这两天正在研究微服务架构中分布式事务的处理方案, 做一个小小的总结, 作为备忘. 如有错误, 欢迎指正!
概念澄清
事务补偿机制: 在事务链中的任何一个正向操作, 都必须存在一个完全符合回滚规则的可逆操作, 这个操作通常叫做rollback或者cancel.
CAP理论: CAP(Consistency, Availability, Partition Tolerance), 阐述了一个分布式系统的三个主要方面, 只能同时择其二进行实现. 常见的有CP系统, AP系统.
为什么CA不行呢? 因为没有P的话, 数据一致性会出现问题, 这是任何一个一致性系统不允许出现的情况.
幂等性: 简单的说, 业务操作支持重试, 不会产生不利影响. 常见的实现方式: 为消息额外增加唯一ID.
BASE(Basically avaliable, soft state, eventually consistent): 是分布式事务实现的一种理论标准.
柔性事务 vs. 刚性事务
刚性事务是指强一致性事务, 例如单机环境下遵循ACID的数据库事务, 或者分布式环境中的2PC等.
柔性事务是指遵循BASE理论的事务, 通常用在分布式环境中, 常见的实现方式有: 异步确保型, 最大努力通知型.
最佳实践
先上结论, 再分别介绍分布式事务的各种实现方式.
如果业务场景需要强一致性, 那么尽量避免将它们放在不同服务中, 也就是尽量使用本地事务, 避免使用强一致性的分布式事务(例如2PC).
如果业务场景能够接受最终一致性, 那么最好是使用异步确保型来解决(实际上大部分互联网公司的业务都是这么玩儿的).
注意: 以下每种方案都有不同的适用场合, 需要根据实际业务场景来选择.
两阶段提交(2PC)
两阶段提交(Two Phase Commit, 2PC), 具有强一致性, 是CP系统的一种典型实现, 是数据库层面的强一致性事务实现.
两阶段提交, 常见的标准是XA等. 例如Oracle的数据库支持XA, MySQL从5.5开始支持XA.
下图是两阶段提交的示意图:
2pc
图的上半是两阶段提交成功的演示, 下半是两阶段提交失败的演示. 关于两阶段提交网上有很多经典的讲解, 这里就不细说了, 可以参考前面的链接.
优点
依赖数据库服务提供商的XA实现来使用2PC, 无需像TCC那样每个服务都需要手工编写TCC接口实现类.
缺点
事务管理器单点失败
高并发不适用, 资源加锁时间较长, 无法灵活控制锁粒度(db层面的锁在2PC期间会一直被持有, 相较于TCC而言不灵活, 因为无法在tcc的中间阶段解锁.).
