一 、基本概念
kubernetes中的Node、Pod、Replication Controller、Service等都是一种“资源对象”,基本都可以通过kubectl或者通过API编程调用,执行增删改查操作都保存在ETCD中持久化存储
1.1 Master
作用:每个k8s集群都需要一个mater节点来管理,master一般是单独部署
核心组件:
- Kubernetes API Server(kube-apiserver),提供HTTP REST 接口的关键服务进程,是k8s里所有资源增删改查
等操作的唯一入口
- Kubernetes Controller Manager (kube-controller-manager),k8s所有资源的自动化控制中心。
- Kubernetes Scheduler(kube-scheduler),调度(POD)的进程。
- ETCD,master节点一般还启动一个ETCD Server进程,所有资源对象的数据全部保存在ETCD中
1.2 Node
除了Master,k8s集群的其他节点都称为Node节点,Node节点是k8s集群中的工作负载节点,当某个Node宕机,骑上的工作负载会被master自动转移到其他节点上
核心组件:
-
kubelet:负责Pod对象的容器创建、启停等任务,同时与Master节点密切协作
-
kube-proxy:实现kubernetes Service 的通信与负责均衡机制的组件
-
Docker Engine (Docker):docker引擎,负责本机的容器创建和管理工作
默认kubelet会向master注册自己,会上传Node的信息,定时向master上报数据,超时则标记不可用(Not Ready)
查看集群中Nodes
$ kubectl get nodes
NAME STATUS AGE
kubernetes-minion1 Ready 2d
查看某个Node详细信息
$ kubectl describe node kubernetes-minion1
1.3 Pod
每个Pod都有一个根容器的Pause容器和其他用户业务容器,Pod里的业务容器共享Pause容器的IP和Volume,一个Pod的容器于另外主机上的Pod容器能够直接通信。
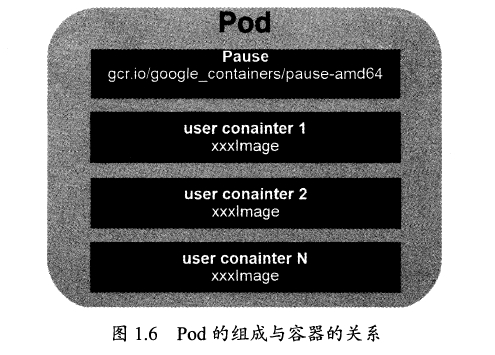
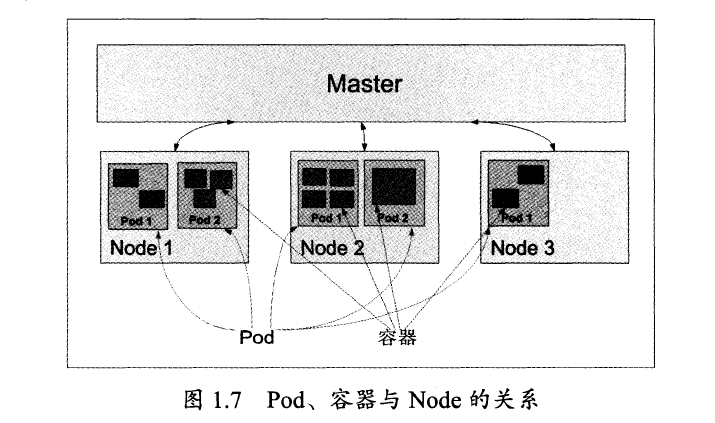
Pod分类
- 普通Pod:普通Pod创建就存储在ETCD中,被Master调度到某node上进行绑定
- 静态Pod(static Pod):静态Pod不受kubernetes管理,不再ETCD存储,放在某个具体node的具体文件中,只在此具体文件所在的node上启动运行。
例子:pod创建模板

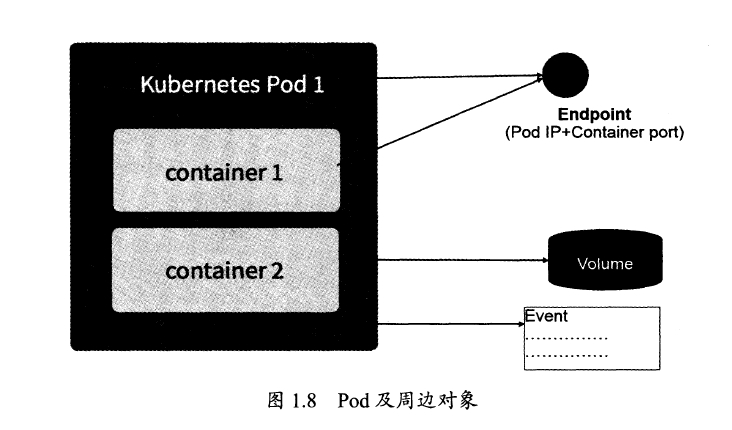
Endpoint
Pod的IP和containerPort组成Endpoint,他代表Pid里的一个服务进程的对外通信地址,一个pod可以有多个endpoint。
Volume
k8s的Volume相对于docker的Volume支持了GlusterFS等等分布式存储。
Event
可以查看event来定位错误
#查看pod描述信息
$ kubectl describe pod xxx
配额
每个pod都可以进行计算资源的限制。
- Requests:该资源的最小申请量
- Limites:该资源最大允许使用量,超过会被k8s kill 并重启
