你好,机器作诗了解一下
文章来源:企鹅号 - 语言学午餐Ling-Lunch
还记得当年的Alpha Go吗?人工智能在围棋领域战胜了人类,我们都曾为此唏嘘不已。当时,高晓松说:“等有一天,机器做出了所有的音乐与诗歌,我们的路也会走完”。 这一天真的会到来吗?机器的“诗和远方”又会是怎样的呢?
随着人工智能领域的蓬勃发展,人们也开始探索它在文艺领域的应用。在这方面,机器作诗(Automated Poetry Generation)无疑是最受热议的话题之一。
那繁星闪烁的几天苍色
那满心的红日
看万里天使在世界
我就像梦
看那星 闪烁的几颗星
西山上的太阳
青蛙儿正在远远的浅水
她嫁了人间许多的颜色
选自微软小冰诗集《阳光失了玻璃窗》
2017年5月,微软亚洲研究院发布了由智能机器人小冰创作的第一部人工智能诗集《阳光失了玻璃窗》。这个里程碑事件也引起了计算机科学、语言学、文学等领域对人工智能与诗歌本质的大讨论。最近,在央视的《机智过人》节目中,清华大学的机器作诗系统“九歌”也得到了专业人士的赞誉。

利用九歌作诗系统所创作的藏头诗
虽然这些作诗系统让人感到惊喜、有趣,但也有许多人对人工智能创作的所谓“诗歌”抱负面态度。诗人群体大多认为这只不过是一场文字游戏:
"一个语言游戏而已。但无论输入多少句子还是写不了真诗。真诗是灵性的。这个设计者水平有限,它设计不了灵性,设计不了诗成泣鬼神这种东西。"
—— 诗人于坚评价微软小冰
尽管诗歌的本质以及评判标准还很难界定,机器作诗系统背后的语言学原理仍然非常令人好奇。人工智能系统到底是如何写出这些诗歌的呢?今天午餐君就来从计算语言学(Computational Linguistics)的角度,和大家简单聊聊机器作诗的原理。
下文约4500字,预计阅读时间为15分钟。
在聊原理之前,我们先来做个小游戏,猜猜哪首诗歌是机器所作?
第一首:
白鹭窥鱼立,
青山照水开。
夜来风不动,
明月见楼台。
第二首:
满怀风月一枝春,
未见梅花亦可人。
不为东风无此客,
世间何处是前身。
从这两首诗中,我们可以看到它们基本符合古体诗歌的结构和形式。诗中意象之间的联系也非常紧密,比如白鹭、鱼、青山和水。不仅如此,第二首诗中后两句的对仗关系也相当工整。其实这两首诗歌都是人工智能系统创作的!
这个系统来自爱丁堡大学的博士生 Xingxing Zhang 与 Mirella Lapata 教授在2014年所发表的一篇论文。它是最早的基于人工神经网络(Artificial Neural Networks)的机器作诗系统之一。近几年的机器作诗系统都或多或少地受到了此篇论文的启发,因此我们今天也主要来聊聊它。
在了解机器如何作诗之前,我们先来想想,我们人类是如何学习诗歌创作的呢?

《红楼梦》中“香菱学诗”这个青春励志的学诗故事告诉我们:首先要多读诗、读好诗,其次是需要不断练习我们的大脑,最后需要一个像林妹妹一样的老师,可以快速指出我们创作的诗歌哪里有不足。
其实,一个典型的机器学习(Machine Learning)情景也是类似的:我们需要准备好数据(data)、一个可以优化的计算模型(model)以及一个判断模型优劣的评价指标(evaluation metric)。
多读诗、读好诗 → 准备数据
大脑 → 计算模型
练习、找林妹妹指导 → 模型训练与评价
数据
数据层面上,香菱和机器所面对的情况类似:他们都需要大量阅读古人的优秀诗歌,才能掌握诗歌写作的模式(pattern),也就是我们说的“套路”。不同之处在于,作为人族少女的香菱就算再怎样地“苦志学诗,精血诚聚”,恐怕一辈子也读不完几万首诗,更别说去思考了。
然而对于机器而言,处理大量的诗歌语料库完全没有问题,尤其是在计算资源极度丰富的今天。这篇论文就采用了七万首唐宋明清的四行诗(quatrain)作为数据。
模型
人工神经网络
香菱相比机器最大的优势在于她有着世界上几乎最神奇的学习系统——人类大脑。而人工智能系统只能通过构建计算模型(建模)来模拟人类学习语言的过程。(如果模型的效果不符合正常的人类思维,就成了人工智障啦!)
