1.什么是NoSql:
NoSql(Not Only SQL),意即“不仅仅是SQL”,指的是非关系型数据库。随着互联网Web2.0网站的兴起,传统的关系型数据库在应付Web2.0网站,特别是超大规模和高并发的SNS类型的Web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型数据库则由于其本身的特点得到了非常迅速的发展。非关系型数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。例如谷歌或Facebook每天为他们的用户收集万亿比特的数据。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
NoSql的好处:
易扩展:
NoSql数据库种类繁多,但是有一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
高性能:
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对Web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSql在这个层面上来说就要性能高很多了。
多样灵活的数据模型:
NoSql无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
传统RDBMS(关系数据库) VS NOSql(非关系数据库):
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSql
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
2.为什么使用NoSql?
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
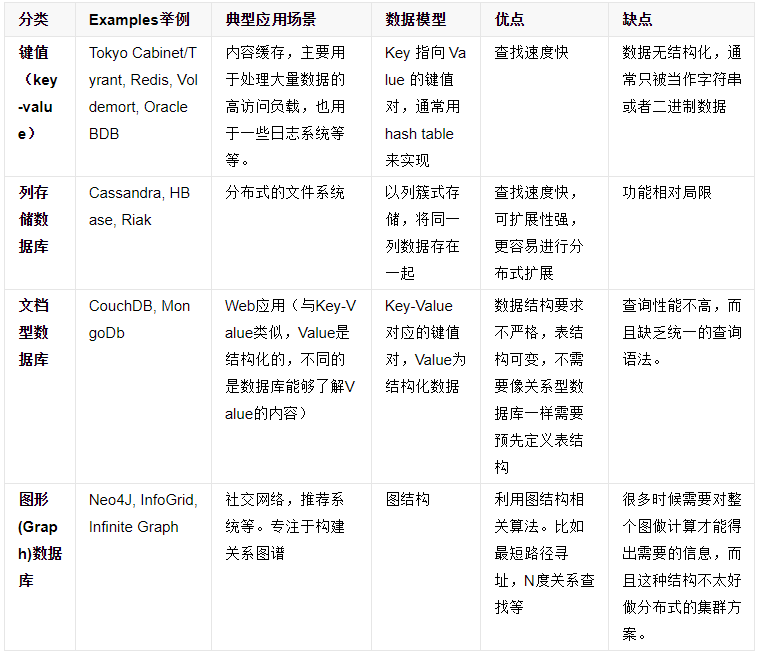
3.NoSql数据库的四大分类:
1.KV键值:典型介绍:
新浪:BerkeleyDB+redis
美团:redis+tair
阿里、百度:memcache+redis
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB。
2.文档型数据库(BSON格式比较多):典型介绍
CouchDB
MongoDB
MongoDB是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 Web 应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
3.列存储数据库:
Cassandra, HBase 分布式文件系统。
4.图关系数据库:
它不是放图形的,放的是关系比如:朋友圈社交网络、广告推荐系统,社交网络,推荐系统等。专注于构建关系图谱Neo4J, InfoGrid。
4.NoSql数据库的四大分类表格分析:
5.在分布式数据库中CAP原理CAP:
关系数据库的ACID:
关系型数据库遵循ACID规则,事务在英文中是Transaction,和现实世界中的交易很类似,它有如下四个特性:
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
3、I (Isolation) 隔离性
所谓的隔离性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。比如现有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
非关系数据库的CAP:
1、C(Consistency)(强一致性)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)。
2、A(Availability)(可用性)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)。
3、P(Partition tolerance)(分区容错性)
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。
而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。
所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
来源:https://www.cnblogs.com/lazy-blog/p/redis.html