配置管理
k8s使用configMap来实现对pod的配置管理
使用方法:
- 生成为容器内的环境变量
- 设置容器的启动命令的启动参数(需设置为环境变量)
- 以Volume的形式挂载为容器内部的文件或者目录
Pod的生命周期
Pod的状态:
| 状态 | 描述 |
|---|---|
| 挂起(Pending) | API Server创建了Pod资源对象并已经存入了etcd中,但是它并未被调度完成,但pod内还有一个或者多个容器的进行没有创建,包括仍然处于从仓库下载镜像的过程中。 |
| 运行中(Running) | Pod已经被调度到某节点之上,并且所有容器都已经被kubelet创建完成。 |
| 成功(Succeeded) | Pod 中的所有容器都被成功终止,并且不会再重启。 |
| 失败(Failed) | Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。 |
| 未知(Unknown) | 因为某些原因无法取得 Pod 的状态,可能由于网络通信不畅。 |
pod的重启策略:
- Always:当容器失效时,由kubelet自动重启容器
- **OnFailure **: 当容器终止运行且退出代码不为0时,由kubelet自动重启
- Never:不论容器运行状态如何,都不重启
RC和DaemonSet必须设置为Always
Job:OnFailure或Never,确保容器执行完成后不再重启
kubelet:Pod失效时自动重启他,不论RestartPolicy设置为什么值,并且也不会对Pod进行健康检查。
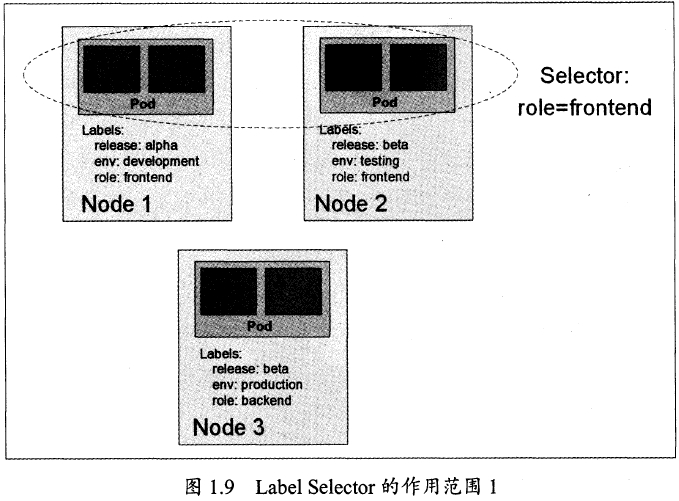
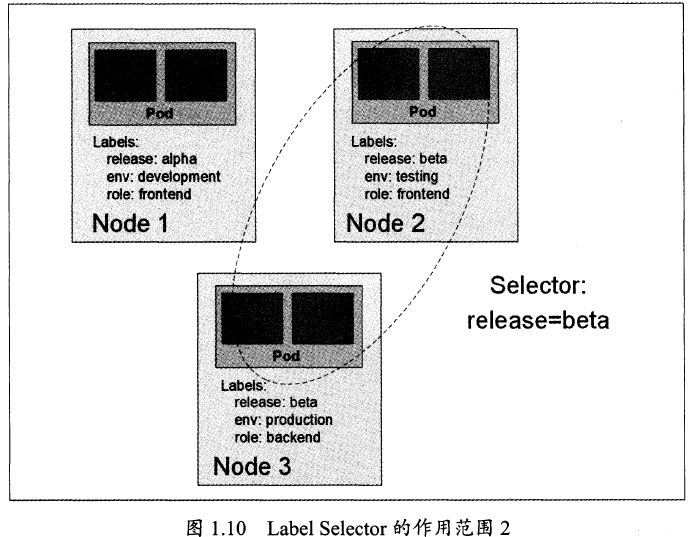
1.4 Label(标签)
Label是一个key=value键值对,可以附加在Node、Pod、Service、RC等,一个资源对象可以定义任意数量Label。
作用:通过Label分组管理,过滤筛选,通过Label Selector 来查询过滤资源对象,类似于SQL。
Label Selector分类:
- equility-based(等式),例如:name=redis-slave
- set-based(集合),例如name in (redis-master,redis-slave),name not in...
1.5 Repliaction Controller(RC)
声明pod的期望副本数量,某个Node节点宕机,k8s会调度在其他node上部署pod,已达到期望数量。
#修改RC来实现POD动态缩放
$ kubectl scale rc redis-slave --replicas=3
注意:删除RC不会动态的删除Pod,应该设置replicas=0,并更新RC,或者通过kubectl的stop和delete一次性删除RC和RC控制的全部Pod
k8s升级版本后使用Replica Set替换RC,区别在RS支持equility-based和set-based,而RC支持equility-based,一般Replica Set和Deployment配置使用。
###1.6 Deployment
使用Deployment来替代RC,内部使用了Replica Set实现。Deployment相对RC可以随时知道Pod的部署进度。部署模板中使用kind: Deployment。
使用场景:
- 替换RC
- 查看部署状态