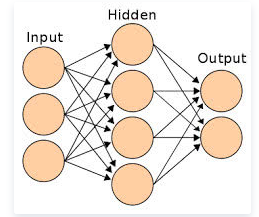
神经元、人工神经元、人工神经网络
大部分近年的主流作诗系统都基于人工神经网络(Artificial Neural Network)。所谓的人工神经网络(简称神经网络),是一种模仿生物神经系统结构与功能的计算模型。从定义看上去,人们会误以为这种计算模型和大脑一样复杂。但实际上,它只简单地模拟了神经元的激活函数,以及神经元之间的链接方式。
我们今天所要介绍的机器写诗系统主要是基于一种特殊的人工神经网络——循环神经网络(Recurrent Neural Network,RNN)。
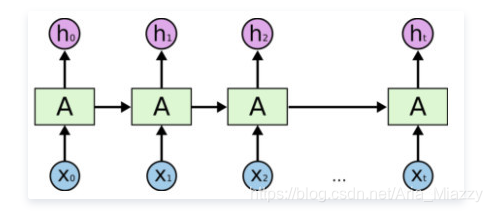
循环神经网络 RNN
人类的自然语言句子可以被天然地看作是一种字(或词)所组成的序列。无论我们是在阅读还是在写作,大多都是以一种线性、序列化的方式来去理解或者生成文本的。所以,自然语言文本常常被当做是一种序列型数据(Sequential Data)来被处理和计算,而RNN则是专门对序列型数据建模的网络结构。
机器写诗模型的整体流程
生成候选首句集合
人类写诗需要先定下主题,机器写诗自然也需要一些输入才能进行。在常见的写诗系统中,起点往往是用户输入的几个关键词,比如 {“春”、“琵琶”,“醉”}。当然,不同的写诗系统有着不同的输入:藏头诗写作系统则需要输入每句的第一个字,看图作诗的模型则需要输入一幅图片。不过,不同的输入对模型的核心部分影响不大。我们这里讨论最常见的情况,输入为关键词集合。
万事开头难,一首诗的第一句往往决定了整首诗的主题、氛围和气魄。拿到关键词之后,为了写出第一句,模型首先需要扩展主题词。
这里作者利用了从《诗学含英》(清 刘文蔚, 1735)里手工构建的“诗意词典”。这个词典有1016个意群,每个意群由一个关键词作为标记。意群中其他词则是与标记相关的字或词组。比如“春”所标记的意群里,就会包含有“暖风”,“莺”这种诗句中常见的词汇。
有了诗意词典,产生第一句诗看起来就没那么难了。我们要做的无非在找到和每个关键词所相关的所有字和词组,然后用它们拼凑出第一句诗。
继续利用这个输入作为例子。我们可以从词典中找到每个词所对应的意群,然后将这三个意群中的所有词拿出来组成一个新的集合:{莺,暖风,迟日,醉,百啭,莺声}。这样就完成了主题词的扩展。
如果我们想作的是五言诗,那么就可以用程序在这个集合中找出所有长度为5的序列。利用格律要求(比如平仄规则)去筛选这些五字句后,就生成了许多满足条件的候选句,比如“暖风/迟日/醉”和“莺/百啭/莺声”。
挑选最优首句
我们接着从中挑选一个最通顺、最有诗意的一个候选作为首句。对比这两句,我们人类通过阅读可以很快发现“暖风迟日醉”比 “莺百啭莺声”要更为通顺而富有诗意。那么问题来了,机器该如何判断哪句诗的更通顺、更有诗意呢?
在计算语言学里,判断一句话的通顺程度,一般是通过构建统计语言模型(statistical language model, 简称语言模型) 来完成的。简单来说,语言模型是在某个语料库上计算得到的统计模型。它能够对任意给定的一个句子,计算出这句话在这个语料库中出现概率。概率越大,就意味着这句话越符合这个语料库的特征,自然也就越“通顺”。在写诗的例子里,语料库是诗句组成的,这里的“通顺”自然也就带上了“诗意”的效果。
RNN可以帮助我们快速有效地对诗歌语料库建立语言模型。利用这个语言模型,机器便可以计算所有候选首句的概率。我们可以假设“暖风迟日醉”和“莺百啭莺声”存在的概率是这样计算得到的:
P(暖风迟日醉) = P(暖) * P(风|暖) * P(迟|暖风) * P(日|暖风迟) * P(醉|暖风迟日)
P(莺百啭莺声) = P(莺) * P(百|莺) * P(啭|莺百) *P(莺|莺百啭)* P(声|莺百啭莺)
其中,P(X) 表示X这个字在整个语料库中出现的概率,P(Z|XY) 表示在前两个字是XY的情况下,第三个字是 Z 的条件概率。
我们可以发现第一句诗的几个局部概率都应该很高,比如“暖风迟”,“暖风迟日”,听起来都很顺。而在第二句中,虽然“莺百啭”还算通顺,但是“莺百啭莺”存在的概率就会非常低。这主要因为,诗歌语料库中一句诗中较少会出现两个相同的字,而且“莺”接在“啭”的后面的情况也肯定都不如“日”接在“迟”后面的概率。
按照这种计算的方法,我们可以对之前产生的每一个五言句打分。选择分数最高的,也就是最通顺的一句作为机器作诗的第一句话。
第一句诗产生之后,我们的问题就简化成了:如何根据已经写好的前n句诗,来产生第n+1句诗,直到全诗完成?
