此篇文章继续跟着小甲鱼的视频来初学网络爬虫,除了小甲鱼的网站上可下载视频,发现b站上也有全套的视频哦,会比下载来的更方便些。
网络爬虫,又称为网页蜘蛛(WebSpider),非常形象的一个名字。如果你把整个互联网想象成类似于蜘蛛网一样的构造,那么我们这只爬虫,就是要在上边爬来爬去,顺便获得我们需要的资源。我们之所以能够通过百度或谷歌这样的搜索引擎检索到你的网页,靠的就是他们大量的爬虫每天在互联网上爬来爬去,对网页中的每个关键词进行索引,建立索引数据库。在经过复杂的算法进行排序后,这些结果将按照与搜索关键词的相关度高低,依次排列。
1 urllib模块
urllib模块实际上是综合了url和lib的一个包。
url的一般格式为:
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL 由三部分组成:
第一部分是协议:http,https,ftp,file,ed2k…
第二部分是存放资源的服务器的域名系统或IP地址(有时候要包含端口号,各种传输协议都有默认的端口,如http的默认端口是80)
第三部分是资源的具体地址,如目录或者文件名等
举一个例子说明:
import urllib.request
response = urllib.request.urlopen("http://www.fishc.com")
html = response.read()
print(html) #二进制数据
html = html.decode('utf-8') #对二进制数据解码
print(html)
当遇到不了解的模块时,可通过IDLE中Help中打开Python的文档进行搜索查看,也可以使用print(模块名.__doc__)或者help(模块名)进行属性和使用方法的查看。如下为文档中urlopen的用法:
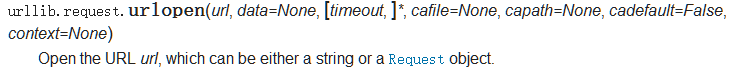
实例1:在placekitten网站下载一只猫的图片
import urllib.request
response = urllib.request.urlopen("http://placekitten.com/g/300/300") #urlopen返回一个对象
cat_img = response.read() #对象均可用print()打印出来 # response.geturl() 得到url #response.getcode() 返回值200,说明网站正常响应 response.info()得到文件信息
with open('cat_300_300.jpg','wb') as f:
f.write(cat_img)
可看到在当前运行目录下已成功下载了图片。
urlopen的url参数既可以是字符串也可以是一个request对象,则我们还可以将代码写成如下形式:
import urllib.request
req = urllib.request.Request("http://placekitten.com/g/300/300")
response = urllib.request.urlopen(req)
cat_img = response.read()
with open('cat_500_600.jpg','wb') as f:
f.write(cat_img)
实例2:利用百度翻译进行翻译
小甲鱼的视频中的实例是有道翻译,运行结果如下:

看弹幕说是有道翻译加了反爬虫机制,所以自己用百度翻译做了一个,研究了好一会儿,新手还是懵懵懂懂的,不过做出来了还是很开心的。代码如下所示:
import urllib.request
import urllib.parse
import json
while True:
content = input("请输入需要翻译的内容(退出q):")
if content in['q','Q']:
break
else:
url='http://fanyi.baidu.com/v2transapi'
data={}
data['from'] = 'en'
data['to'] = 'zh'
data['query'] = content
data['transtype'] = 'translang'
data['simple_means_flag'] = 3
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')
target = json.loads(html)
print("翻译结果为:%s"%(target['trans_result']['data'][0]['dst']))
打开翻译首页,点击翻译,在Network中找打方法为post的项,各个浏览器可能有差异,可尝试在Network里的XHR中查找。
代码中的url和data是复值表头中的url和Form Data,在IE浏览器中我找了好久,下面分别为360浏览器和IE浏览器的截图:
360: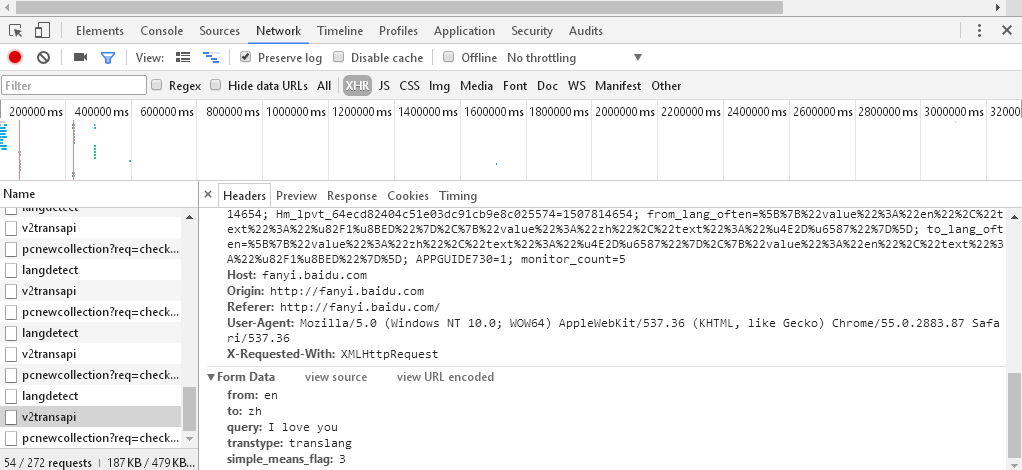
IE:
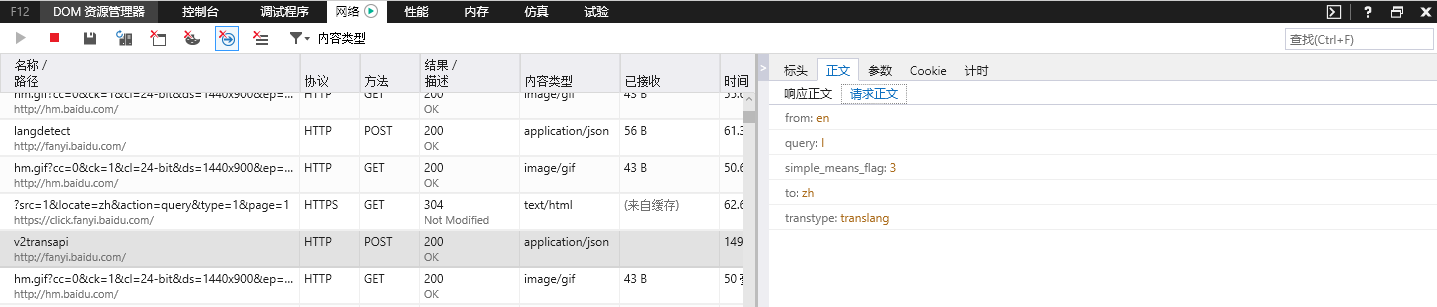
接着我们解释此行代码:
data = urllib.parse.urlencode(data).encode('utf-8')

当data未赋值时,是以GET的方式提交,当data赋值后,POST将会取代GET将数据提交。如上图所示,data必须基于某一模式,我们使用urllib.parse.urlencode()即可将字符串转换为需要的模式。
代码中使用了josen模块,因为直接打印出html出来的是json格式的数据不利于直接观看。最终运行结果如下所示:

2 隐藏
