流量控制
漏桶算法:
主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。它模拟的是一个漏水的桶,所有外部的水都先放进这个水桶,而这个桶以匀速往外均匀漏水,如果水桶满了,外部的水就不能再往桶里倒了。
这里你可以把这些外部的水想象成原始的请求,桶里漏出的水就是被算法平滑过后的请求。从这里也可以看出来,漏桶算法可以比较好地控制流量的访问速度。
令牌桶算法
控制的是一个时间窗口内通过的数据量。大概实现如下:
1.每1/r秒往桶里放入一个令牌,r是用户配置的平均发送速率(也就是每秒会有r个令牌放入)
2.桶里最多可以放入b个令牌,如果桶满了,新放入的令牌会被丢弃
3.如果来了n个请求,会从桶里消耗n个令牌。
4、如果桶里可用令牌数小于n,那么这n个请求会被丢弃或者等待新的令牌放入。
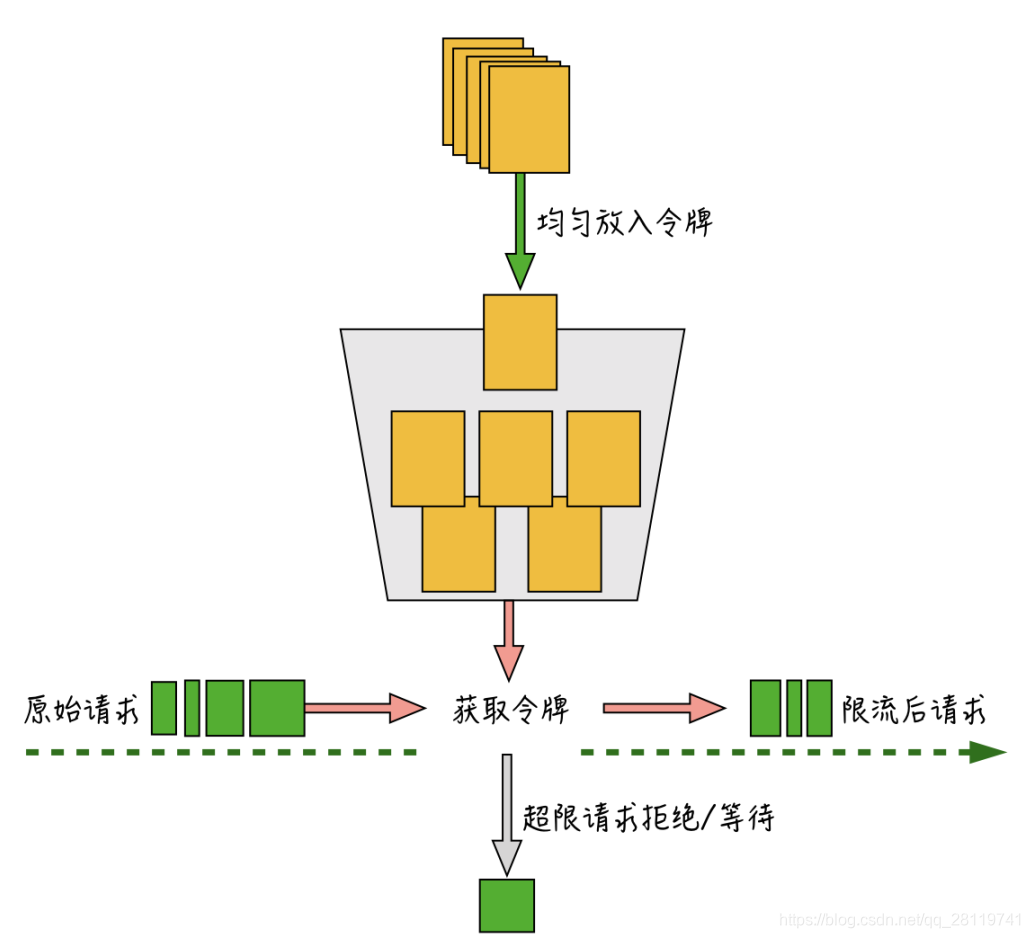
算法按一定速度均匀往桶里放入令牌,原始请求进入后,根据请求量从令牌桶里取出需要的令牌数,如果令牌数不够,会直接抛弃掉超限的请求或者进行等待,能成功获取到令牌的请求才会进入到后端服务器。
与漏桶算法精确控制速率不太一样的是,由于令牌桶的桶本身具备一定的容量,可以允许一次把桶里的令牌全都取出,因此,令牌桶算法在限制请求的平均速率的同时,还允许一定程度的突发流量。
全局流控
对于单机瓶颈的问题,通过单机版的流控算法和组件就能很好地实现单机保护。但在分布式服务的场景下,很多时候的瓶颈点在于全局的资源或者依赖,这种情况就需要分布式的全局流控来对整体业务进行保护。
业界比较通用的全局流控方案,一般是通过中央式的资源(如:redis,nginx)配合脚本来实现全局的计数器,或者实现更为复杂的漏桶算法和令牌算法,比如可以通过redis的INCR命令配合Lua实现一个限制QPS的流控组件

一个需要注意的细节是:在每次创建完对应的限流key后,你需要设置一个过期的时间。整个操作是原子的,这样就能避免分布式操作时设置过期时间失败,导致限流的key一直无法重置,从而使限流功能不可用。
此外,在实现全局流控时还有两个问题需要注意:一个是流控的粒度问题,另一个是流控依赖资源存在瓶颈的问题
细粒度控制
举个例子:在限制QPS的时候,流控粒度太粗,没有把QPS均匀分摊到每个毫秒里,而且边界处理时不够平滑,比如上一秒的最后一个毫秒和下一秒的第一个毫秒都出现了最大流量,就会导致两个毫秒内的QPS翻倍
