今天这篇文章主要给大家分享基于OSS的增量上云到RDS SQL Server的这样一个功能。这个功能主要适用于以下三个场景:
一、用户希望基于备份文件物理迁移上云RDS SQL Server,而不是逻辑迁移。物理迁移是指基于文件的迁移;逻辑迁移是指将数据生成DML语句映射到RDS SQL Server上。
二、用户希望迁移上云RDS SQL Server后数据库和用户线下的数据库100%的保持一致。这句话可以这样理解,如果用户使用的是逻辑迁移,那么我们是无法做到100%保持一致的。比如用户生成的DML语句插入到RDS SQL Server上来以后,可能会导致索引碎片率和统计信息等和用户的线下数据库不同,这样一来用户上云以后的应用可能会有一些性能问题。
三、用户的业务对停机时间非常敏感,迁移到RDS SQL Server的过程,需要控制在分钟级别。
以上就是三个比较典型的使用增量上云的场景。
下面我们来看一下增量上云的具体流程。
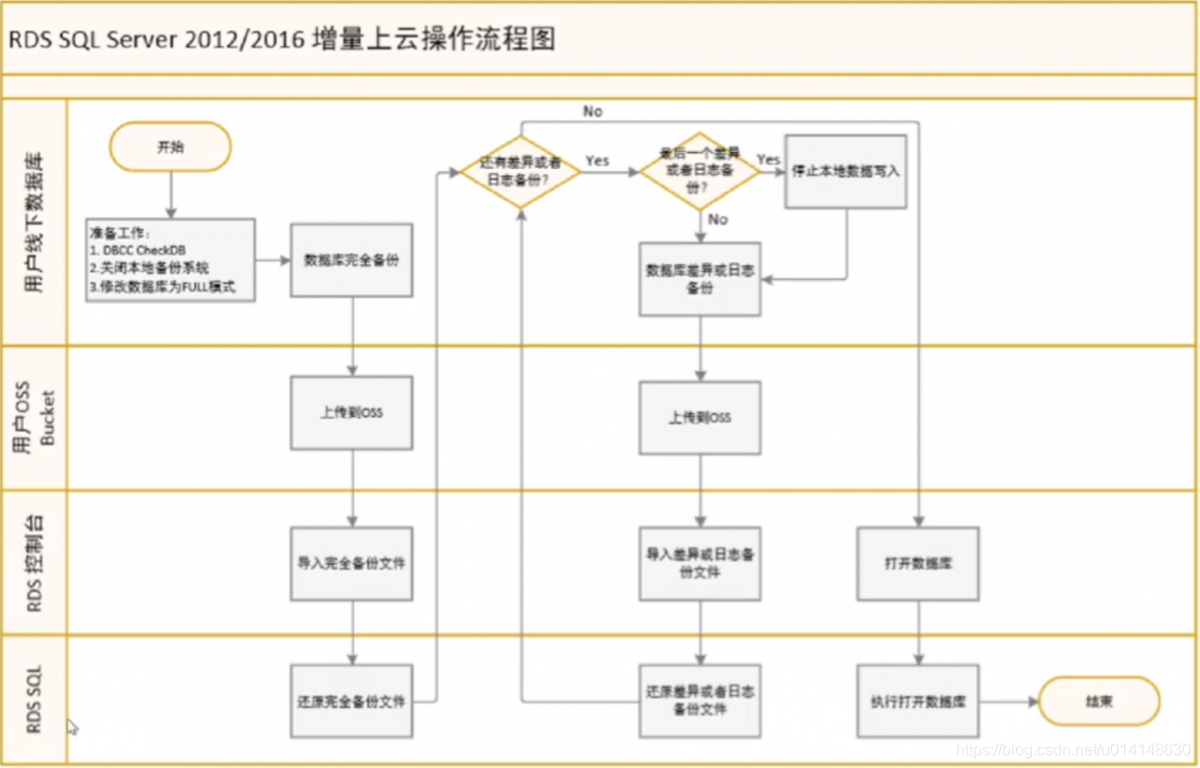
上图是用户把自己的线下数据库增量上云到RDS SQL Server的流程图。从这个图中大家可以看到它实际上包含了四个方面:第一个方面是用户的线下数据库,这个是用户需要参与进来的;第二个方面是用户的OSS Bucket;第三个方面是RDS控制台;第四个就是RDS SQL Server在背后做的一些事情。
首先我们看这个流程图最开始的部分,用户需要做一些准备工作。比如,用户需要先做一个DBCC Check DB来保证用户的数据库没有数据一致性的问题;第二个准备工作是,用户需要把自己的本地备份系统关闭。如果本地备份系统没有关闭,备份系统可能会自动做一些备份操作,可能会导致用户导入到RDS的这些备份文件不全,从而导致上云失败;第三个准备工作是,用户需要把数据库修改为FULL模式,这个非常重要。
这些准备工作完成以后,用户需要对自己的线下数据库做一个完全备份,就是一个Full Backup。完全备份做完之后就上传到OSS。上传完之后,用户通过RDS控制台生成一个基于这个完全备份文件的任务流。任务流生成之后,RDS SQL Server就会在背后做一些还原操作。这个动作做完成以后,RDS SQL Server会继续等待后续的备份文件,例如差异备份或者是日志备份,如果有就可以继续上传,上传最后一个差异文件前一定要停止本地数据的写入,这样才能保证本地数据库的数据和RDS上的数据是一致的,完成以后用户就可以打开数据库访问了;如果没有差异备份或者是日志备份,用户就可以直接通过RDS控制台打开数据库了。打开以后,用户就可以访问了。到这里,整个流程就结束了。
从分析这个流程图我们可以看出,只有在上传最后一个差异文件之前停止了数据写入。也就是说在整个用户上云的过程中,只会在停止数据写入以后到最后一个日志或是差异备份文件上传完成之前的这段时间,用户的应用是不可用的。那么我们就可以通过控制最后一个差异或者日志备份文件的大小来控制停机时间。比如,如果这个文件大小在500M左右的话,那么整个上云的流程中,应用的停机时间就会非常短,可以控制到分钟级别。
更多参阅阿里云数据库文档
来源:CSDN
作者:星速云
链接:https://blog.csdn.net/wx_15323880413/article/details/104738230