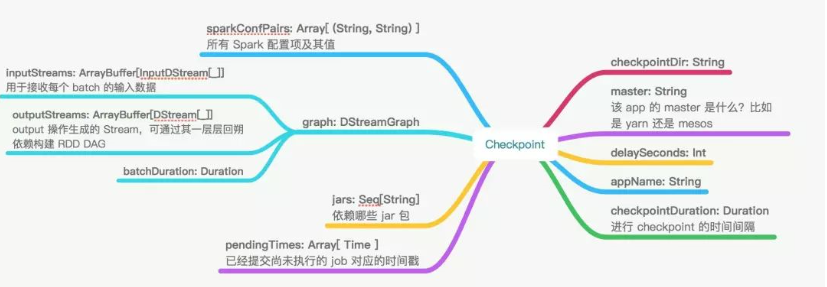
除了 Checkpoint 类,还有 CheckpointWriter 类用来导出 checkpoint,CheckpointReader 用来导入 checkpoint
Checkpoint 的局限
Spark Streaming 的 checkpoint 机制看起来很美好,却有一个硬伤。上文提到最终刷到外部存储的是类 Checkpoint 对象序列化后的数据。那么在 Spark Streaming application 重新编译后,再去反序列化 checkpoint 数据就会失败。这个时候就必须新建 StreamingContext。
针对这种情况,在我们结合 Spark Streaming + kafka 的应用中,我们自行维护了消费的 offsets,这样一来及时重新编译 application,还是可以从需要的 offsets 来消费数据,这里只是举个例子,不详细展开了。
22. 为什么要用Yarn来部署Spark?
因为 Yarn 支持动态资源配置。Standalone 模式只支持简单的固定资源分配策略,每个任务固定数量的 core,各 Job 按顺序依次分配在资源,资源不够的时候就排队。这种模式比较适合单用户的情况,多用户的情境下,会有可能有些用户的任务得不到资源。Yarn 作为通用的种子资源调度平台,除了 Spark 提供调度服务之外,还可以为其他系统提供调度,如 Hadoop MapReduce, Hive 等。
23. 说说yarn-cluster和yarn-client的异同点。
cluster 模式会在集群的某个节点上为 Spark 程序启动一个称为 Master 的进程,然后 Driver 程序会运行正在这个 Master 进程内部,由这种进程来启动 Driver 程序,客户端完成提交的步骤后就可以退出,不需要等待 Spark 程序运行结束,这是四一职中适合生产环境的运行方式client 模式也有一个 Master 进程,但是 Driver 程序不会运行在这个 Master 进程内部,而是运行在本地,只是通过 Master 来申请资源,直到运行结束,这 种模式非常适合需要交互的计算。显然 Driver 在 client 模式下会对本地资源造成一定的压力。
24. 解释一下 groupByKey, reduceByKey 还有 reduceByKeyLocally
groupByKey
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
该函数用于将RDD[K,V]中每个K对应的V值,合并到一个集合Iterable[V]中,参数numPartitions用于指定分区数;参数partitioner用于指定分区函数;
scala> var rdd1 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[89] at makeRDD at :21
scala> rdd1.groupByKey().collect
res81: Array[(String, Iterable[Int])] = Array((A,CompactBuffer(0, 2)), (B,CompactBuffer(2, 1)), (C,CompactBuffer(1)))reduceByKey
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
该函数用于将RDD[K,V]中每个K对应的V值根据映射函数来运算。
参数numPartitions用于指定分区数;
参数partitioner用于指定分区函数;
scala> var rdd1 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[91] at makeRDD at :21
scala> rdd1.partitions.size
res82: Int = 15
scala> var rdd2 = rdd1.reduceByKey((x,y) => x + y)
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[94] at reduceByKey at :23
scala> rdd2.collect
res85: Array[(String, Int)] = Array((A,2), (B,3), (C,1))
scala> rdd2.partitions.size
res86: Int = 15
scala> var rdd2 = rdd1.reduceByKey(new org.apache.spark.HashPartitioner(2),(x,y) => x + y)
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[95] at reduceByKey at :23
scala> rdd2.collect
res87: Array[(String, Int)] = Array((B,3), (A,2), (C,1))
scala> rdd2.partitions.size
res88: Int = 2reduceByKeyLocally
def reduceByKeyLocally(func: (V, V) => V): Map[K, V]
该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个Map[K,V]中,而不是RDD[K,V]。
scala> var rdd1 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[91] at makeRDD at :21
scala> rdd1.reduceByKeyLocally((x,y) => x + y)
res90: scala.collection.Map[String,Int] = Map(B -> 3, A -> 2, C -> 1)25. 说说 persist() 和 cache() 的异同
cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间。
cache和persist的区别
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def cache(): this.type = persist()说明是cache()调用了persist(), 想要知道二者的不同还需要看一下persist函数:
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)可以看到persist()内部调用了persist(StorageLevel.MEMORY_ONLY),继续深入:
/**
* Set this RDD's storage level to persist its values across operations after the first time
* it is computed. This can only be used to assign a new storage level if the RDD does not
* have a storage level set yet..