一个简单的处理方式是把一秒分成若干个N毫秒的桶,通过滑动窗口的方式,将流控粒度细化到N毫秒,并且每次都是基于滑动窗口来统计QPS,这样也能避免边界处理时不平滑的问题。
流控依赖资源瓶颈
全局流控实现中可能会出现的另一个问题是:有时入口流量太大,导致实现流控的资源出现访问瓶颈,反而影响了正常业务的可用性。
针对这种情况,我们可以通过 本地批量预取 的方式来降低对资源的压力
所谓的本地批量预取,是指让使用限流服务的业务进程,每次从远程资源预取多个令牌在本地缓存,处理限流逻辑时先从本地缓存消耗令牌,本地消费完再触发从远程资源获取到本地缓存,如果远程获取资源时配额已经不够了,本次请求就会被抛弃
但是有一点需要注意,本地预读可能会导致一定范围的限流误差,比如:上一秒预取的10个令牌,在实际业务中下一秒才用到,这样会导致下一秒业务实际的请求量会多一些,因此本地预取对于需要精准控制访问量的场景来说可能不是特别适合。
自动熔断机制
针对突发流量,除了扩容和流控外,还有一个能有效地保护系统整体可用性的手段就是熔断机制

API 1 和 API 2一起关联部署,而且共同依赖多个依赖服务A,B,C。如果此时API 1依赖的服务B由于资源或者网络等原因造成接口变慢,就会导致和API 1一起关联部署的API 2也出现整体性能被拖累变慢的情况,继而导致依赖API 1和API 2的其他上层的服务也级联地性能变差,最终可能导致系统整体性能的雪崩。
虽然服务间的调用能够通过超时控制来降低被影响的程序,但在狠多情况下,单纯依赖超时控制很难避免依赖服务性能恶化的问题。这种情况下,需要能快速熔断对这些性能出现问题的依赖调用。
一种常见的方式是手动通过开关来进行依赖的降级,微博的很多场景和业务都有用到开关来实现业务或者资源依赖的降级。
另一种更智能的方式是自动熔断机制。自动熔断机制主要是通过持续收集被依赖服务或者资源的访问数据和性能指标,当性能出现一定程度的恶化或者失败量达到某个阈值时,会自动触发熔断,让当前依赖快速失败,并降级到其他备用依赖,或者暂存到其他地方便于后续重试恢复。在熔断过程中,再通过不停探测被依赖服务或者资源是否恢复,来判断是否自动关闭熔断,恢复业务。
奈飞的hystrix,以及目前社区很火热的Resilience4j
来源:CSDN
作者:小卒曹阿瞒
链接:https://blog.csdn.net/qq_28119741/article/details/103948489