fasttext的基础理论
前言简介
fasttext是NLP里,一个非常高效的,基于词向量化的,用于文本分类的模型。虽然其原理比较简单,但是其中涉及到了不少的用于提速和准确率的小技巧。
这篇文章主要从理论的层面(一直想有时间去扒源码来看看来着)介绍这些小技巧,而对于和word2vec部分中类似的地方会简单提到,但是不会展开说明(这个作者先提出的word2vec,后来提出的fasttext,二者有不少相似之处)Word2vec的相关内容参考peghoty所写的word2vector中的数学原理详解.pdf[1]。
当然本文做的介绍不可能面面俱到,而且很多地方也可能理解不准确,希望大家不吝赐教。
正文
fasttext和word2vec中的CBOW非常类似,对于每一个文本而言,第一步是将所有单词向量化后作为输入;第二步是将输入的所有向量在隐藏层进行平均化处理得到新的向量;第三步输出预测值。接下来我们分别对这三部进行具体的解释。
第一步:输入
在word2vec中,它的输入就是单纯的把词袋向量化。但是在fasttext还加入了n-grams的思想。举个例子“我 喜欢 她“,如果只用这几个词的组合来反映这个句子,就是(”我”,”喜欢”,”她”),问题来了,句子“她 喜欢 我”的词的组合也是(”我”,”喜欢”,”她”),但这两个句子的意思完全不同,所以如果只用句子里的词来代表这个句子的意思,是不准确的,所以我们要加入n-grams,比如说取n=2,那么此时句子“我 喜欢 她“的词语组合就是(”我”,”喜欢”,”她”,”我喜欢”,”喜欢她”)这就和句子”她喜欢我”所得到的词语组合不同了,我们也能因此区分开这两个句子。
所以此时我们的输入就是(”我”,”喜欢”,”她”,”我喜欢”,”喜欢她”)向量化后的5个向量,词向量化参照[1].
第二步:中间层
其实这一步的思想更加朴素,就是将第一步中输入的向量相加再求平均,得到一个新的向量,然后将这个向量输入 输出层。
第三步:输出层
按照一般的多分类思想,我们的输出应该采用一个基于线性分类思想的softmax值,但当的维度n*1比较高且分类种类k比较多的时候,计算量会比较大,因为此时我们作用于w的是一个k*n的矩阵A,y = Aw,y是k*1的向量,经过softmax后,每个位置对应的就是那一类的概率,而这个A是需要我们训练计算的,所以这时的时间复杂度时。此时就可以用huffman编码树作为输出,而不是一个向量,我们把这种方法叫做:hierarchical softmax。以此图作为参考: 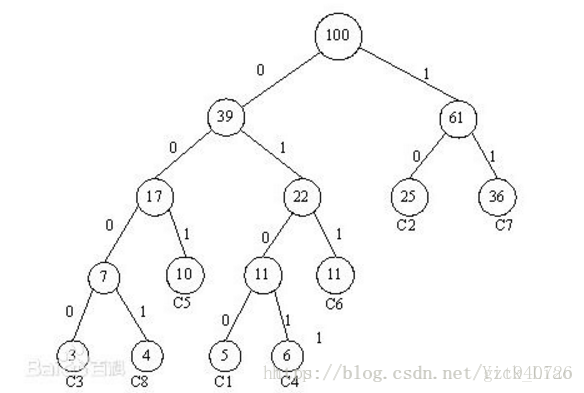
每个子节点都是一个类,根节点的输入是,每次在节点分叉处,我们只需要用LR(逻辑回归)的思路处理一个二分类问题:,其中是一个1*k的参数向量,所以该过程计算复杂度是O(n),而这颗树的平均深度是,所以此时的时间复杂度是.所以在fasttext的实现中,采用的是这种hierarchical softmax。
计算方法
说明:这一节内容在原文Bag of Tricks for Efficient Text Classification(高效文本分类技巧)[2]中并没有提到,我也是根据[1]中的计算进行的推测,难免谬误之处,望不吝赐教。
不难发现,这个模型的搭建和神经网络有点类似,不过比神经网络朴素很多,而且计算上也不会采用后向传播法,而是采用极大似然估计+梯度下降法就能处理,接下来进行具体说明。
首先需要明确的是我们的未知数,理论上来说,每个词的向量化都是未知的,但是我们关心的是它们的平均向量,所以我们每次训练迭代只需要更新而非每个词的向量即可。除此之外,在这颗huffman树里的每个非叶节点上都有个未知参数,这也是需要每次迭代更新的。已知的是分类标签y,这个y一定在这颗树的某个子节点上,假设从根节点到y的路径是,其中代表路径在深度处的所处的节点。我们的目标是由根节点出发,到达节点y的概率最大化(极大似然估计):
这指的是从上一个节点()到它的概率,也就是上面所述的含有参数\theta的sigmoid函数。举个例子,如果是的右子节点,那么就是(注意这里角标是i-1,大家想清楚是为什么,这也是为什么叶节点处不需要参数)
到此我们的目标就确定了,剩下的就是通过随机梯度下降法(sgd)来求解这个极大似然估计,注意这里我们需要把目标函数拆成一个个来进行计算(看起来这条路径每个节点都和上一个节点有关,但实际上并不是一个条件概率,读者可以自己思考),一方面是因为这些概率本身就是互相独立的,另一方面不拆开的话不然无法使用sgd。大体的更新思路是对和要做到“同步更新”,详细操作参考[1]的4.1节。
结尾
至此基本对fasttext的介绍就结束啦,但是笔者也遇到了2个没有想明白的问题。
1.在[2]中提到的对于n-grams使用hash技巧,我不是很明白是怎么个意思,原作者给了两篇参考文献还没来得及看,坐标位于[2]中的2.2里的(Weinberger et al. 2009)[3]和 (Mikolov et al. 2011)[4]两篇文章。
2.对于计算方法一步中,我们更新的是向量平均值,但是我们最后还是希望得到每个词具体对应的向量,我们如何去得到每个词自己的词向量了?还是一开始就应该是对每个词的词向量进行更新?(因为[1]一文中就是对这个进行更新,所以我就照着它写的,这个问题估计要扒源代码才能彻底明白)。
答:我们用梯度下降法的时候直接对每个词的词向量向量进行更新即可,而不是对他们的平均值进行更新,这样就可以避免这个问题了。
链接汇总:
[1]word2vector中的数学原理详解.pdf
[2]Bag of Tricks for Efficient Text Classification(高效文本分类技巧)
来源:CSDN
作者:IGV丶明非
链接:https://blog.csdn.net/gzt940726/article/details/80141554