上周日(2 月 9 日),Pulsar 开启了 2020 年度第一次直播,也是小 Pu 成长路上的第一次线上直播,我们在 zoom 和 B 站同时进行了直播,也有很多朋友发弹幕和留言给我们,感谢各位的捧场!
Pulsar 的第一场线上直播,请来了 StreamNative 的 CEO 郭斯杰大佬,为我们带来了一场关于「Pulsar Basics」的分享。
在正式进入内容前,郭斯杰也为大家介绍了什么是 TGIP(Thank God It's Pulsar),
类似可以参考 👇🏻Thank God It's Friday。
https://en.wikipedia.org/wiki/Thank_God_It%27s_Friday
同时更新了 Pulsar 的近况,主要是以下两个:
-
Namespace level offloader
https://github.com/apache/pulsar/pull/6183
-
Supports evenly distribute topics count when splits bundle
https://github.com/apache/pulsar/pull/6241
后续大家还想了解关于 Pulsar 的任何问题,都可以去下边这个 repo 下提 issue,没准哪天你的提问就扩展为一期专门的直播啦!
🙋♂️
https://github.com/streamnative/tgip-cn
同时我们也公布了一个需要国内用户帮忙填充的「Pulsar 用户调查问卷」,我们将根据此问卷,撰写一份 Pulsar 的年度报告,到时候也会发给大家。
如果你想为此报告贡献一点力量,可以复制链接在浏览器进行填写:
https://bit.ly/2Qtrrnf
。填写者将有机会免费赢取「2020 Pulsar Summit」的入场券吼!
Pulsar 在雅虎旗下被孵化出生时,其实就顶着一个「消息中间件」的任务前行着。
随着开源后,各行业各公司小伙伴们,根据不同的需求,为 Pulsar 赋予了很多更丰富的功能,所以目前它也不再只是中间件的功能,而是慢慢发展成为一个 Event Streaming Platform(事件流处理平台),具有 Connect(连接)、Store(存储)和 Process(处理)功能。
在连接方面,Pulsar 具有自己单独的 Pub/Sub 模型,可以同时满足 Kafka 和 RocketMQ 的应用场景。
同时 Pulsar IO 的功能,其实就是 Connector,可以让你非常方便地将数据源导入到 Pulsar 或从 Pulsar 导出等。
在 Pulsar 2.5.0 中,我们新增了一个重要机制:
Protocol handler。
