摘要
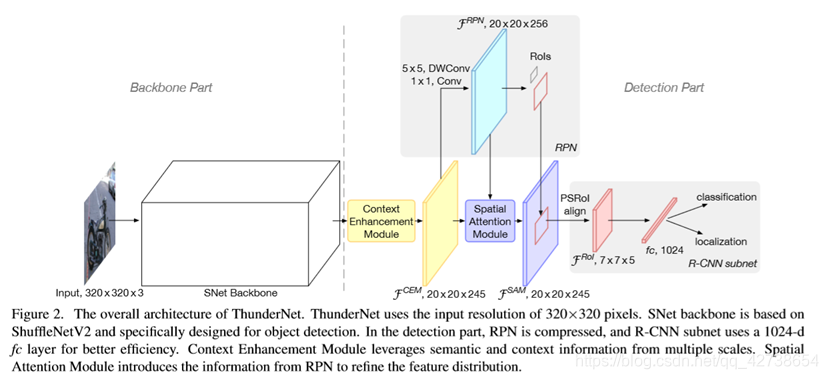
本文提出了第一个在arm上运行的实时的单线程速度最快的模型结构,分析之前lightweight backbones 的缺点,提出了一个轻量级的backbone,充分使用RPN,设计SAM和CEMblock减少计算量,产生更多discriminative feature,最后寻求resolution,backbone与head之间的平衡。
———————————————————————————————————————————————
1.Backbone部分
1.input-size:320x320,(为了提升推理速度),大的backbone匹配小的input和小的backbone匹配大的不是最优的。
2、感受野很重要,a large receptive field can leverage more context information and encode longrange relationship between pixels more effectively。
3.分类和检测用的backbone应该是不一样的,分类需要更深的特征,而检测应该着重于浅层特征(localization is sensitive to low-level features while high-level features are crucial for classification. )
本文研究了以往的模型,发现ShuffleNetV1/V2感受野太小,ShuffleNetV2 ,MobileNetV2缺乏浅特征,Xception缺乏充分的深层特征。
解决方案
SNet49速度,SNet146权衡 SNet535精度
1.将所有ShuffleNetV2 的3x3卷积变成5x5 depth-wise convolution, 5×5 depthwise convolutions运行速度和3
X3一致,但是感受野扩大了。
2. SNet146 and SNet535,移除了Conv5, add more channels in early stages
3.在SNet49,压缩Conv5到512channels(取消了移除Conv5) , add more channels in early stages for a better balance between low-level and high-level features
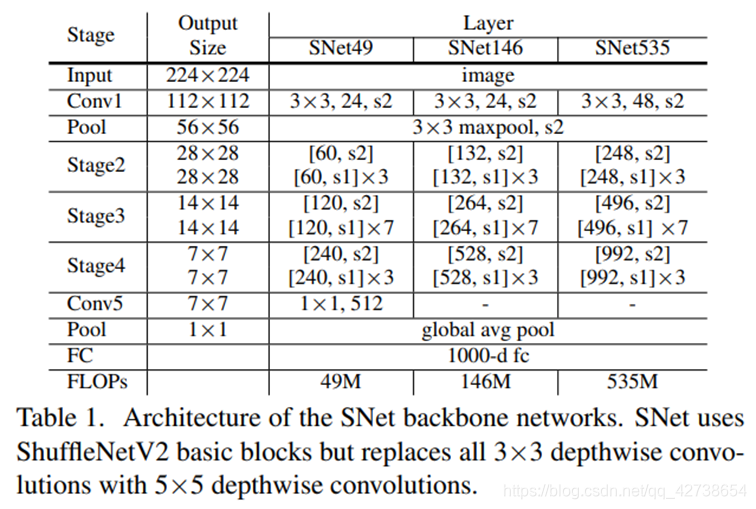
SNet49如果移除conv5,缺少了解码足够信息的能力。
如果channels->1024,致使backbone陷入low features中
———————————————————————————————————————————————
2. Detection部分(两个创新点)
Compressing RPN and Detection Head,two-stage网络经常要一个大的RPN和head,即使是Light-Head R-CNN压缩了head,但是backbone和detection part不匹配。
解决方法:
5x5 depth-wise convolution and a 256-channel 1×1 convolution代替3x3 convolution
Five scales {32×32,64×64,128×128,256×256,512×512}
five aspect ratios {1:2, 3:4, 1:1, 4:3, 2:1}
2.Head部分,ROI Warping之前原来feature.shape:10x7x7,现在压缩成5x7x7,ROI feature channels=245,所以fc只用了1024个神经元