为什么要进行隐藏操作?因为如果一个IP在一定时间访问过于频繁,那么就会被被访问网站进行反爬虫拦截,无法进行我们爬虫的后续工作了,所以要给爬虫披上一层神秘的面纱,从而瞒天过海喽~
两种方法隐藏(修改)headers:
(1)通过Request的headers参数修改
(2)通过Request.add_header(key,val)方法修改
文档中说到headers必须是字典的形式,所以方法(1)直接通过增加字典键和对应值的方式来进行隐藏,如下所示,找到Request Headers中的User-Agent对应的值进行添加。
import urllib.request
import urllib.parse
import json
while True:
content = input("请输入需要翻译的内容(退出q):")
if content in['q','Q']:
break
else:
url='http://fanyi.baidu.com/v2transapi'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
data={}
data['from'] = 'en'
data['to'] = 'zh'
data['query'] = content
data['transtype'] = 'translang'
data['simple_means_flag'] = 3
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data,head)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print("翻译结果为:%s"%(target['trans_result']['data'][0]['dst']))
运行结果及headers是否正确输入的检查:
请输入需要翻译的内容(退出q):love
翻译结果为:爱
请输入需要翻译的内容(退出q):q
>>> req.headers #检查
{'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
第二种方法:
import urllib.request
import urllib.parse
import json
while True:
content = input("请输入需要翻译的内容(退出q):")
if content in['q','Q']:
break
else:
url='http://fanyi.baidu.com/v2transapi'
## head = {}
## head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
data={}
data['from'] = 'en'
data['to'] = 'zh'
data['query'] = content
data['transtype'] = 'translang'
data['simple_means_flag'] = 3
data = urllib.parse.urlencode(data).encode('utf-8')
## req = urllib.request.Request(url,data,head)#替换成下一句,因为不再引用上面的head所以去掉head
req = urllib.request.Request(url,data)
#使用add_header(key,value)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print("翻译结果为:%s"%(target['trans_result']['data'][0]['dst']))
第三种方法是引入休息时间,调用time模块的time.sleep来延长时间以避免网站认为是爬虫非法访问。
第四种方法是引入代理,代理把看到的内容返回给你,所以可以达到同样的效果。使用代理的步骤如下:
1. 参数是一个字典 {‘类型’:‘代理ip:端口号’}
proxy_support = urllib.request.ProxyHandler({})
2. 定制、创建一个 opener
opener = urllib.request.build_opener(proxy_support)
3a. 安装 opener
urllib.request.install_opener(opener)
3b. 调用 opener
opener.open(url)
import urllib.request
url='http://www.whatismyip.com.tw'
##iplist=['']
proxy_support = urllib.request.ProxyHandler({'http':'115.46.123.180:8123'})
#proxy_support = urllib.request.ProxyHandler({'http':random.choice(iplist)})
opener=urllib.request.build_opener(proxy_support)
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36')]
urllib.request.install_opener(opener)
response=urllib.request.urlopen(url)
html=response.read().decode('utf-8')
print(html)
运行结果如下所示,返回的IP地址是你的代理IP地址。

3 爬虫抓取煎蛋妹子图
跟着小甲鱼的视频去煎蛋网抓取妹子图啦,下述内容将自动进行和谐咔咔咔...