这个机制允许你在 broker 自定义添加额外的协议支持,这样就可以保证在不更改原数据库的基础上,也能享用 Pulsar 的一些高级功能。
所以 Pulsar 也延展出比如:
KoP、ActiveMQ、Rest 等。
Pulsar 提供了可以让用户导入的途径后,那就需要在 Pulsar 上进行存储。
Pulsar 采用的是分布式存储,最开始是在 Apache BookKeeper 上进行。
后来添加了更多的层级存储,通过 JCloud 和 HDFS 等多种模式进行存储的选择。
当然,层级存储也受限于你的存储容量。
Pulsar 提供了一个无限存储的抽象,方便第三方平台进行更好的批流融合的计算。
这也就是 Pulsar 的数据处理能力。
Pulsar 的数据处理能力实际上是按照你数据计算的难易程度、实效性等进行了切分。
目前 Pulsar 包含以下几类集成融合处理方式:
Pulsar Function:Pulsar 自带的函数处理,通过不同系统端的函数编写,即可完成计算并运用到 Pulsar 中。
Pulsar-Flink connector 和 Pulsar-Spark connector:作为批流融合计算引擎,Flink 和 Spark 都提供流计算的机制。如果你已经在使用他们了,那恭喜你。因为Pulsar 也全部支持这两种计算,无需你再进行多余的操作了。
Presto (Pulsar SQL):有的朋友会在应用场景中更多的使用 SQL,进行交互式查询等。Pulsar 与 Presto 有很好的集成处理,你可以用 SQL 在 Pulsar 进行处理。
所以以上概括来说,Pulsar 更像是是一个相对完善的信息流处理平台。
你可以通过 Pulsar,把 Pulsar 的不同能力结合在一起,迸发出更高效的功能应用,去把项目打造的更多样化。
Pulsar 整个体系里有很多的组件,Pulsar 最初产生时就是一个消息中间件,前面也有提到过。
所以郭斯杰用「拼乐高」的方式,融入 Pulsar 的一些概念讲解,让大家更容易的了解 Pulsar。
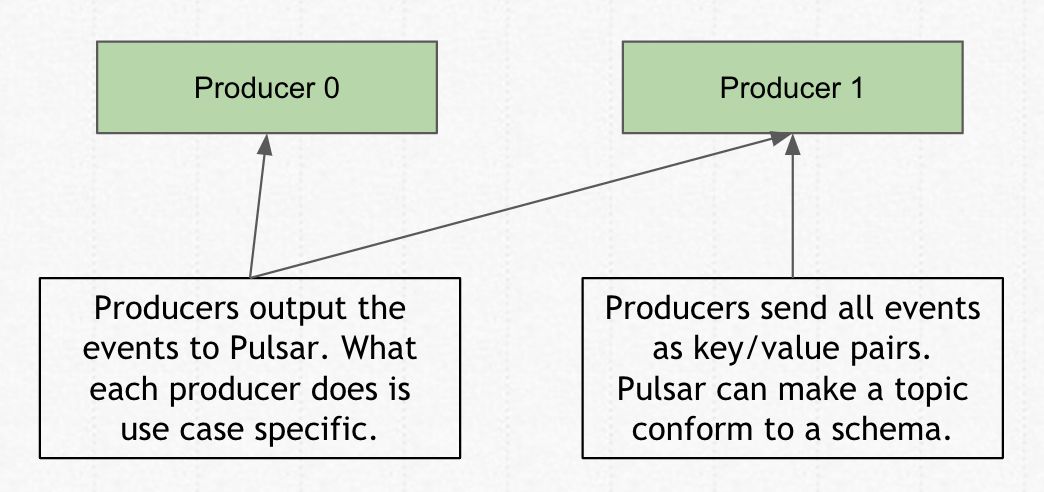
身为一个 Pub/Sub 系统,首先的存在要素必然是 Producer(生产者)。
何为 producer?
即消息生产方,所有消息调用生产方的接口,来将消息发送给 Pulsar。
Producer 的作用是与本身的应用程序有关。
Producer 往 Pulsar 里发送消息时,相应的数据会带上 schema 的信息。
Pulsar 会确保一个 producer 往 topic 发送的消息是满足一定的 schema 格式。
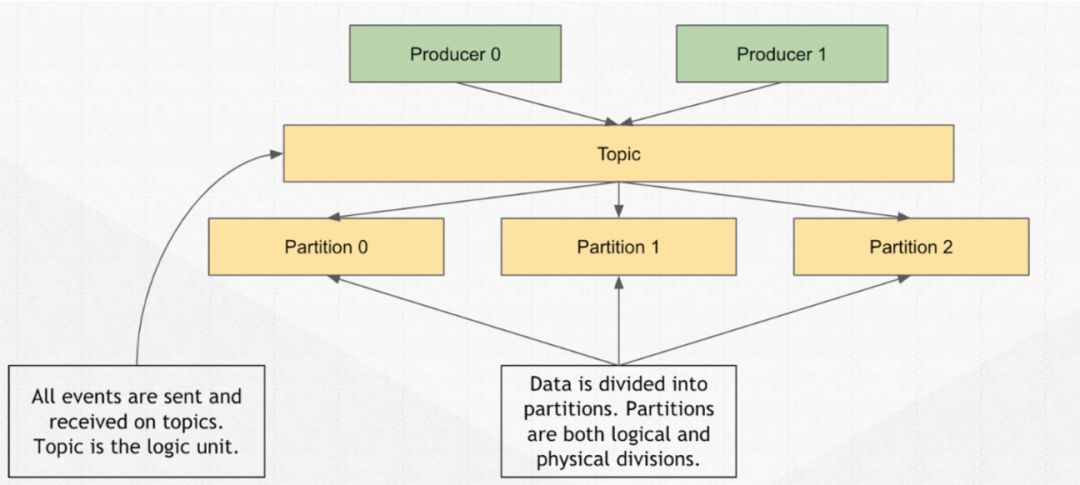
上文提到了,producer 会往 topic 里发送消息。
那什么是 topic 呢?
