伪共享指的是多线程在对不同变量进行修改操作时,如果变量位于同一个缓存行,当多线程竞争缓存行所有权时,每个核都同时对缓存行进行修改,缓存子系统将会使其他核的缓存行失效导致cache miss,最后升级到L3缓存进行修改,最后大大影响程序的执行效率,如果竞争的核不在同一个cpu插槽即不共享L3缓存,那就会去内存中进行修改,这样引起的问题就是伪共享问题。
参考资料:
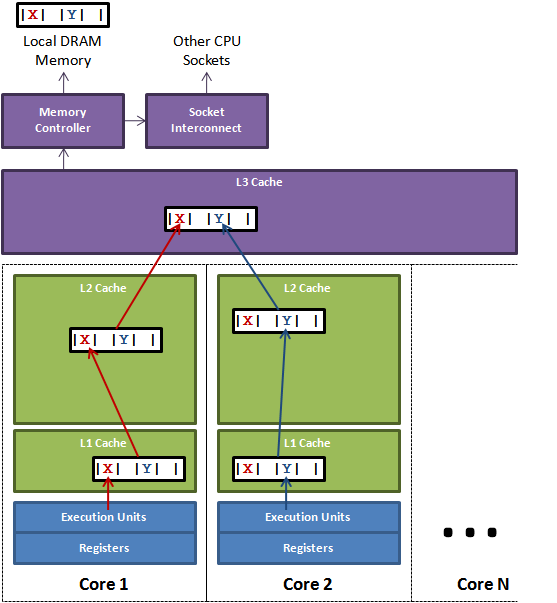
图1
图1说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
对于HotSpot JVM,所有对象都有两个字长的对象头。第一个字是由24位哈希码和8位标志位(如锁的状态或作为锁对象)组成的Mark Word。第二个字是对象所属类的引用。如果是数组对象还需要一个额外的字来存储数组的长度。每个对象的起始地址都对齐于8字节以提高性能。因此当封装对象的时候为了高效率,对象字段声明的顺序会被重排序成下列基于字节大小的顺序:
- doubles (8) 和 longs (8)
- ints (4) 和 floats (4)
- shorts (2) 和 chars (2)
- booleans (1) 和 bytes (1)
- references (4/8)
- <子类字段重复上述顺序>
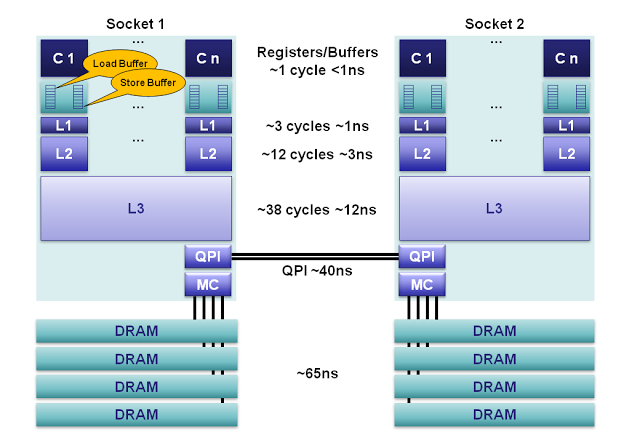
来源:oschina
链接:https://my.oschina.net/u/914290/blog/798974