TCC (Try-Confirm-Cancle)
TCC是应用层的2PC, 具有最终一致性.
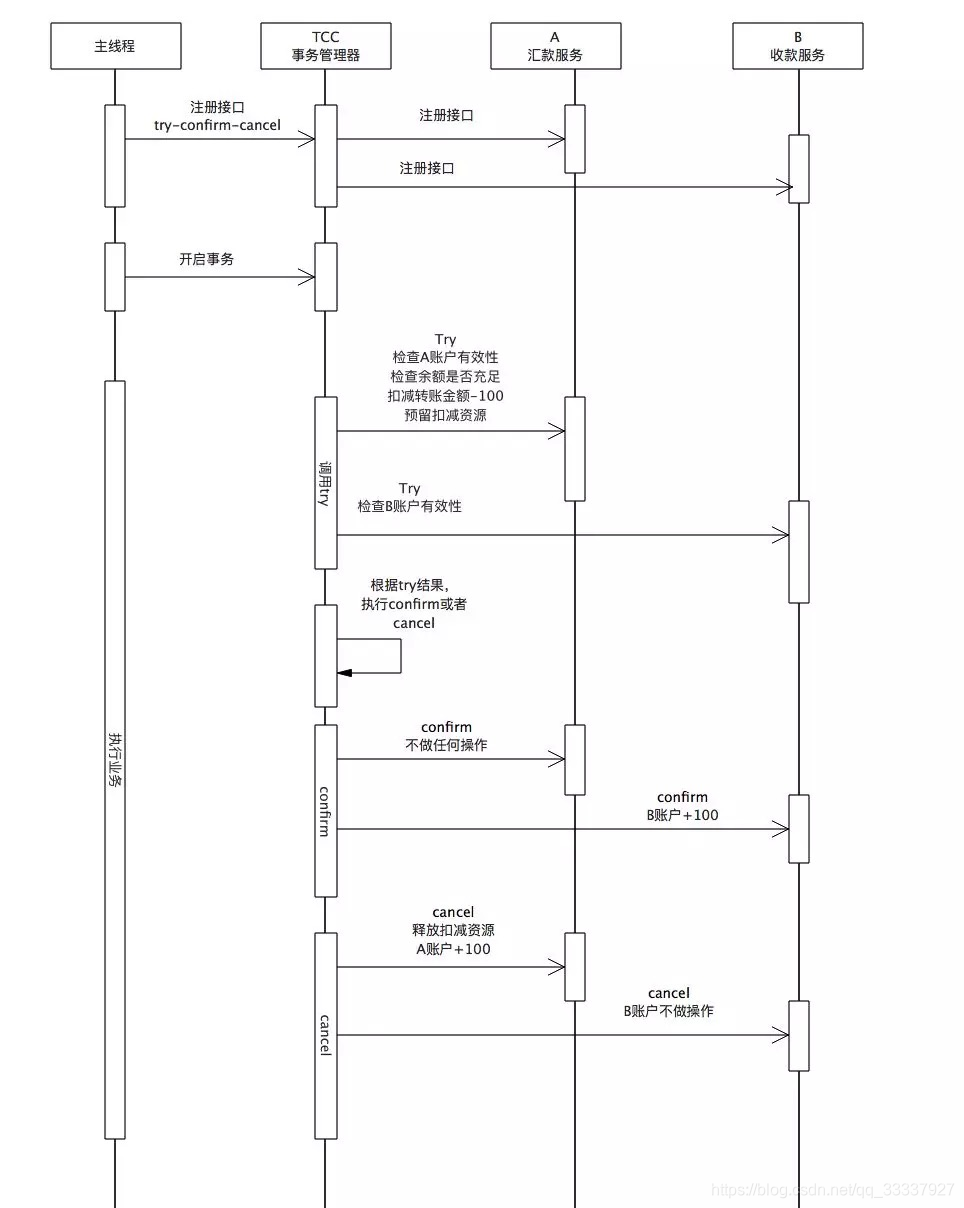
TCC实例-实时服务
以上图中的A->B实时汇款服务为例. 假设汇款服务和收款服务位于两个不同的微服务中.
首先服务主调方充当事务管理器的角色, 注册汇款收款服务的TCC接口.
事务开始, 进入TCC事务中的TRY阶段.
调用汇款服务的try接口, 检查A账户有效性(不在冻结状态), 余额充足性, 并扣减转账金额.
调用收款服务的try接口, 检查B账户的有效性(不为冻结状态).
检查所有被调服务的try返回值:
如果任一服务try失败, 那么会自动调用所有服务对应的cancel方法, 对于A账户, 就是将余额加回; 对于B账户, 不做任何操作.
如果所有服务的try均成功, 那么会自动调用所有服务对应的confirm方法, 对于A账户, 不做任何操作; 对于B账户, 增加汇款金额
注意: 如果任一cancel或confirm失败, 需要不断重试直到成功或人工介入.
事务结束.
优点
对比与前面提到的2PC, 主要优势是:
可自由控制锁粒度(在应用层控制);
缺点
事务管理器单点失败.
每个服务都要实现TCC接口, 较为复杂.
若允许并发操作, Confirm和Cancel操作无法幂等(可通过额外信息例如唯一事务id实现).
因为数据库级别的事务不允许脏读, 不存在数据一致性问题, 所以数据库级别的rollback设计是幂等的; 而TCC为了避免数据一致性问题, 只能通过补偿型操作实现. 这就导致Confirm和Cancel操作本身不可能幂等, 解决方案有两种:
通过事务id操作去重;
在confirm或cancel阶段, 只有明确收到confirm或cancel的失败反馈才能重试, 否则需要log而后人工介入.
适用场景
严格一致性
执行时间短
实时性要求高
举例: 红包, 收付款, 实时汇款业务.
异步确保型
通过将一系列同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响.
这个方案真正实现了两个服务的解耦, 解耦的关键就是异步消息和补偿性事务.
这里以一个例子作为讲解:
异步确保型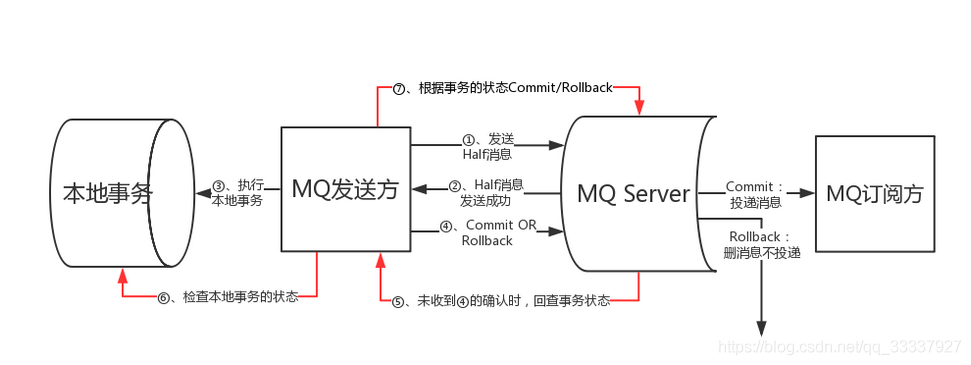
执行步骤如下:
MQ发送方发送远程事务消息到MQ Server;
MQ Server给予响应, 表明事务消息已成功到达MQ Server.