后续诗句的生成
我们人再写诗的时候,写某个字时一定会不断重复读前面已经写过的句子,从而才能使整首诗更加连贯、自然。我们构建的计算模型也应该有这样的机制。
假设我们的模型正在构思如何写第3句的第4个字(模型的输出),那么我们这个阶段的模型所接受的输入便是“第1句 + 第2句 + 第3句的前3个字”。
一种经典的计算语言学的建模方式是编码器-解码器架构 (Encoder-Decoder Architecture)。这种建模方式将核心问题化归为两步:
构建编码器,将输入的信息综合编码成一个向量;
构建解码器,对之前编码后的向量进行解码,成为我们需要的输出。
这种框架其实暗合了我们人脑在创作时的一般逻辑:首先理解(encoding)已创作的部分,得到一个全局的观感,然后在此基础上继续创作(decoding)。
注意到我们已创作的部分有些是整句(第1句和第2句),有些则是半句(第3句前3个字),编码器对于它们应该做不同的处理:对于完整的诗句,论文作者利用了卷积神经网络(Convolutional Neural Networks, CNN)来编码; 而未完成的半句诗,则利用了更合适的RNN的结构来编码。
等等.....CNN是个什么东西?为什么用它来编码完整的诗句呢?之前不是说RNN更适合自然语言吗?
CNN和RNN一样,都是一种主流的基础神经网络结构。它和RNN的主要区别在于处理数据的模式上:CNN着眼于固定的局部结构,利用层层递进的方式编码全局信息;而RNN着眼于序列结构,以线性方式编码信息。
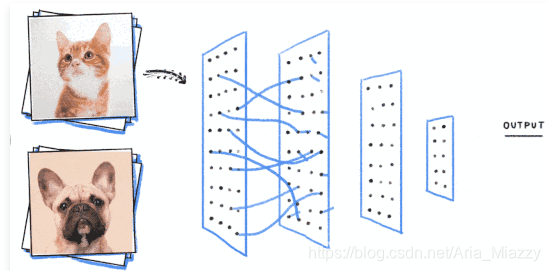
基于CNN的猫狗图片分类器
CNN广泛应用在计算机视觉领域, 还有像围棋棋盘这样的数据模式,而RNN主要应用在计算语言学领域。想象一下我们人在理解图片/棋盘时,往往是一块一块看到图片,然后拼凑成全局的样貌;而理解文本/语音则常常是一字一句地顺着理解下去。
(视觉和语言是我们人脑感知世界的两大重要能力,这大概也说明了为什么CNN和RNN是现在人工智能研究地最火热的两大神经网络结构。)
午餐君好像有点扯远了!到底为什么这里我们用CNN而非RNN来处理完整的诗句呢?一个重要的原因就是古诗所特有的结构蕴含着丰富的信息。比如一个完整的诗句有着固定的长度,句读位置有一定规律;而一个不完整的诗句则没有固定的长度。
基于CNN对整句诗进行编码
其实仔细想想,一首完整的中文古诗,是不是也有着视觉上的美感呢?我们之前说CNN适合视觉理解,在此处也有所体现!当然,如果是现代诗的话,CNN的作用就相对小一些了。
最后总编码器汇总CNN和RNN分别编码的信息,再送到解码器,从而算出我们所需要的“第3句的第4个字”。以此类推,我们的整首古诗就可以完成啦!
模型训练与评测
我们知道了模型正向的运作方式,可是如何利用我们收集到的古人诗句去训练这个模型,让它能聪明起来呢?俗话说得好,熟读唐诗三百首,不会作(吟)诗也会吟。 所以,我们的训练模型的目标也就可以简化成:期望这个模型能够背诵7万首诗,做到给出上句,能背出下句的程度来。
小学时,如果我们背不出下一句诗然后随便乱编一个的时候,老师会罚我们站打我们手板。然而,如果模型不记得下一句时能够凭着它的"语感"编出来了一句还不错的诗句,这就是胜利呀!
我们想要模型掌握的就是这种语感,这种语感的本身就决定了作诗能力的高下!这就好比张无忌同学在学太极剑法时,张三丰说他完全忘记了才是学会了。

那么怎么来评判模型编的新诗句,好还是不好呢?如果不好,如何改进呢?