思路:新建本地保存图片文件夹→打开网站→记住图片的地址→保存图片到相应的文件夹
如图为煎蛋网妹子图网页显示,图片是按照页码来放置的。
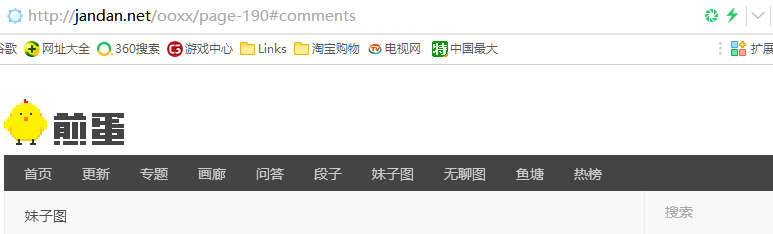
我们发现点击不同的页码,url改变的只是页码处的数字。
http://jandan.net/ooxx/page-190#comments
首先我们要获取页码,在页码处右键点击审查元素,如下所示:
则我们可以读取到网页的html,然后使用find函数来找到[190]中的数字190,也就是当前页码。
接着我们要获取当前页码下每张图片的url,同样在图片点击右键选择审查元素,可看到图片的地址如下:
嘻嘻,是gakki。以上是准备工作,接着我们就可以写出大概的框架来,其余的内容由函数封装实现
def download_mm(folder = 'ooxx',pages = 10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + 'page-' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder,img_addrs)
完整实现代码如下所示:
import urllib.request
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read()
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg',a,a+255)
if b != -1:
img_addrs.append(html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs
def save_imgs(folder,img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename, 'wb') as f:
img = url_open("http:"+each)
f.write(img)
def download_mm(folder = 'ooxx',pages = 10):
os.mkdir(folder)
os.chdir(folder)
url='http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + 'page-' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder,img_addrs)
if __name__ =='__main__':
download_mm()
成功在本地新建的文件夹中获取到了jpg的图片。
4 异常处理
(1)URLError
当urlopen无法处理一个响应的时候,就会引发URLError异常。 通常,没有网络连接或者对方服务器压根儿不存在的情况下,就会引发这个异常。同时,这个URLError会伴随一个reason属性,用于包含一个由错误编码和错误信息组成的元组。
(2)HTTPError
HTTPError是URLError的子类,服务器上每一个HTTP的响应都包含一个数字的“状态码”。有时候状态码会指出服务器无法完成的请求类型,一般情况下Python会帮你处理一部分这类响应(例如,响应的是一个“重定向”,要求客户端从别的地址来获取文档,那么urllib会自动为你处理这个响应。);但是呢,有一些无法处理的,就会抛出HTTPError异常。这些异常包括典型的:404(页面无法找到),403(请求禁止)和401(验证请求)。
下述举例说明Python处理异常的两种方法:
from urllib.request import Request,urlopen
from urllib.error import URLError,HTTPError
req = Request(someurl)
try:
response = urlopen(req)
except HTTPError as e:
print('The server coudln\'t fulfill the request.')
print('Error code:',e.code)
except URLError as e:
print('We failed to reach a server.')
print('Reason:',e.reason)
else:
#do something
注意HTTPError要在URLError前面。
from urllib.request import Request,urlopen
from urllib.error import URLError,HTTPError
req = Request(someurl)
try:
response = urlopen(req)
except HTTPError as e:
if hasattr(e,'reason')
print('We failed to reach a server.')
print('Reason:',e.reason)
elif hasattr(e,'code'):
print('The server coudln\'t fulfill the request.')
print('Error code:',e.code)
else:
#do something
来源:https://www.cnblogs.com/wwf828/p/7657218.html