Dubbo(2)
- 第一层:service 层,接口层,给服务提供者和消费者来实现的
该层是与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现。
- 第二层:config 层,配置层,主要是对 dubbo 进行各种配置的
配置层(Config):对外配置接口,以ServiceConfig和ReferenceConfig为中心,可以直接new配置类,也可以通过spring解析配置生成配置类。
- 第三层:proxy 层,服务代理层,无论是 consumer 还是 provider,dubbo 都会给你生成代理,代理之间进行网络通信
服务代理层(Proxy):服务接口透明代理,生成服务的客户端Stub和服务器端Skeleton,以ServiceProxy为中心,扩展接口为ProxyFactory。
- 第四层:registry 层,服务注册层,负责服务的注册与发现
服务注册层(Registry):封装服务地址的注册与发现,以服务URL为中心,扩展接口为RegistryFactory、Registry和RegistryService。可能没有服务注册中心,此时服务提供方直接暴露服务。
- 第五层:cluster 层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
集群层(Cluster):封装多个提供者的路由及负载均衡,并桥接注册中心,以Invoker为中心,扩展接口为Cluster、 Directory、Router和LoadBalance。将多个服务提供方组合为一个服务提供方,实现对服务消费方来透明,只需要与一个服务提供方进 行交互。
- 第六层:monitor 层,监控层,对 rpc 接口的调用次数和调用时间进行监控
监控层(Monitor):RPC调用次数和调用时间监控,以Statistics为中心,扩展接口为MonitorFactory、Monitor和MonitorService。
- 第七层:protocal 层,远程调用层,封装 rpc 调用
远程调用层(Protocol):封将RPC调用,以Invocation和Result为中心,扩展接口为Protocol、Invoker和 Exporter。Protocol是服务域,它是Invoker暴露和引用的主功能入口,它负责Invoker的生命周期管理。Invoker是实体 域,它是Dubbo的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起invoke调用,它有可能是一个本地的实现,也可能是 一个远程的实现,也可能一个集群实现。
- 第八层:exchange 层,信息交换层,封装请求响应模式,同步转异步
信息交换层(Exchange):封装请求响应模式,同步转异步,以Request和Response为中心,扩展接口为Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer。
- 第九层:transport 层,网络传输层,抽象 mina 和 netty 为统一接口
网络传输层(Transport):抽象mina和netty为统一接口,以Message为中心,扩展接口为Channel、Transporter、Client、Server和Codec。
- 第十层:serialize 层,数据序列化层
数据序列化层(Serialize):可复用的一些工具,扩展接口为Serialization、 ObjectInput、ObjectOutput和ThreadPool。
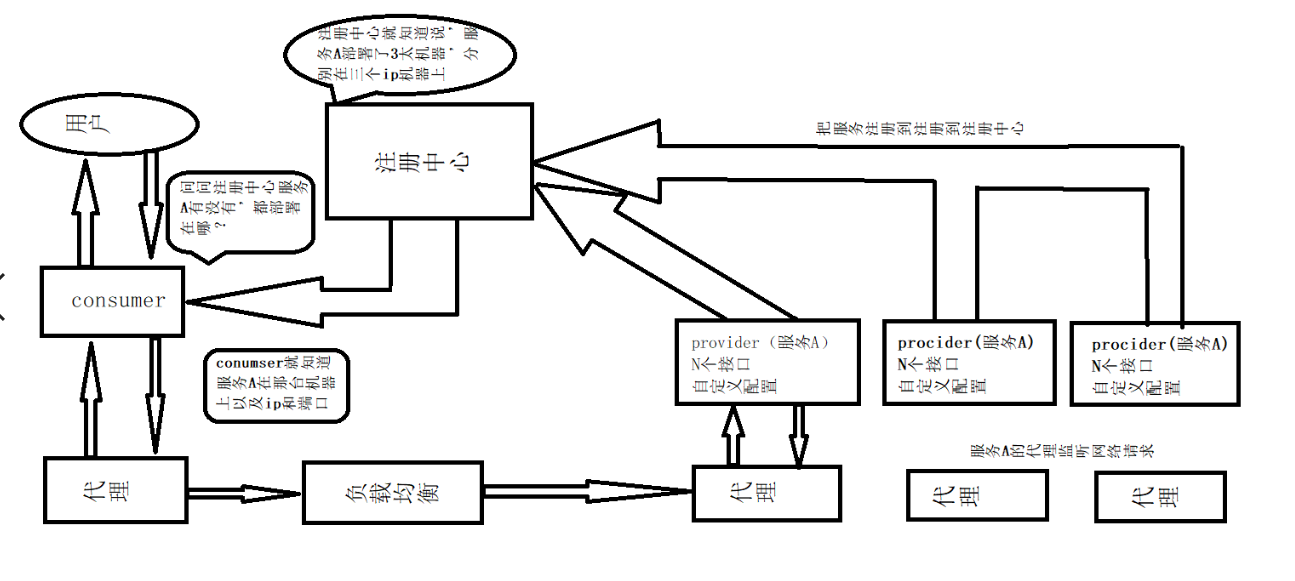
- 第一步:provider 向注册中心去注册
- 第二步:consumer 从注册中心订阅服务,注册中心会通知 consumer 注册好的服务
- 第三步:consumer 调用 provider