聪明的读者可能已经想到了,请林妹妹来指导呀!也就是找到一个数字化的评价指标,每次机器写完诗,拿这个指标去衡量模型写的诗有多好或者有多坏,然后再以此去改善模型。
然而,假如香菱每写一首诗都让林妹妹来给她评价一番,做指导,这似乎不太现实。想想林妹妹娇弱的身体,还要考虑人情债。问多了,林也就烦了。也就是说,好的评价指标(林妹妹)评价一次可能很费计算资源。

林妹妹:你咋又来问我了?(嫌弃脸)
既然香菱不能每写一首诗都让林妹妹去看,那怎么办呢?我们只能以一种高效的方式来得到近似的评测结果。
具体来说,我们假设让香菱去请教林妹妹的贴身丫鬟紫鹃。紫鹃何以担此重任?一是她和林妹妹日夜相处,也耳濡目染了林妹妹的评价体系,虽然也许不够精准,但是也不会偏差太大(近似);二是她地位不高,可以频繁请教(高效)。
紫鹃:喵喵喵???
所以利用数据训练模型时,我们不会频繁利用评测指标来优化模型,而是找到一个间接的方式——损失函数 (loss function)。损失函数一般要求计算复杂度低,可以和模型的参数更好的融合,从而高效地优化模型的参数(parameters/weights)。
而林妹妹这种高级的评价指标,适合我们用来调整整个模型的大局框架,比如是否使用CNN来编码完整诗歌这种比较重要的、宏观的改善。紫鹃这种损失函数呢,就来帮我们改改字,提点微观上的建议。
实际中,我们就算想找林妹妹这样的人来评价一个写诗系统的能力,也是非常困难的。论文的作者先是使用了文本生成领域最常见的自动化指标 (比如Perplexity 和 BLEU)。
当然,最理想的评测方式是把机器的诗歌和真正的古诗混在一起,让人类去分辨,或在不同维度上打分。如果连人们分辨不出哪些是真的古诗,或者给机器做的诗歌打分更高的话,我们就可以相对有自信地认为这个机器作诗系统比较完善啦。
机器写诗虽然看似是一个玄妙的过程,但是背后的原理却远没有那么神秘。午餐君期待未来的机器写诗系统会融入更加多元化的信息,比如视频、音频、社交网络结构等等,与推荐系统相结合,给人类生活带来更多的趣味。
打包带走你的语言学午餐:
大多数人工智能机器作诗系统是基于人工神经网络模型的,与深度学习(Deep Learning)等领域密切相关。
文中提到的香菱学诗的过程是一个较为完整和典型的机器学习的例子,她利用了古人的诗集(数据)和自己的大脑(计算模型),还求助了紫鹃和林妹妹(模型的训练与评测)。
衡量一句话的流畅程度,可以用到(统计)语言模型。
RNN与CNN是两大主流的基础神经网络。
损失函数的存在主要是为了更加高效地评价并优化模型。
P.S. 小编希望未来继续和大家聊有关计算语言学的主题,小吃货们有什么建议?
最后分享给大家一首关于文字与语言的小诗《来自1979年3月》,作者为2011年诺贝尔文学奖得主托马斯·特兰斯特罗默。
From March 1979
Weary of all who come with words,
words but no language.
I make my way to the snow-covered island.
The untamed has no words.
The unwritten pages spread out on every side!
I come upon the tracks of deer in the snow.
Language but no words.
By Tomas Tranströmer
Translated from the Swedish by Robin Fulton
References
Zhang, Xingxing and Mirella Lapata. “Chinese PoetryGeneration with Recurrent Neural Networks.” EMNLP (2014).
Yan, Rui et al. “Chinese Couplet Generation with NeuralNetwork Structures.” ACL (2016).
Oliveira, Hugo Gonçalo. “A Survey on Intelligent PoetryGeneration: Languages, Features, Techniques, Reutilisation and Evaluation.”(2017).
Yang, Xiaopeng et al. “Generating Thematic Chinese Poetrywith Conditional Variational Autoencoder.” CoRR abs/1711.07632 (2017)
Mikolov, Tomas et al. “Recurrent neural network basedlanguage model.” INTERSPEECH (2010).
He, Jing et al. “Generating Chinese Classical Poems withStatistical Machine Translation Models.” AAAI (2012).
Smedt, Tom De. “The INLG 2017 Workshop on ComputationalCreativity in Natural Language Generation.” (2017).
林禹臣 林语尘
- 发表于: 2018-02-02
- 原文链接:http://kuaibao.qq.com/s/20180202B0FUI300?refer=cp_1026
- 腾讯「云+社区」是腾讯内容开放平台帐号(企鹅号)传播渠道之一,根据《腾讯内容开放平台服务协议》转载发布内容。
来源:CSDN
作者:YumWisdom
链接:https://blog.csdn.net/Aria_Miazzy/article/details/104805883