*/
def persist(newLevel: StorageLevel): this.type = {
// TODO: Handle changes of StorageLevel
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
sc.persistRDD(this)
// Register the RDD with the ContextCleaner for automatic GC-based cleanup
sc.cleaner.foreach(_.registerRDDForCleanup(this))
storageLevel = newLevel
this
}可以看出来persist有一个 StorageLevel 类型的参数,这个表示的是RDD的缓存级别。
至此便可得出cache和persist的区别了:cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。
RDD的缓存级别
顺便看一下RDD都有哪些缓存级别,查看 StorageLevel 类的源码:
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false)
......
}可以看到这里列出了12种缓存级别,但这些有什么区别呢?可以看到每个缓存级别后面都跟了一个StorageLevel的构造函数,里面包含了4个或5个参数,如下
val MEMORY_ONLY = new StorageLevel(false, true, false, true)查看其构造函数
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
extends Externalizable {
......
def useDisk: Boolean = _useDisk
def useMemory: Boolean = _useMemory
def useOffHeap: Boolean = _useOffHeap
def deserialized: Boolean = _deserialized
def replication: Int = _replication
......
}可以看到StorageLevel类的主构造器包含了5个参数:
- useDisk:使用硬盘(外存)
- useMemory:使用内存
- useOffHeap:使用堆外内存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
- deserialized:反序列化,其逆过程序列化(Serialization)是java提供的一种机制,将对象表示成一连串的字节;而反序列化就表示将字节恢复为对象的过程。序列化是对象永久化的一种机制,可以将对象及其属性保存起来,并能在反序列化后直接恢复这个对象
- replication:备份数(在多个节点上备份)
理解了这5个参数,StorageLevel 的12种缓存级别就不难理解了。
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) 就表示使用这种缓存级别的RDD将存储在硬盘以及内存中,使用序列化(在硬盘中),并且在多个节点上备份2份(正常的RDD只有一份)
另外还注意到有一种特殊的缓存级别
val OFF_HEAP = new StorageLevel(false, false, true, false)使用了堆外内存,StorageLevel 类的源码中有一段代码可以看出这个的特殊性,它不能和其它几个参数共存。
if (useOffHeap) {
require(!useDisk, "Off-heap storage level does not support using disk")
require(!useMemory, "Off-heap storage level does not support using heap memory")
require(!deserialized, "Off-heap storage level does not support deserialized storage")
require(replication == 1, "Off-heap storage level does not support multiple replication")
}26. 可以解释一下这两段程序的异同吗
val counter = 0
val data = Seq(1, 2, 3)
data.foreach(x => counter += x)
println("Counter value: " + counter)
val counter = 0
val data = Seq(1, 2, 3)
var rdd = sc.parallelizze(data)
rdd.foreach(x => counter += x)