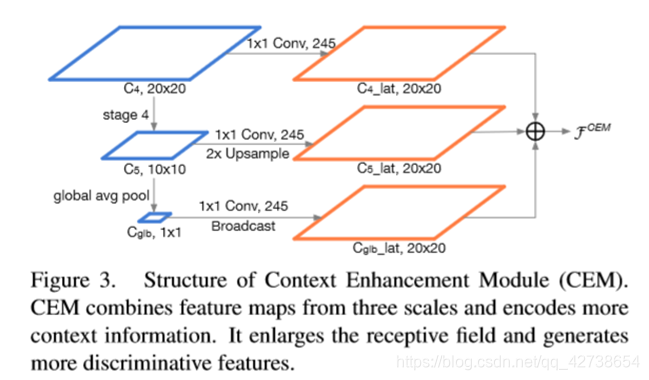


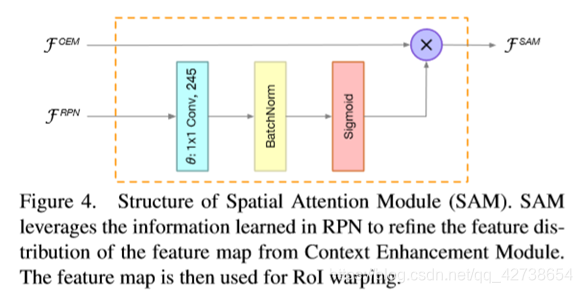
———————————————————————————————————————————————
Experientments
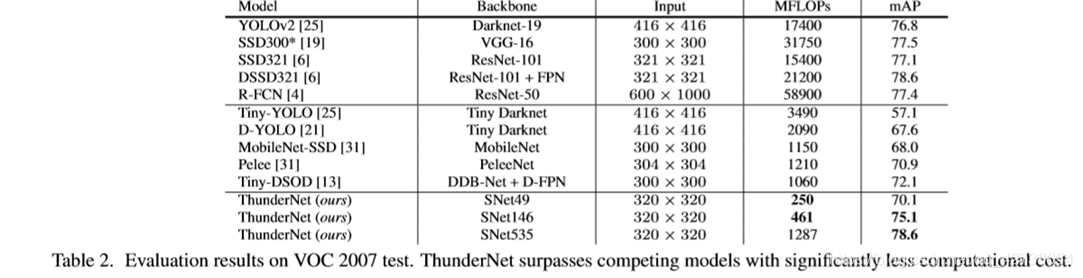
VOC2007测试结果,ThunderNet的backbone很小,所以在速度和精度之间取得了权衡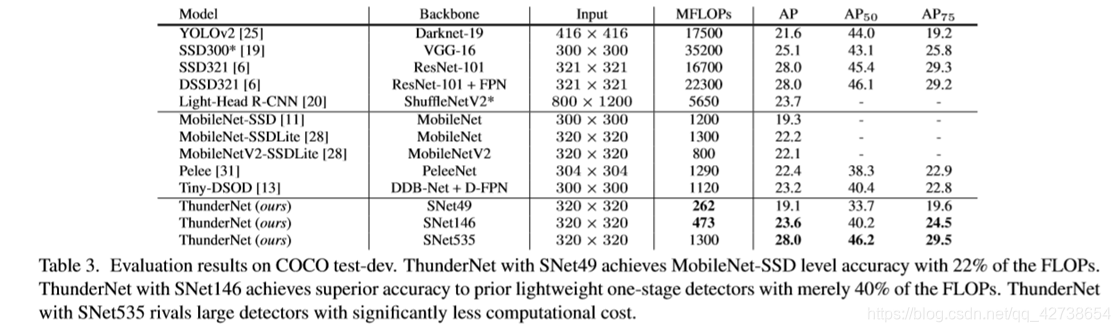
COCO上测试的结果:ThunderNet超过one-stage的检测算法,尤其是在AP75上超越的更多,究其原因,我们的模型提供了更精准的bounding box,二阶段网络优于一阶段网络。