- 更新Deployment以创建新的pod(比如镜像升级)
- 回滚上一个Deployment版本
- 挂起、恢复一个Deployment
使用方法:
-
创建
apiVersion: apps/v1 kind: Deployment metadata: name: myapp-deploy namespace: default spec: replicas: 2 selector: matchLabels: app: myapp release: dev template: metadata: labels: app: myapp release: dev spec: containers: - name: myapp-containers image: ikubernetes/myapp:v1 ports: - name: http containerPort: 80运行命令
$ kubectl create -f tomcat-deployment.yaml -
查看
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE myapp-deploy 1 1 1 1 1m- DESIRED: Pod副本数量的期望值, 既Deployment里定义的Replica
- CURRENT: 当前Replica的值,这个值不断增加,直到达到DESIRED为止, 完成整个部署过程
- UP-TO-DATE: 最新版本的Pod的副本数量,用于指示在滚动升级的过程中,有多少Pod副本已成功升级
- AVAILABLE: 当前集群可用Pod副本数量, 既集群中当前存活的Pod数量。
-
查看Replica Set
$ kubectl get rs NAME DESIRED CURRENT READY AGE myapp-deploy-f4bcc4799 1 1 1 10m
1.7 Horizontal Pod Autoscale(HPA)
横向扩容,通过分析指标来动态扩容。
支持pod负载度量指标:
- CPUUtilizationPercentage(暂不建议在生产使用)
- 应用程序自定义的度量指标,比如服务在美妙内的相应请求书(TPS或QPS)
1.8 Service(服务)
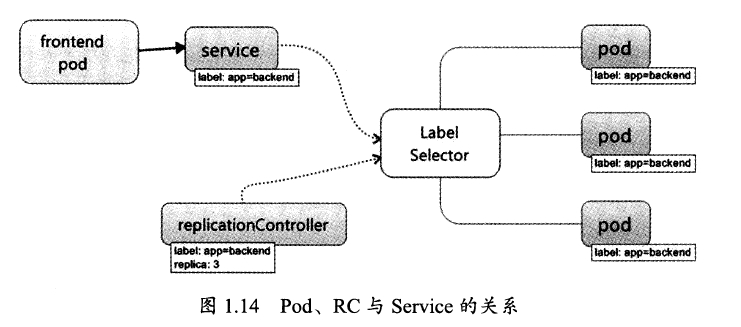
service定义一个服务的访问入口,使用每个Node上的kube-proxy转发到具体Pod,实现负载均衡。每个service分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP,并在service的整个生命周期内,不会改变。
模板实例
apiVersion: v1
kind: Service
metadata:
name: tomcat-svc
spec:
ports:
- port: 8080
selector:
tier: frontend
上述内容定义了一个名为tomcat-svc的Service,他的服务端口为8080,拥有tier:=frontend这个Label的所以Pod实例都属于它。
三种IP:
-
NodeIP: Node节点的Ip地址。物理网卡上的IP。
-
Pod Ip: Pod的Ip地址。docker engine根据docker0网桥的ip地址段进行划分的。
-
ClusterIp :
-
Cluster IP 只作用于 Kubernetes Service 这个对象,并由k8s管理和分配IP地址 (来源于 Cluster IP 地址池)
