数据分类
结构化数据:指具有固定格式或有限长度的数据(例如数据库,元数据等)
非结构化数据:指不定长或无固定格式的数据(例如邮件,word文档等)
非结构化数据查询方法
- 顺序扫描法
从头到尾进行扫描,找到匹配的文件 - 全文检索
先建立索引,然后对索引进行搜索
Lucene实现全文检索
索引和搜索流程图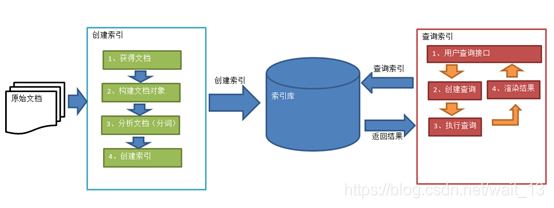
创建索引
- 获得原始文档
- 创建文档对象
我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容) - 分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。 - 创建索引(倒排索引结构)
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)
分析器的使用
Lucene 自带分词器
- StandardAnalyzer:单字分词
- SmartChineseAnalyzer:对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理
- IKAnalyzer
IKAnalyzer 的使用
- 把jar包添加到工程中
- 把配置文件和扩展词典和停用词词典添加到classpath下

//1.创建一个Directory对象,指定索引库保存保存的位置
/*把索引库保存在内存中
Directory directory = new RAMDirectory();
*/
//把索引库保存在磁盘
Directory directory = FSDirectory.open(new File("E:\\Java_Study\\Lucene\\index").toPath());
//2.基于Directory对象,创建一个IndexWriter对象
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory,config);
查询索引
- 创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法 - 执行查询
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
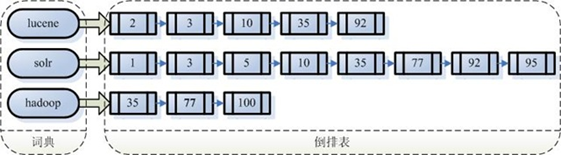
索引库的维护
索引库的添加
Field 域的属性
- 是否分析:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
- 是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。
- 是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取
| Field类 | 数据类型 | Analyzed是否分析 | Indexed是否索引 | Stored是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等)是否存储在文档中用Store.YES或Store.NO决定 |
| LongPoint(String name, long… point) | Long型 | Y | Y | N | 可以使用LongPoint、IntPoint等类型存储数值类型的数据。让数值类型可以进行索引。但是不能存储数据,如果想存储数据还需要使用StoredField。 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
来源:CSDN
作者:LEEWLD
链接:https://blog.csdn.net/wait_13/article/details/104215534