它是一个消息的集合,所有生产者的消息,都会归属到指定的 topic 里。
所有在 topic 里的消息,会按照一定的规则,被切分成不同的分区(Partition)。
一个分区会落靠在某一个服务器上,原理类似于 Kafka Topic Partition。
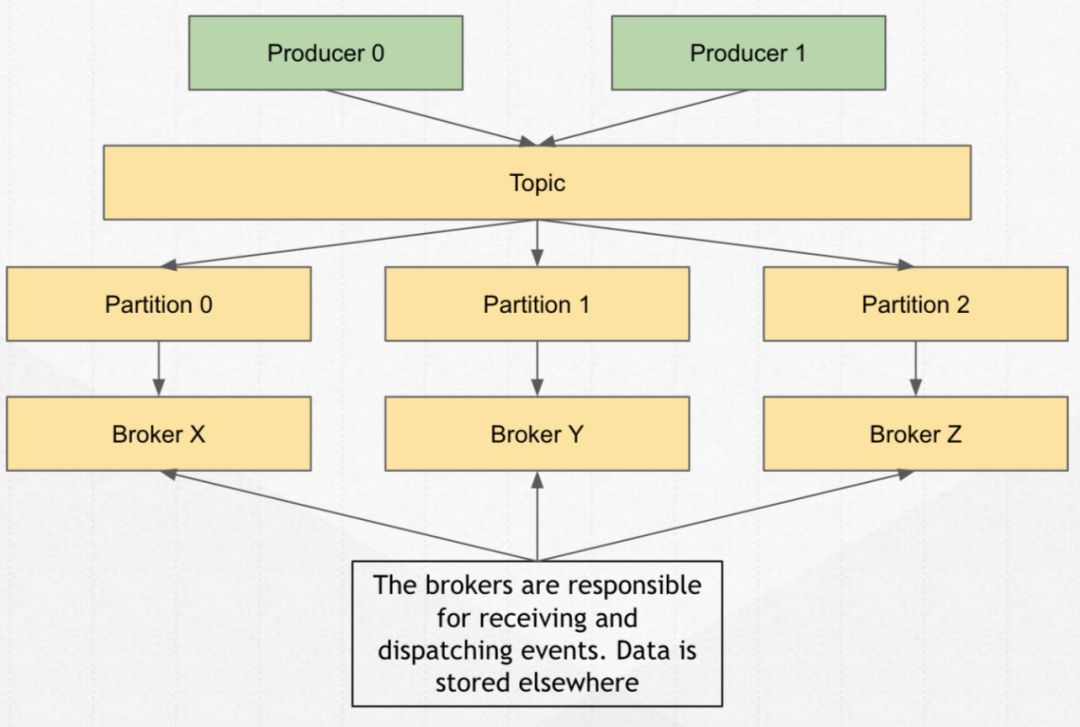
分区落靠的服务器,就是 Broker。
Broker 用来接收与发送消息,生产方连接到 broker 去生产消息,消费方连接到 broker 去消费消息。
数据不会真正存储在 broker,这就是 Pulsar 与其他中间栈的区别:
Pulsar 里的 broker 是没有存储状态的。
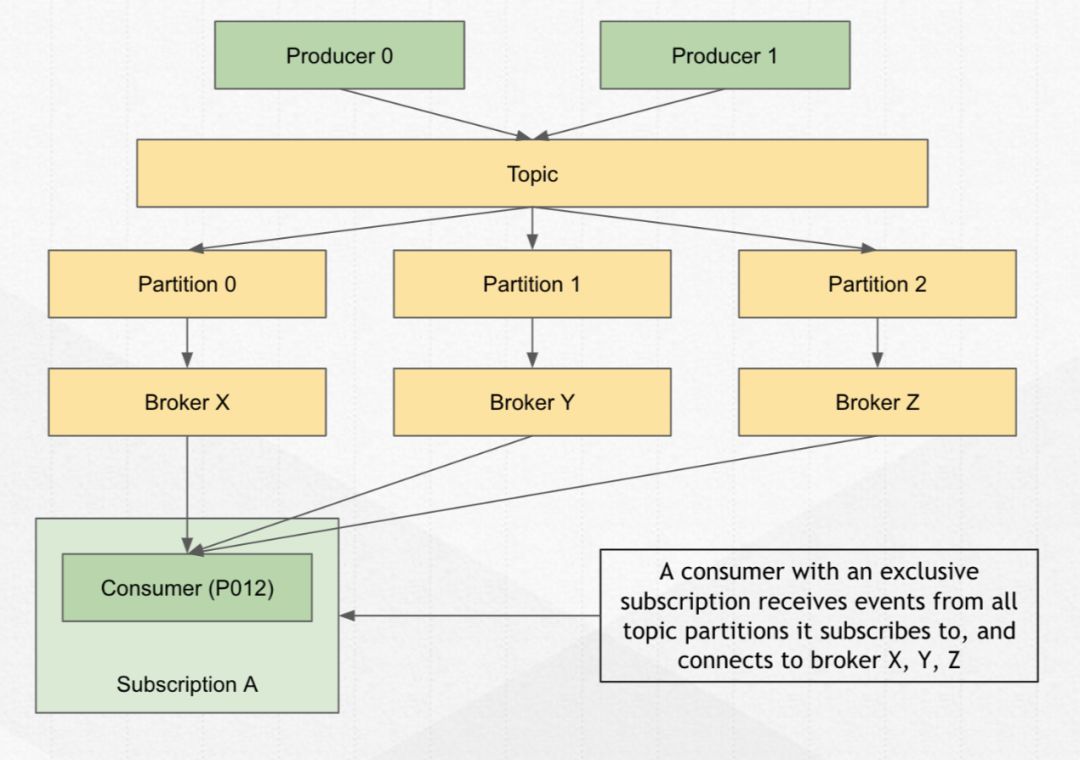
以上积木流程搭下来后,生产者产出的消息到了某一个 broker 上,就应该出现另一端的消费者(Consumer)了。
Consumer 作为消息的接收方,连接到 broker 接收消息。
在 Pulsar 里将 consumer 接收消息的过程称之为:
Subscription(订阅),类似于 Kafka 的 consumer group。
一个订阅里的所有 consumer,会作为一个整体去消费这个 topic 里的所有消息。