println("Counter value: " + counter)所有在 Driver 程序追踪的代码看上去好像在 Driver 上计算,实际上都不在本地,每个 RDD 操作都被转换成 Job 分发至集群的执行器 Executor 进程中运行,即便是单机本地运行模式,也是在单独的执行器进程上运行,与 Driver 进程属于不用的进程。所以每个 Job 的执行,都会经历序列化、网络传输、反序列化和运行的过程。再具体一点解释是 foreach 中的匿名函数 x => counter += x 首先会被序列化然后被传入计算节点,反序列化之后再运行,因为 foreach 是 Action 操作,结果会返回到 Driver 进程中。在序列化的时候,Spark 会将 Job 运行所依赖的变量、方法全部打包在一起序列化,相当于它们的副本,所以 counter 会一起被序列化,然后传输到计算节点,是计算节点上的 counter 会自增,而 Driver 程序追踪的 counter 则不会发生变化。执行完成之后,结果会返回到 Driver 程序中。而 Driver 中的 counter 依然是当初的那个 Driver 的值为0。因此说,RDD 操作不能嵌套调用,即在 RDD 操作传入的函数参数的函数体中,不可以出现 RDD 调用。
27. 说说map和mapPartitions的区别
map 中的 func 作用的是 RDD 中每一个元素,而 mapPartitioons 中的 func 作用的对象是 RDD 的一整个分区。所以 func 的类型是 Iterator<T> => Iterator<T>,其中 T 是输入 RDD 的元素类型。
28. groupByKey和reduceByKey是属于Transformation还是 Action?
前者,因为 Action 输出的不再是 RDD 了,也就意味着输出不是分布式的,而是回送到 Driver 程序。以上两种操作都是返回 RDD,所以应该属于 Transformation。
29. 说说Spark支持的3种集群管理器
Standalone 模式: 资源管理器是 Master 节点,调度策略相对单一,只支持先进先出模式。
Hadoop Yarn 模式: 资源管理器是 Yarn 集群,主要用来管理资源。Yarn 支持动态资源的管理,还可以调度其他实现了 Yarn 调度接口的集群计算,非常适用于多个集群同时部署的场景,是目前最流行的一种资源管理系统。
Apache Mesos: Mesos 是专门用于分布式系统资源管理的开源系统,与 Yarn 一样是 C++ 开发,可以对集群中的资源做弹性管理。
30. 说说Worker和Excutor的异同
Worker 是指每个及节点上启动的一个进程,负责管理本节点,jps 可以看到 Worker 进程在运行。Excutor 每个Spark 程序在每个节点上启动的一个进程,专属于一个 Spark 程序,与 Spark 程序有相同的生命周期,负责 Spark 在节点上启动的 Task,管理内存和磁盘。如果一个节点上有多个 Spark 程序,那么相应就会启动多个执行器。
31. 说说Spark提供的两种共享变量
Spark 程序的大部分操作都是 RDD 操作,通过传入函数给 RDD 操作函数来计算,这些函数在不同的节点上并发执行,内部的变量有不同的作用域,不能相互访问,有些情况下不太方便。
-
广播变量,是一个只读对象,在所有节点上都有一份缓存,创建方法是 SparkContext.broadcast()。创建之后再更新它的值是没有意义的,一般用 val 来修改定义。
-
计数器,只能增加,可以用计数或求和,支持自定义类型。创建方法是 SparkContext.accumulator(V, name)。只有 Driver 程序可以读这个计算器的变量,RDD 操作中读取计数器变量是无意义的。
-
以上两种类型都是 Spark 的共享变量。
32. 说说检查点的意义
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
cache和checkpoint的区别:
缓存(cache)把 RDD 计算出来然后放在内存中,但是RDD 的依赖链(相当于数据库中的redo 日志),也不能丢掉,当某个点某个 executor 宕了,上面cache 的RDD就会丢掉,需要通过依赖链重放计算出来。不同的是,checkpoint是把 RDD 保存在 HDFS中, 是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。
如果存在以下场景,则比较适合使用检查点机制:
1) DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)。
2) 在宽依赖上做Checkpoint获得的收益更大。
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
checkpoint写流程
RDD checkpoint 过程中会经过以下几个状态:
[ Initialized → marked for checkpointing → checkpointing in progress → checkpointed ]
转换流程如下:
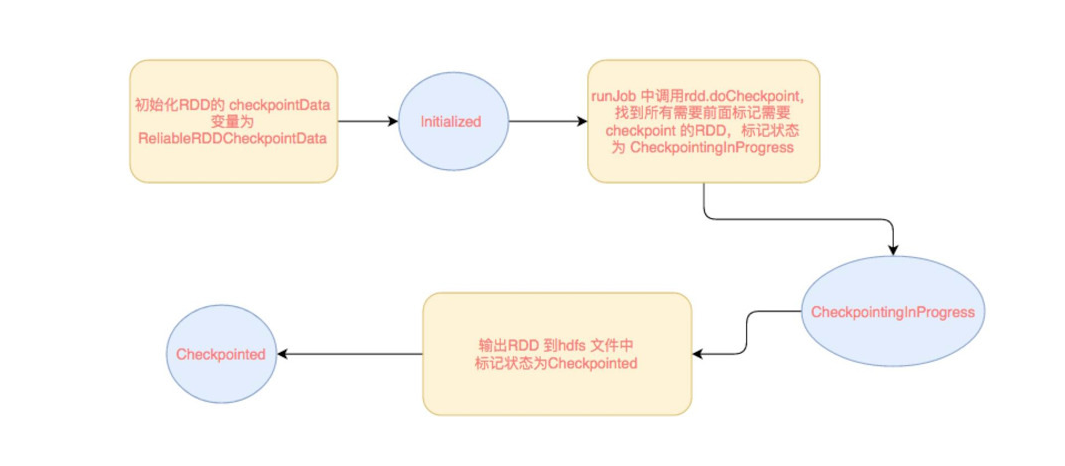