-
无法被Ping, 没有一个"实体网络对象"来响应
-
只能结合Service Port 组成一个具体的通信端口,单独的Cluster IP 不具备TCP/IP通信的基础,并且他们属于集群内部封闭空间,如集群外想访问,需要额外的工作
-
k8s 集群内 Node IP网、Pod IP网与 Cluster IP网之间通信,采用k8s自己设计的一套特殊路由规则,与我们熟悉的IP路由有很大不同
-
无法在集群外部直接使用这个地址
-
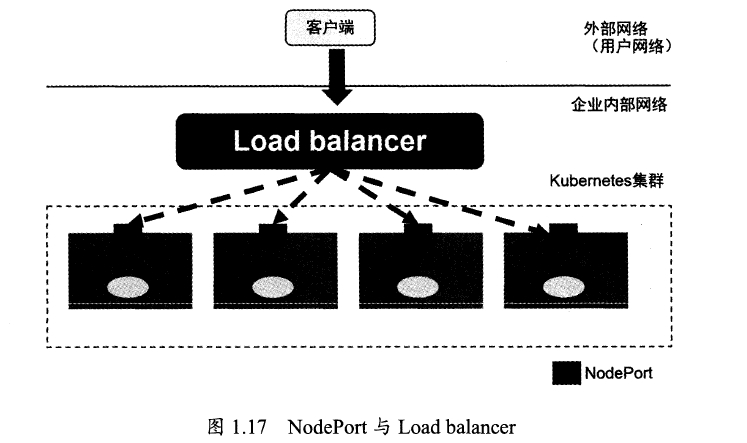
采用NodePort 解决上述问题
apiVersion: v1 kind: Service metadata: name: tomcat-service spec: type: NodePort ports: - port: 8080 nodePort: 31002 # 手动指定NodePort 端口号,不然会自动分配。 selector: tier: frontend
-
NodePort还没完全解决外部访问Service的所有问题,如负载均衡。最好使用一个负载均衡器,由负载均衡器负责转发流量到后面某个Node的NodePort。如: 使用硬件 Load balancer 负载, 活 HAProxy 或者 Nginx。
创建
$ kubectl create -f tomcat-svc.yaml
查看
$ kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.18.131:6443 6m
tomcat-svc 172.17.1.3:8080 1m
$ kubectl get svc tomcat-svc -o yaml
三种Port:
- containerPort:容器暴露的端口。也就是说可以通过该容器端口,访问对应的服务。
- targetPort: 当service中指定的端口和pod中暴露出的端口不一致时,需要用targetPort指定出pod暴露出的端口
- nodePort: 出现在Service中,指定外部机器可通过该物理端口,访问服务。其中type必须是NodePort
通过Add-On增值包的方式引入了DNS系统, 把服务名作为DNS域名, 这样程序就可以直接使用服务名查询ip进行通信连接了。
###1.9 Volume(存储卷)
与docker的volume区别:
- 定义在pod上
- 被pod中多个容器共享
- 与pod的声明周期相同
- 支持多种类型Volume(ClusterFS、Ceph)
例如:给 Pod 增加一个 名字为 datavol 的 Volume, 挂载到 /mydata-data上
template:
metadata:
labels:
app: mysql
spec:
volumes:
- name: datavol
emptyDir: {}
containers:
- name: mysql
image: mysql
volumeMounts:
- mountPath: /mydata-data
name: datavol
Volume类型:
-
emptyDir:临时空间,Pod删除,则删除
-
hostPath:挂载宿主机上的文件和目录
- 日志永久保存
- 访问docker文件系统
注意:不同的Node上具有相同配置的Pod可能会因为宿主机上文件和目录不同导致对Volume上目录和文件访问结果不一致;无法将hostPath纳入k8s资源配额管理。
