Hadoop概述
Hadoop项目是Apache的顶级项目
Hadoop项目是以可靠、可扩展和分布式计算为目的发展而来的软件
大数据特点
数据容量大:TB--PB
数据类型多:各种非结构化数据。
商业价值高:客户群体细分,提供定制化服务
处理速度快:分布式存储计算,提高效率
Hadoop核心组件
主要作用:存储和计算
核心组件:
hadoop Common: 一组分布式文件系统通用的I/O的组件与接口。(序列化、java RPC 和持计划数据结构)
HDFS:Hadoop的分布式文件系统
Hadoop MapReduce:分布式计算框架
可以离线分布式计算,多台机器同时计算其中的一部分数据,将计算结果汇总。得到计算结果。可扩展
Hadoop Yarn:(分布式的资源管理器)
MapReduce任务运行在yarn上。yarn提供资源
Hadoop的框架演变
Hadoop1.0的MR:将资源管理和任务调度、计算功能放在一起、扩展性差,不支持多计算框架
Hadoop2.0的MR:将资源管理和任务调度分开,提高扩展性,支持多计算框架
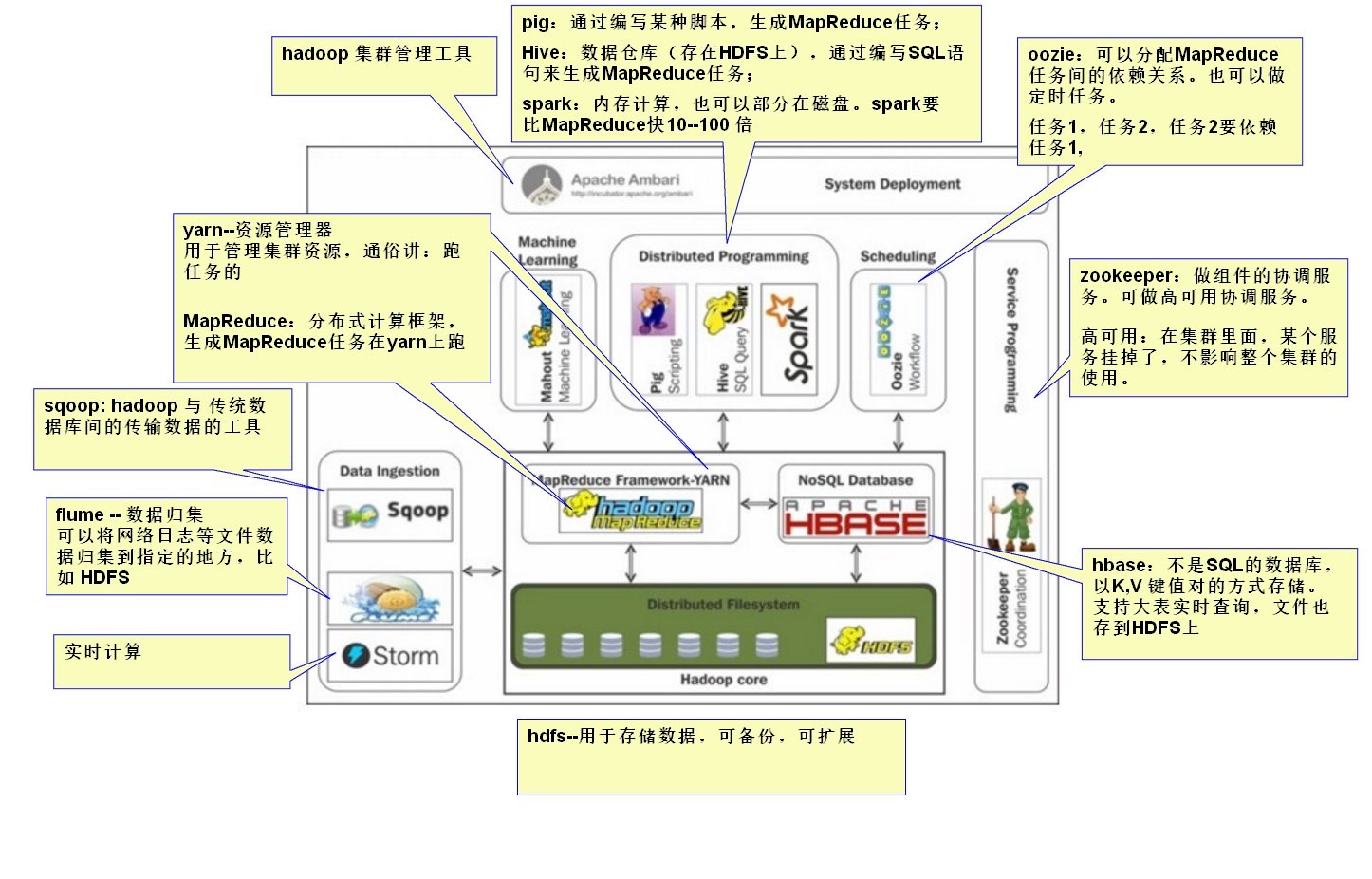
Hadoop生态圈
管理工具:Ambari、CDH等等。目前多数企业使用CDH管理集群
资源管理器:yarn
yarn管理集群资源,通俗讲就是用来跑任务的。
计算框架:MapReduce(离线)、Storm、Spark、Flink(实时计算)
数据采集:Flume 、sqoop
Flume:文本数据采集,例如可以将网络日志等文件归集到HDFS的某个路径下
Sqoop:数据库数据同步,例如将MySQL数据同步到某个HDFS路径下
生成组件:pig
可以通过编写脚本,生成MR任务
数据仓库:hive (数据存储在hdfs)
协调服务:zookeeper
各个组件之间的协调服务,可以作为高可用的协调服务,(高可用:指保证集群中某个服务器宕机,不会影响整个集群的使用)
数据库中间件:hbase、ES、rides、mongledb
数据存储:HDFS(可备份,可扩展)
任务调度:oozie
来源:https://www.cnblogs.com/mayucheng123/p/12174874.html