MQ发送方Commit本地事务.
若本地事务Commit成功, 则通知MQ Server允许对应事务消息被消费; 若本地事务失败, 则通知MQ Server对应事务消息应被丢弃.
若MQ发送方超时未对MQ Server作出本地事务执行状态的反馈, 那么需要MQ Servfer向MQ发送方主动回查事务状态, 以便进一步处理未投递的事务消息(丢弃或投递).
当得知本地事务执行成功时, MQ Server允许MQ订阅方消费本条事务消息.
消费者消费完之后, 需要ack到MQ Server, 之后事务消息才能从MQ Server删除. 否则消费者需要一直重试, 直到成功或者人工介入.
注意事项
消息中间件在系统中扮演一个重要的角色, 所有的事务消息都需要通过它来传达, 所以消息中间件也需要支持HAC来确保事务消息不丢失.
根据业务逻辑的具体实现不同,还可能需要对消息中间件增加消息不重复, 不乱序等其它要求.
适用场景
执行周期较长
实时性要求不高
例如:
非实时汇款业务
退货/退款业务
财务, 账单统计业务(先发送到消息中间件, 而后可进行批量记账)
最大努力通知型
这是分布式事务中要求最低的一种, 也可以通过消息中间件实现, 与前面异步确保型操作不同的一点是, 在消息由MQ Server投递到消费者之后, 允许在达到最大重试次数之后直接结束事务, 无需人工介入确保成功.
优点
高并发, 低耦合
缺点
不支持回滚;
适用场景
交易结果消息的通知等.
SAGA
将一个大事务拆成一串小事务, 分段提交和回滚.
可能的执行序列:
成功: T1, T2, T3, …, Tn;
失败: T1, T2, , T3, …, Tn-1, Cn-1, Cn-2, Cn-3, …, C1
缺点
有数据一致性问题:
举个例子, 定义:
T1=扣100元 T2=给用户加一瓶水 T3=减库存一瓶水
C1=加100元 C2=给用户减一瓶水 C3=给库存加一瓶水
如果在T3失败进行回滚, 此时用户已经把水喝了, 那么就会造成回滚失败, 出现数据一致性问题. 根本原因是没有了tcc的try阶段预留资源导致的. 解决方案就是要么在所有资源上加锁, 要么严格控制t的顺序, 将回滚困难的放在最后.
小结
不管是同步事务中的事务管理器(协调者), 还是异步事务中使用的消息中间件,若要达到一致性保证,都需要使用带有同步复制语义的HAC提供的高可用和高可靠特性,这些都是以性能为代价的,无疑成为了SOA架构中的典型性能瓶颈之一.
不同方案对比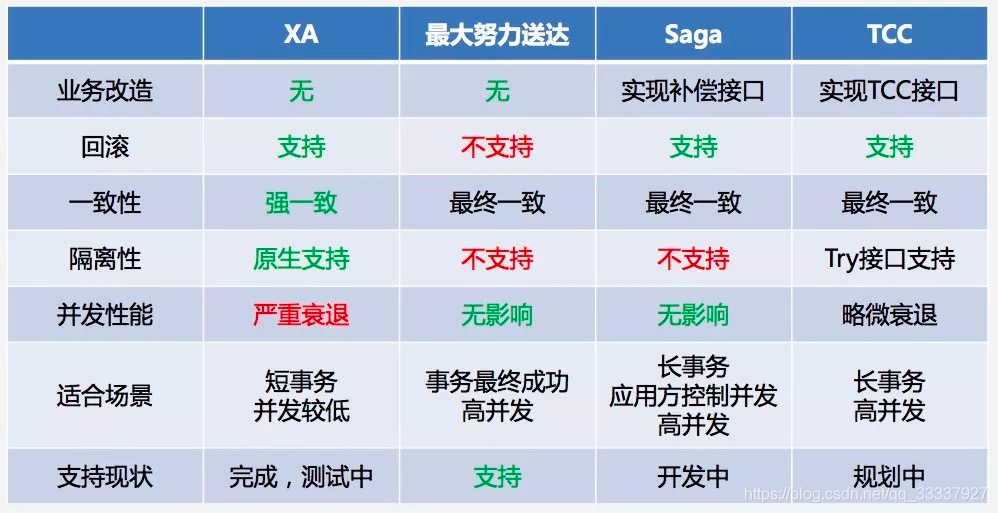
来源:CSDN
作者:大脸猫王花猪
链接:https://blog.csdn.net/qq_33337927/article/details/103530072