RDD 需要经过 [ Initialized --> marked for checkpointing --> checkpointing in progress --> checkpointed ] 这几个阶段才能被 checkpoint。
Initialized: 首先 driver program 需要使用 rdd.checkpoint() 去设定哪些 rdd 需要 checkpoint,设定后,该 rdd 就接受 RDDCheckpointData 管理。用户还要设定 checkpoint 的存储路径,一般在 HDFS 上。
marked for checkpointing:初始化后,RDDCheckpointData 会将 rdd 标记为 MarkedForCheckpoint,这时候标记为 Initialized 状态。
checkpointing in progress:每个 job 运行结束后会调用 finalRdd.doCheckpoint(),finalRdd 会顺着 computing chain 回溯扫描,碰到要 checkpoint 的 RDD 就将其标记为 CheckpointingInProgress,然后将写磁盘(比如写 HDFS)需要的配置文件(如 core-site.xml 等)broadcast 到其他 worker 节点上的 blockManager。完成以后,启动一个 job 来完成 checkpoint(使用 rdd.context.runJob(rdd, CheckpointRDD.writeToFile(path.toString, broadcastedConf)))。
checkpointed:job 完成 checkpoint 后,将该 rdd 的 dependency 全部清掉, 怎么清除依赖的呢, 就是把RDD 变量的强引用设置为 null,垃圾回收了,会触发 ContextCleaner 里面的监听,清除实际 BlockManager 缓存中的数据。并设定该 rdd 状态为 checkpointed。然后,为该 rdd 强加一个依赖,设置该 rdd 的 parent rdd 为 CheckpointRDD,该 CheckpointRDD 负责以后读取在文件系统上的 checkpoint 文件,生成该 rdd 的 partition。
checkpoint读流程
在 runJob() 的时候会先调用 finalRDD 的 partitions() 来确定最后会有多个 task。rdd.partitions() 会去检查(通过 RDDCheckpointData 去检查,因为它负责管理被 checkpoint 过的 rdd)该 rdd 是会否被 checkpoint 过了,如果该 rdd 已经被 checkpoint 过了,直接返回该 rdd 的 partitions 也就是 Array[Partition]。
当调用 rdd.iterator() 去计算该 rdd 的 partition 的时候,会调用 computeOrReadCheckpoint(split: Partition) 去查看该 rdd 是否被 checkpoint 过了,如果是,就调用该 rdd 的 parent rdd 的 iterator() 也就是 CheckpointRDD.iterator(),CheckpointRDD 负责读取文件系统上的文件,生成该 rdd 的 partition。这就解释了为什么那么 trickly 地为 checkpointed rdd 添加一个 parent CheckpointRDD。
总结:
- 下面来看一个关于checkpoint的例子:
object testCheckpoint {
def main(args: Array[String]): Unit = {
val sc =new SparkContext(new SparkConf().setAppName("testCheckpoint").setMaster("local[*]"))
//设置检查点目录
sc.setCheckpointDir("file:///f:/spark/checkpoint")
val rdd=sc.textFile("file:///F:/spark/b.txt").flatMap{line=>line.split(" ")}.map(word=>(word,1)).reduceByKey(_+_)
rdd.checkpoint()
//rdd.count()
rdd.groupBy(x=>x._2).collect().foreach(println)
}
}checkpoint流程分析
checkpoint初始化
我们可以看到最先调用了SparkContext的setCheckpointDir 设置了一个checkpoint 目录
我们跟进这个方法看一下
/**
* Set the directory under which RDDs are going to be checkpointed. The directory must
* be a HDFS path if running on a cluster.