———————————————————————————————————————————————
消融实验
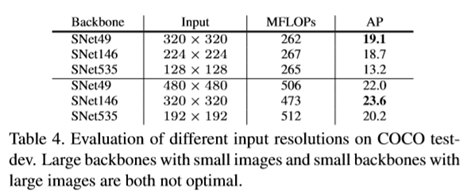
1.小的feature map会导致严重的细节损失,很那从backbone中修复
2.小的backbone不能从图像中解码充分的信息
Backbone和输入图片应该匹配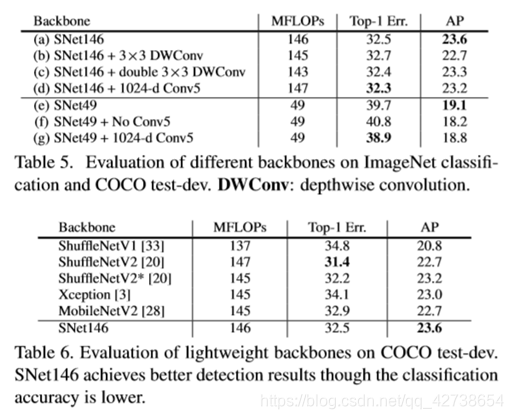
1.5x5 DWConv换成3x3,ap下降,所以在目标检测中大的感受野是有用的。
2.Conv5产生了更多discriminativefeatures,促进了分类任务,但是目标检测也需要专注于定位,所以在早起增加channels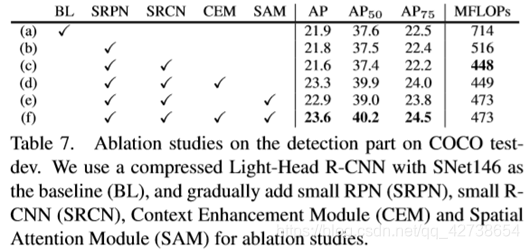
RPN and R-CNN subnet做法:替换RPN中所有3x3 conv为5x5和1x1 conv,没有伤害精度但减少了28%的计算量。减半RCNN中的FC层到1024,减少了0.23的AP但是获得了13% 的FLOPs压缩,CEM提高了1.7个点,SAM额外增加了5%的计算量,但是AP增加了1.3



———————————————————————————————————————————————
补充
GAP(Global average pooling):全连接层将卷积层展开成向量之后不还是要针对每个feature map进行分类,而GAP的思路就是将上述两个过程合二为一,一起做了。如图所示: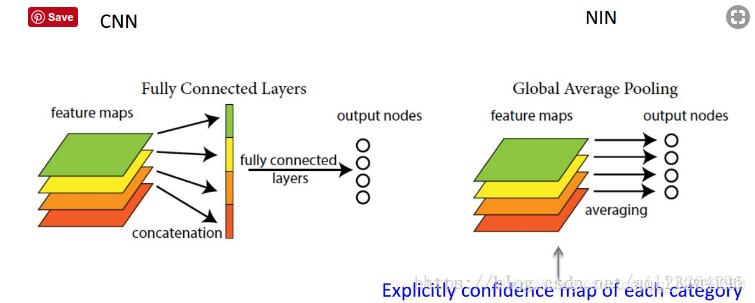

来源:CSDN
作者:bo.qiu_xbw
链接:https://blog.csdn.net/qq_42738654/article/details/103820351