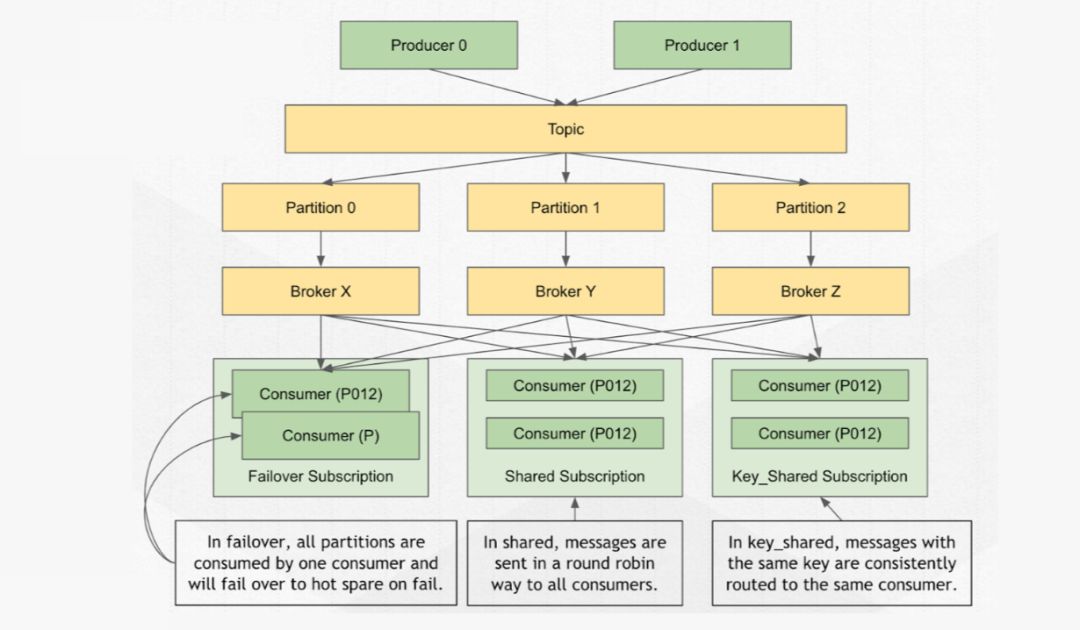
Pulsar 里每一个订阅都会有不同的模式。
目前 Pular 的订阅模式主要是以下四种:
比如上图中,不管有多少个 consumer 同时存在,只会有一个 consumer 是活跃的,也就是只有这一个 consumer 可以接收到这个 topic 的所有消息。
这种模式就为 Pulsar 订阅模式中的独占订阅(Exclusive)。
Failover(故障转移订阅)
则是多个 consumer 可以附加到同一订阅。
但是,对于给定的主题分区,将选择一个 consumer 作为该主题分区的主使用者,其他 consumer 将被指定为故障转移消费者,当主消费者断开连接时,分区将被重新分配给其中一个故障转移消费者,而新分配的消费者将成为新的主消费者。
发生这种情况时,所有未确认的消息都将传递给新的主消费者,这类似于 Apache Kafka 中的使用者分区重新平衡。
Shared(共享订阅)
是可以将所需数量的 consumer 附加到同一订阅。
消息以多个 consumer 的循环尝试分发形式传递,并且任何给定的消息仅传递给一个 consumer。
当消费者断开连接时,所有传递给它并且未被确认的消息将被重新安排,以便发送给该订阅上剩余的 consumer。