-
gcePesistentDisk:使用谷歌公有云提供的永久磁盘。
-
awsElasticStore:亚马逊EBS Volume存储。
-
NFS:NFS网络文件系统。
volumes: - name: nfs nfs: server: nfs-server.localhost path: "/"
...
1.10 Persistent Volume
通过从虚拟机中定义一个网络存储,然后划出一个网盘并挂载在虚拟机上。Persistent Volume:简称 PV ,Persistent Volume Claim 简称PVC,PV和PVC功能类似。
与Volume区别:
- PV只能是网络存储,不属于任何Node,但可以在每个Node访问
- PV不定义在Pod上
- PV支持多种类型
下面给出NFS类型的PV的一个yaml定义文件,声明了需要5Gi的存储空间:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
nfs:
path: /somepath
server: 172.17.0.2
PV 的 accessModes 类型:
- ReadWriteOnce: 读写权限、并且只能被单个Node挂载
- ReadOnlyMany: 只读权限、允许多个Node挂载
- ReadWriteMany: 读写权限、允许多个Node挂载
如果Pod 想申请PV,,需要先定义一个PVC
apiVersion: v1
kind: PersistentVolumeClain
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
然后在Pod 的 Volume 定义上引用上述PVC :
volumes:
- name: datavol
persistentVolumeClain:
claimName: myclaim
1.11 Namespace(命名空间)
多用于多租户的资源隔离。
k8s 启动后,会创建一个名为default的Namespace 通过
kubectl get namespaces
如果不特别指明,则用户创建的Pod、RC、Service都将被系统创建到这个默认namespace。
创建命名空间
apiVersion: v1
kind: Namespace
metadata:
name: development
创建后可以指定这个资源对象属于哪个Namespace.
定义一个名为busybox的Pod, 放入上面创建的:
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: development
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
name: busybox
这时使用命令将看不到上面创建的pod, 默认使用的是default
kubectl get pods
需要添加参数--namespace 来查看
kubectl get pods --namespace=development
可以给每个命名空间实现租户隔离的同时,还是可以资源配额管理。
1.12 Annotation 注释
使用key=value键值对定义。作用是定义k8s对象的元数据(metadata),并用于label selector。
来源:oschina
链接:https://my.oschina.net/u/4178242/blog/3098020