from numpy import *
import matplotlib.pyplot as plt
from math import sqrt
#距离度量函数(欧氏距离)
def eucDistance(vec1,vec2):
return sqrt(sum(power(vec2-vec1,2)))
#初始聚类中心选择
def initCentroids(dataSet,k):
numSamples,dim=dataSet.shape
centroids=zeros((k,dim))
for i in range(k):
index=int(random.uniform(0,numSamples))
centroids[i,:]=dataSet[index,:]
return centroids
#K-means聚类算法
#创建K个质心,再将每个数据点分配到最近的质心,然后重新计算质心
def kmeanss(dataSet,k):
numSamples=dataSet.shape[0]
clusterAssement=mat(zeros((numSamples,2)))
clusterChange=True
centroids=initCentroids(dataSet,k)#创建K个质心
while clusterChange:#将每个数据点分配到最近的质心
clusterChange=False
for i in range(numSamples):
minDist=100000.0
minIndex=0
for j in range(k):
distance=eucDistance(centroids[j,:],dataSet[i,:])
if distance<minDist:
minDist=distance
minIndex=j
clusterAssement[i,:]=minIndex,minDist**2
if clusterAssement[i,0]!=minIndex:
clusterChange=True
for j in range(k):#重新计算质心
pointsInCluster=dataSet[nonzero(clusterAssement[:,0].A==j)[0]]#第j类的所有不等于0的点,np.nonzero()非零元素的位置
centroids[j,:]=mean(pointsInCluster,axis=0)#均值为新质心
return centroids,clusterAssement
#聚类结果显示
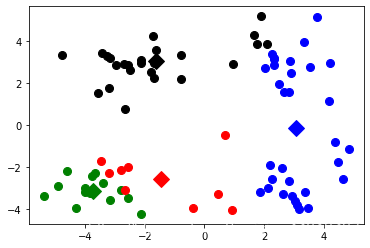
def showCluster(dataSet,k,centroids,clusterAssement):
numSamples,dim=dataSet.shape
mark=['or','ob','og','ok','^r','+r','<r','pr']
if k>len(mark):
print('sorry')
return 1
for i in range(numSamples):
markIndex=int(clusterAssement[i,0])
plt.plot(dataSet[i,0],dataSet[i,1],mark[markIndex],markersize=8)
mark=['Dr','Db','Dg','Dk','^b','+b','<b','pb']
for j in range(k):
plt.plot(centroids[j,0],centroids[j,1],mark[j],markersize=12)
plt.show()
#导入数据
dataSet=[]
fileIn=open('/testSet.txt')
for line in fileIn.readlines():
lineArr=line.strip().split('\t')#strip().split('\t')移除首尾的\t
dataSet.append([float(lineArr[0]),float(lineArr[1])])
dataSet=mat(dataSet)
k=4
centroids,clusterAssement=kmeanss(dataSet,k)
showCluster(dataSet,k,centroids,clusterAssement)
来源:CSDN
作者:Monica_Zzz
链接:https://blog.csdn.net/weixin_44819497/article/details/103826307