一.什么叫索引:
索引就是类似书的目录,提高检索数据的效率。
索引是系统按照某个具体的算法(哈希,散列,二叉树),将数据从全部数据里进行提取,维护成一个索引文件,然后系统在进行数据查询的时候,发现如果查询条件刚好满足索引条件,就可以从索引文件中快速的定位的数据所在位置。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
**
二.索引类型包括:
普通索引(index)
对数据没有要求,文件很大,效率比较低,但是查询速度相对较快。
ALTER TABLE 表名字 ADD INDEX index_name ( 需要加索引的列 )
全文索引(fulltext)
全文索引只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建,Sysman支持全文索引。MySQL5.6.后InnoDB引擎也加入了全文索引对文本的内容进行分词,因为MySQL提供了支持中文、日文和韩文的内置全文ngram解析器。
具体化
ALTER TABLE 表名 ADD FULLTEXT ( 需要加索引的列)
唯一索引(unique key)
唯一索引可以有多个但索引列的值必须唯一,索引列的值允许有空值(null)。如果是组合索引,则列值的组合必须唯一。创建唯一索引的目的不是为了提高访问速度,而只是为了避免数据出现重复。
ALTER TABLE 表名 ADD UNIQUE ( 需要加索引的列 )
主键索引(primary key效率最高的索引)
主键是一种唯一性索引,每个表只能有一个主键,在单表查询中,PRIMARY主键索引与UNIQUE唯一索引的检索效率并没有多大的区别,但在关联查询中,PRIMARY主键索引的检索速度要高于UNIQUE唯一索引。
ALTER TABLE 表名 ADD PRIMARY KEY ( 需要加索引的列 )
联合索引:
对多个字段同时建立的索引,对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
三.索引类型包括:
普通索引(index)
对数据没有要求,文件很大,效率比较低,但是查询速度相对较快。
ALTER TABLE 表名字 ADD INDEX index_name ( 需要加索引的列 )
全文索引(fulltext)
全文索引只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建,Sysman支持全文索引。MySQL5.6.后InnoDB引擎也加入了全文索引对文本的内容进行分词,因为MySQL提供了支持中文、日文和韩文的内置全文ngram解析器。
具体化
ALTER TABLE 表名 ADD FULLTEXT ( 需要加索引的列)
唯一索引(unique key)
唯一索引可以有多个但索引列的值必须唯一,索引列的值允许有空值(null)。如果是组合索引,则列值的组合必须唯一。创建唯一索引的目的不是为了提高访问速度,而只是为了避免数据出现重复。
ALTER TABLE 表名 ADD UNIQUE ( 需要加索引的列 )
主键索引(primary key效率最高的索引)
主键是一种唯一性索引,每个表只能有一个主键,在单表查询中,PRIMARY主键索引与UNIQUE唯一索引的检索效率并没有多大的区别,但在关联查询中,PRIMARY主键索引的检索速度要高于UNIQUE唯一索引。
ALTER TABLE 表名 ADD PRIMARY KEY ( 需要加索引的列 )
联合索引:
对多个字段同时建立的索引,对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
三.索引类型包括:
普通索引(index)
对数据没有要求,文件很大,效率比较低,但是查询速度相对较快。
ALTER TABLE 表名字 ADD INDEX index_name ( 需要加索引的列 )
全文索引(fulltext)
全文索引只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建,Sysman支持全文索引。MySQL5.6.后InnoDB引擎也加入了全文索引对文本的内容进行分词,因为MySQL提供了支持中文、日文和韩文的内置全文ngram解析器。
具体化
ALTER TABLE 表名 ADD FULLTEXT ( 需要加索引的列)
唯一索引(unique key)
唯一索引可以有多个但索引列的值必须唯一,索引列的值允许有空值(null)。如果是组合索引,则列值的组合必须唯一。创建唯一索引的目的不是为了提高访问速度,而只是为了避免数据出现重复。
ALTER TABLE 表名 ADD UNIQUE ( 需要加索引的列 )
主键索引(primary key效率最高的索引)
主键是一种唯一性索引,每个表只能有一个主键,在单表查询中,PRIMARY主键索引与UNIQUE唯一索引的检索效率并没有多大的区别,但在关联查询中,PRIMARY主键索引的检索速度要高于UNIQUE唯一索引。
ALTER TABLE 表名 ADD PRIMARY KEY ( 需要加索引的列 )
联合索引:
对多个字段同时建立的索引,对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
(abc) (ab) (ac)(bc)(a) (b) (c)
场景:复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
1、需要加索引的字段,要在where条件中
2、数据量少的字段不需要加索引
3、如果where条件中是OR关系,加索引不起作用
4、符合最左原则
Like在联合索引怎么用:
在MySQL中,like ‘string%’可以用到索引,但是like ‘%string%’却会全表扫描;
select * from table where code like ‘Cod2%’,且走的是INDEX RANGE SCAN,而这样写like ‘%xxx’或’%xxx%'不会走索引,感觉就像组合索引一样,直接用索引第一个字段会走索引,而用索引第二个字段则不会走索引。
主键索引与唯一索引的区别:
- 主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
- 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
- 唯一性索引列允许空值,而主键列不允许为空值。
- 一个表最多只能创建一个主键,但可以创建多个唯一索引。
- 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
- 主键可以被其他表引用为外键,而唯一索引不能。
**
三.索引的优点
1、创建唯一性索引,保证数据库表中每一行数据的唯一性。
2、加快数据的检索速度,这也是创建索引的最主要的原因。
3、减少磁盘IO(向字典一样可以直接定位)。
4、通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
5、加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
注意:没有索引的话 会全表查找,效率非常慢。索引可以建可以不建
如果涉及查找的话,最好建索引。
四.什么情况加索引
索引是建立在系统文件上的,会占用一定的内存空间,另外数据在更新的时候也会去维护索引,消耗内存,所以索引一定要正确的使用,索引并不是越多越好,要根据具体的查询业务来规划索引的建立。
1.当数据多且字段值有相同的值得时候用普通索引。
2. 当字段多且字段值没有重复的时候用唯一索引。
3. 当有多个字段名都经常被查询的话用复合索引。
4. 普通索引不支持空值,唯一索引支持空值。
5. 但是,若是这张表增删改多而查询较少的话,就不要创建索引了,因为如果你给一列创建了索引,那么对该列进行增删改的时候,都会先访问这一列的索引,
6. 若是增,则在这一列的索引内以新填入的这个字段名的值为名创建索引的子集,
7. 若是改,则会把原来的删掉,再添入一个以这个字段名的新值为名创建索引的子集,
8. 若是删,则会把索引中以这个字段为名的索引的子集删掉。
9. 所以,会对增删改的执行减缓速度,
10. 若是这张表增删改多而查询较少的话,就不要创建索引了。
11. 更新太频繁地字段不适合创建索引。
12. 不会出现在where条件中的字段不该建立索引。
**
五.如何创建索引
1.创建表的时候添加索引:
create table stu(
id int primary key auto_increment,
name varchar(32) not null,
age tinyint unsigned not null,
email varchar(32) not null,
intro text,
unique key (name),
index (email),
fulltext index (intro)
)engine myisam charset utf8;
2.在修改表的时候,添加索引
create table stu1(
id int primary key auto_increment,
name varchar(32) not null,
age tinyint unsigned not null,
email varchar(32) not null,
intro text
)engine myisam charset utf8;
alter table stu1 add unique key (name), add index (email), add fulltext index (intro);
3、删除索引
主键索引的删除,在删除主键 索引时,如果有自增长,先修改掉自增长,再删除主键
alter table 表名 drop primary key
普通索引的删除:
alter table 表名 drop index 索引名字 (如果索引名称没有指定则是索引的字段名称)
删除唯一索引:
alter table 表名 drop index 索引名字
4、查询索引:
1.show index form 表名\G
2.show indexes from 表名
3.desc 表名
4.show create table 表名
**
六.创建索引的注意事项
(1)较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
select * from emp where sex = '男‘
更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1
(2)不会出现在WHERE子句中字段不该创建索引
(3)索引字段长度最大限度的短,如果过长,索引树冗余,效率低。也不宜太短
**
七.索引的缺点
1.创建索引和维护索引需要时间,而且数据量越大时间越长;
2.创建索引需要占据磁盘的空间,如果有大量的索引,可能比数据文件更快达到最大文件尺寸;
3.当对表中的数据进行增加,修改,删除的时候,索引也要同时进行维护,降低了数据的维护速度;
八.explain(执行计划)工具的使用
主要用于分析sql语句的执行情况(并不执行sql语句)得到sql语句是否使用了索引,使用了哪些索引。
语法:explain sql语句\G 或 desc sql语句\G
在mysql之前的版本中,explain只支持select语句,但是在最新的5.6版本中,它支持 explain update/delete了。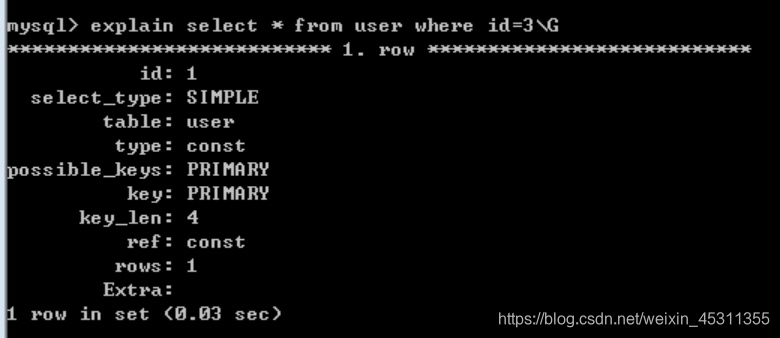
select_type: 查询类型
table: 查询针对的表
possible_key: 可能用到的索引
注意: 系统估计可能用的几个索引,但最终,只能用1个.
key : 最终用的索引.
key_len: 使用的索引的最大长度
type列: 是指查询的方式, 非常重要,是分析”查数据过程”的重要依据
可能的值如下:
all<index<range<ref(eq_ref)<const
all: 意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行.
来源:https://blog.csdn.net/weixin_45311355/article/details/102754538