*/
def setCheckpointDir(directory: String) {
// If we are running on a cluster, log a warning if the directory is local.
// Otherwise, the driver may attempt to reconstruct the checkpointed RDD from
// its own local file system, which is incorrect because the checkpoint files
// are actually on the executor machines.
if (!isLocal && Utils.nonLocalPaths(directory).isEmpty) {
logWarning("Spark is not running in local mode, therefore the checkpoint directory " +
s"must not be on the local filesystem. Directory '$directory' " +
"appears to be on the local filesystem.")
}
checkpointDir = Option(directory).map { dir =>
val path = new Path(dir, UUID.randomUUID().toString)
val fs = path.getFileSystem(hadoopConfiguration)
fs.mkdirs(path)
fs.getFileStatus(path).getPath.toString
}
}这个方法挺简单的,就创建了一个目录,接下来我们看RDD核心的checkpoint 方法,跟进去
/**
* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
* directory set with `SparkContext#setCheckpointDir` and all references to its parent
* RDDs will be removed. This function must be called before any job has been
* executed on this RDD. It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
def checkpoint(): Unit = RDDCheckpointData.synchronized {
// NOTE: we use a global lock here due to complexities downstream with ensuring
// children RDD partitions point to the correct parent partitions. In the future
// we should revisit this consideration.
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}这个方法没有返回值,逻辑只有一个判断,checkpointDir刚才设置过了,不为空,然后创建了一个ReliableRDDCheckpointData,我们来看ReliableRDDCheckpointData
/**
* An implementation of checkpointing that writes the RDD data to reliable storage.
* This allows drivers to be restarted on failure with previously computed state.
*/
private[spark] class ReliableRDDCheckpointData[T: ClassTag](@transient rdd: RDD[T])
extends RDDCheckpointData[T](rdd) with Logging {
。。。。。
}这个ReliableRDDCheckpointData的父类RDDCheckpointData我们再继续看它的父类
/**
* RDD 需要经过
* [ Initialized --> CheckpointingInProgress--> Checkpointed ]
* 这几个阶段才能被 checkpoint。
*/
private[spark] object CheckpointState extends Enumeration {
type CheckpointState = Value
val Initialized, CheckpointingInProgress, Checkpointed = Value
}
private[spark] abstract class RDDCheckpointData[T: ClassTag](@transient rdd: RDD[T])
extends Serializable {
import CheckpointState._
// The checkpoint state of the associated RDD.
protected var cpState = Initialized
。。。。。。
}[ Initialized --> CheckpointingInProgress--> Checkpointed ]
这几个阶段才能被 checkpoint。
这类里面有一个枚举来标识CheckPoint的状态,第一次初始化时是Initialized。
checkpoint这个一步已经完成了,回到我们的RDD成员变量里
checkpointData这个变量指向的RDDCheckpointData的实例。
checkpoint什么时候写入数据
我们知道一个spark job运行最终会调用SparkContext的runJob方法将任务提交给Executor去执行,我们来看runJob
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}最后一行代码调用了doCheckpoint,在dagScheduler将任务提交给集群运行之后,我来看这个doCheckpoint方法
/**
* Performs the checkpointing of this RDD by saving this. It is called after a job using this RDD
* has completed (therefore the RDD has been materialized and potentially stored in memory).