Key_Shared 订阅模式
是 2.4.0 以后一个新订阅模式。
类似于共享订阅,但又不是按照循环模式,是按照 key 进行分发,比如同一特征(奇数、偶数等)。
总的来说是融合了 Failover 的有序性和 Shared 的消费扩展性、更均衡的一种订阅模式。
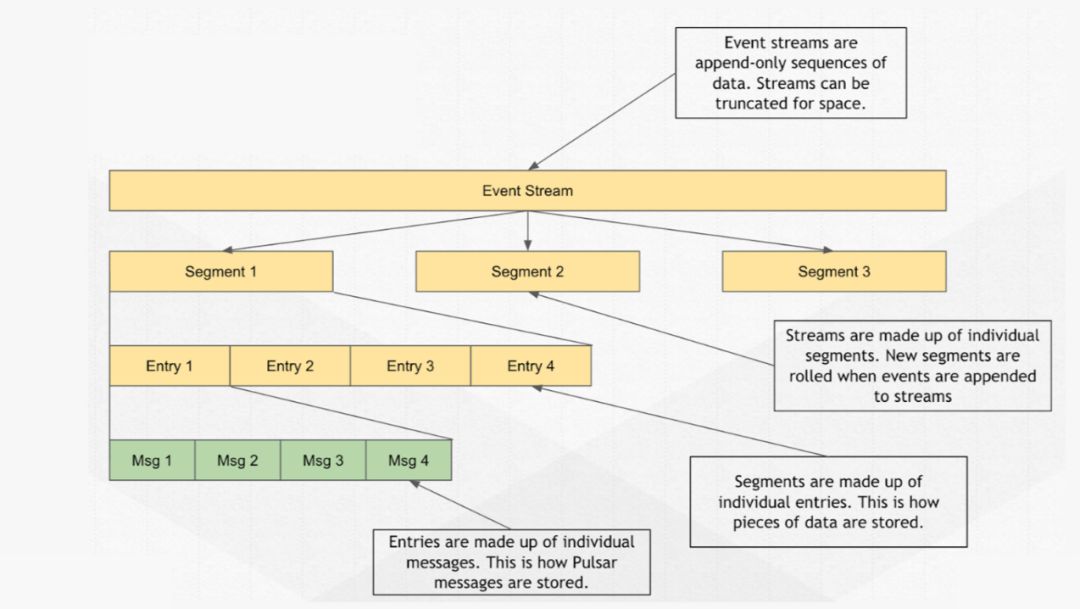
前边我们提到了 topic 里的分区,其实每个分区就是一个 stream(无穷无尽的数据流)。
Pulsar 给用户提供了 partition 的逻辑抽象,底层物理存储将逻辑的 partition 划分为多个分片(Segment),均匀存储在所有节点上。
利用 Apache BookKeeper 的存储,按照一定的规则生成新的 segment,比较灵活。
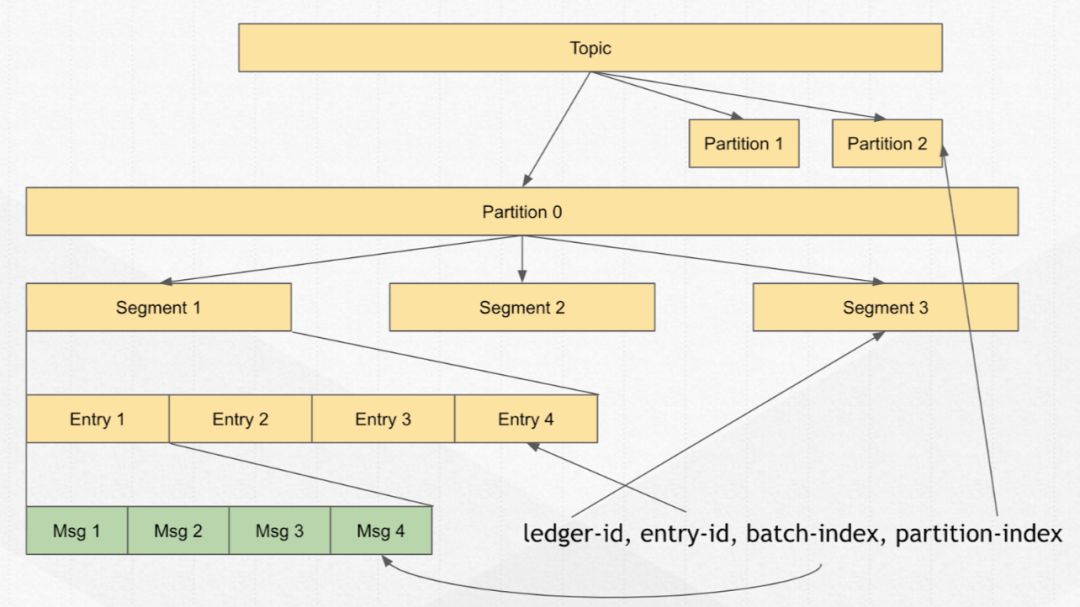
Segment 由多条 entry 组成,entry 就是真正意义上组织和存储的力度,entry 里是由更多的消息(Message)通过匹配进行批量组成的,从下图的架构层级就可以更容易地看出,需要从哪个层面进行相应的处理。