- 第四步:consumer 和 provider 都异步通知监控中心
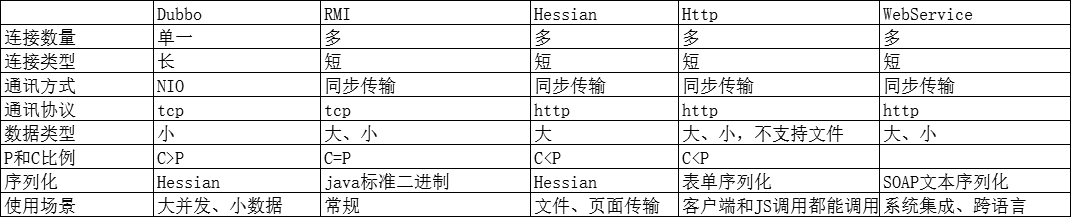
3、dubbo 支持哪些协议 每个协议之间有什么特点应用场景笔记录音
Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
适用场景:常规远程服务方法调用
rmi协议:
Hessian协议用于集成Hessian的服务,Hessian底层采用Http通讯,采用Servlet暴露服务,Dubbo缺省内嵌Jetty作为服务器实现 。 走 hessian 序列化协议,多个短连接,适用于提供者数量比消费者数量还多的情况,适用于文件的传输,一般较少用。
适用范围:传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。
适用场景:页面传输,文件传输,或与原生hessian服务互操 作
webservice:
基于WebService的远程调用协议,集成CXF实现,提供和原生WebService的互操作。多个短连接,基于HTTP传输,同步传输,适用系统集成和跨语言调用
Thrift :
Thrift是Facebook捐给Apache的一个RPC框架,当前 dubbo 支持的 thrift 协议是对 thrift 原生协议的扩展,在原生协议的基础上添加了一些额外的头信息,比如service name,magic number等。
3、dubbo 负载均衡策略和集群容错策略特点场景 笔记画图、录音
负载均衡策略
①random loadbalance 策略
默认情况下,dubbo是random loadbalance 随机调用实现负载均衡,按权重设置随机概率。在一个截面上碰撞的概率高,但是调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。可以对provider不同实例设置不同的权重,会按照权重来进行负载均衡,权重越大分配的流量越高,一般就用这个默认的就可以了。
②roundrobin loadbalance策略
轮循,按公约后的权重设置轮循比率。这个策略默认会将请求均匀的分布到各个provider上面,但是如果各个机器的性能不一样,很容易到性能差的机器负载过高。存在慢的提供者累积请求问题,比如:第二台机器很慢,但是没有挂,当请求第二台机器的时候就会卡在那,久而久之,所有的请求都卡在了第二台机器上。
③leastactive loadbalance策略
最少活跃调用数,相同活跃数的随机。活跃数值调用前后计数差。使慢的提供者收到更少的请求,因为越慢的提供者调用前后的技术差会越大。 自动感知机器性能,如果某个机器性能差,那么这个机器接收到的请求就会越少。接收到的请求越少,机器就越不活跃,那么不活跃的机器就会接到更少的请求。
④consistanthash loadbalance策略
一致性hash算法,相同参数的请求一定发送到同一个provider上面去,provider挂掉的时候,会基于虚拟节点均匀分配剩余的请求,抖动不会太大。就是平摊到其他提供者,不会引起剧烈变动。
集群容错策略
①failover cluster策略
调用一个provider失败,自动切换到其他的provider上面去调用,默认策略,常见于读操作。
②failfast cluster策略
一次调用provider失败就立即失败,常见于写操作。
③failsafe cluster策略
出现异常时忽略掉,常见于不重要的接口调用,比如日志记录。
④faliback cluster策略
失败后后台自动记录请求,然后定时重发,比较适合写消息队列这种操作。
⑤forking cluster策略
并行调用多个provider,只要有一个成功就立即返回。
⑥broadcast cluster策略
逐个调用所有的provider。
来源:oschina
链接:https://my.oschina.net/u/4442945/blog/3163668