* doCheckpoint() is called recursively on the parent RDDs.
*/
private[spark] def doCheckpoint(): Unit = {
RDDOperationScope.withScope(sc, "checkpoint", allowNesting = false, ignoreParent = true) {
if (!doCheckpointCalled) {
doCheckpointCalled = true
if (checkpointData.isDefined) {
if (checkpointAllMarkedAncestors) {
// TODO We can collect all the RDDs that needs to be checkpointed, and then checkpoint
// them in parallel.
// Checkpoint parents first because our lineage will be truncated after we
// checkpoint ourselves
dependencies.foreach(_.rdd.doCheckpoint())
}
checkpointData.get.checkpoint()
} else {
dependencies.foreach(_.rdd.doCheckpoint())
}
}
}
}这个是一个递归,遍历RDD依赖链条,当rdd是checkpointData不为空时,调用checkpointData的checkpoint()方法。还记得checkpointData类型是什么吗?就是RDDCheckpointData ,我们来看它的checkpoint方法,以下
/**
* Materialize this RDD and persist its content.
* This is called immediately after the first action invoked on this RDD has completed.
*/
final def checkpoint(): Unit = {
// Guard against multiple threads checkpointing the same RDD by
// atomically flipping the state of this RDDCheckpointData
RDDCheckpointData.synchronized {
if (cpState == Initialized) {
//标记当前状态为 CheckpointingInProgress
cpState = CheckpointingInProgress
} else {
return
}
}
//这里调用的是子类的 doCheckPoint()
val newRDD = doCheckpoint()
// Update our state and truncate the RDD lineage
RDDCheckpointData.synchronized {
cpRDD = Some(newRDD)
cpState = Checkpointed
rdd.markCheckpointed()
}
}这个方法开始做checkpoint操作了。
checkpoint什么时候读取数据
- 我们知道Task是spark运行任务的最小单元,当Task执行失败的时候spark会重新计算,这里Task进行计算的地方就是读取checkpoint的入口。我们可以看一下
ShuffleMapTask里的计算方法runTask,如下
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}这是spark真正调用计算方法的逻辑runTask调用 rdd.iterator() 去计算该 rdd 的 partition 的,我们来看RDD的iterator()
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but is available for implementors of custom
* subclasses of RDD.
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}这里会继续调用computeOrReadCheckpoint,我们看该方法
/**
* Compute an RDD partition or read it from a checkpoint if the RDD is checkpointing.
*/
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
if (isCheckpointedAndMaterialized) {
firstParent[T].iterator(split, context)
} else {
compute(split, context)
}
}当调用rdd.iterator()去计算该 rdd 的 partition 的时候,会调用 computeOrReadCheckpoint(split: Partition)去查看该 rdd 是否被 checkpoint 过了,如果是,就调用该 rdd 的 parent rdd 的 iterator() 也就是 CheckpointRDD.iterator(),否则直接调用该RDD的compute, 那么我们就跟进CheckpointRDD的compute
/**
* Read the content of the checkpoint file associated with the given partition.
*/
override def compute(split: Partition, context: TaskContext): Iterator[T] = {
val file = new Path(checkpointPath, ReliableCheckpointRDD.checkpointFileName(split.index))
ReliableCheckpointRDD.readCheckpointFile(file, broadcastedConf, context)
}这里就两行代码,意思是从Path上读取我们的CheckPoint数据,看一下readCheckpointFile
CheckpointRDD 负责读取文件系统上的文件,生成该 rdd 的 partition。这就解释了为什么要为调用了checkpoint的RDD 添加一个 parent CheckpointRDD的原因。
到此,整个checkpoint的流程就结束了。
参考 https://www.cnblogs.com/tongxupeng/p/10439889.html
33. 说说Spark的高可用和容错
来源:oschina
链接:https://my.oschina.net/u/4101357/blog/3420468