而最底层的 message 通常包含 Message ID,字段则一般由这几个:ledger-id(在哪个 segment)、entry-id(entry 在这个 segment 的位置)、batch-id(消息被匹配后的位置)、partition-index(消息在 topic 的哪个 partition)。
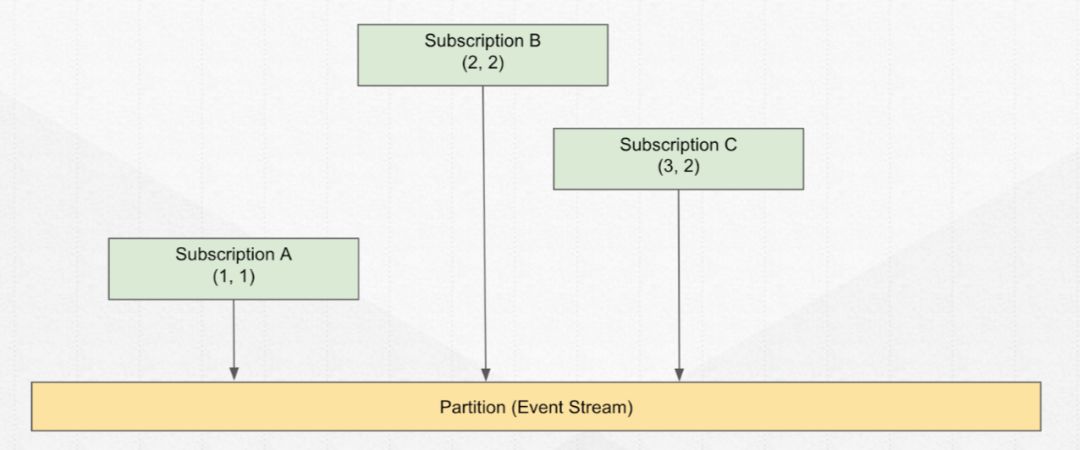
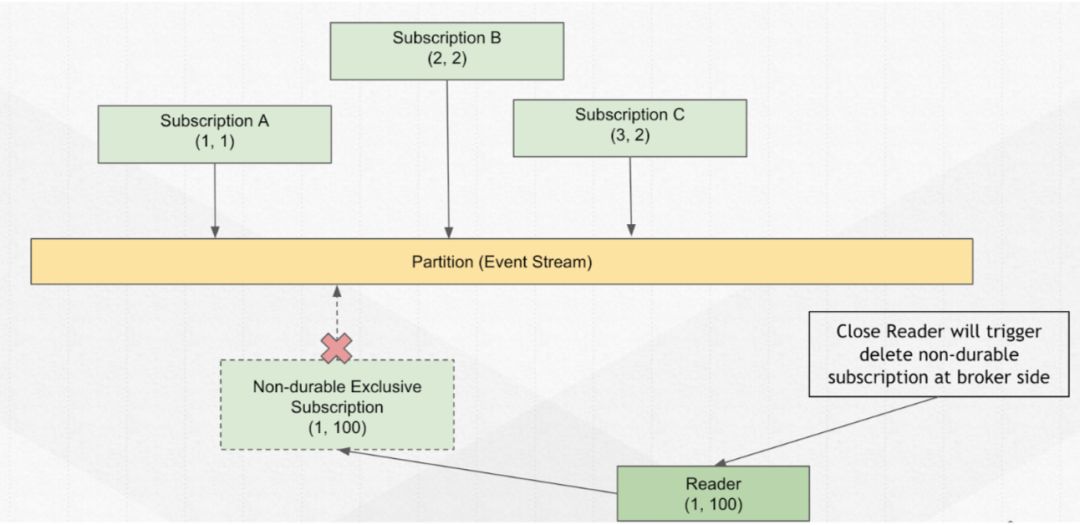
Cursor 在消费者端,代表了每个订阅组的消费状态。
所有订阅状态的管理,都给到了 broker,追踪每个订阅消费到了哪里,并存储到 cursor。
然后提供到客户端接口 Acknowledge Cumulatively,后续再进行相应的操作,比如移动或重置。
Cursor 相当于 Pulsar 管理你的消费状态,但是有时你不需要 Pulsar 帮你管理,所以就引入了 Reader 这个概念(Non-durable Cursor),即它的消费状态不被持久化的消费者进行消费。
它的消费状态只在内存里出现,比如当服务器重启时不会丢失。
Pulsar 与其他中间件还不一样的地方,就是它是一个层级化管理结构,也就是 Tenant,Tenant 下有 namespace(命名空间),然后再往下走就是 topic。
就像金字塔一样,层级镶嵌。
三层的结构有利于把 Pulsar 做成多租户系统进行管理公司等需要多层结构的组织。
这些策略的组织成为后期 Pulsar 运维和管理上更巧妙的一种方式。
Pulsar 为了支持统一化的消息平台,引入了 Topic Domain 的概念,默认消息是可持久化的。
所以通过这种层级化结构,可以使 Pulsar 更适配不同的应用场景。
本期直播介绍了 Pulsar 近期研发进展和基础概念,希望大家可以通过此次直播更加了解 Pulsar。
直播中涉及的 Slide,可以点击「阅读原文」获取。
如果你想获取直播的大纲及文字参考,可以参考 GitHub 上的 TGIP-CN Repo。
🙋♂️https://github.com/streamnative/tgip-cn/tree/master/episodes/001
由于时间有限,此次仅从 Event Streaming 和 Pub/Sub 层面进行了介绍,后续的内容我们也会再次为大家呈现。
同时本周末我们也会开启第二次线上直播,依旧是由郭斯杰大佬为大家带来关于
Message Lifecycle
相关的内容。敬请期待!

本文分享自微信公众号 - StreamNative(StreamNative)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/3742918/blog/4466541