Raft 是一种用来管理日志复制的一致性算法。为了提高理解性,Raft 将一致性算法分为了几个部分,例如领导选取(leader selection),日志复制(log replication)和安全性(safety),同时它使用了更强的一致性来减少了必须需要考虑的状态。本文我们主要介绍领导领导选取部分的内容。
备注:这里的一致性是强一致性。
1.服务器状态
每台服务器一定会处于三种状态:领导者、候选人、追随者,如下图所示。
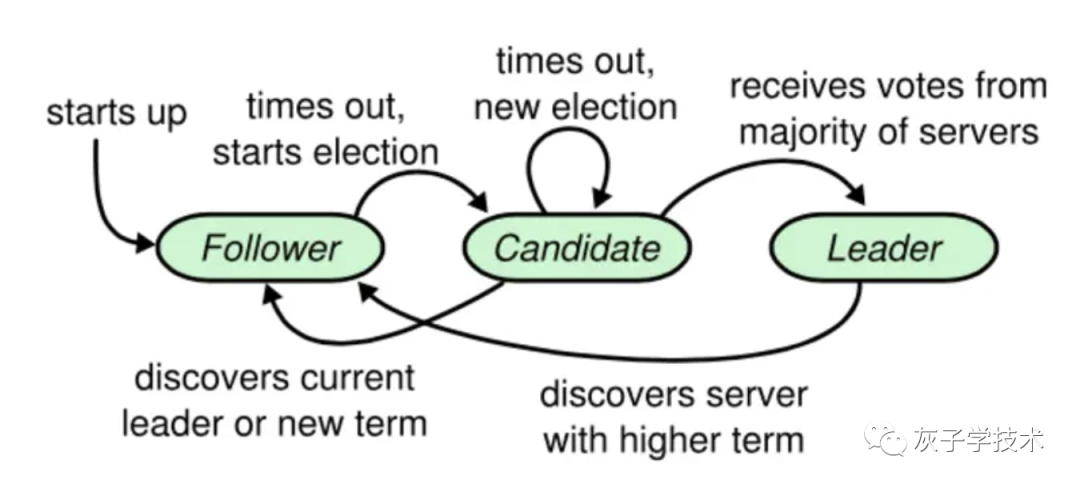
介绍如下:
追随者只响应其他服务器的请求。如果追随者没有收到任何消息,它会成为一个候选人并且开始一次选举。收到大多数服务器投票的候选人会成为新的领导人。领导人在它们宕机之前会一直保持领导人的状态。
2.任期(Term)
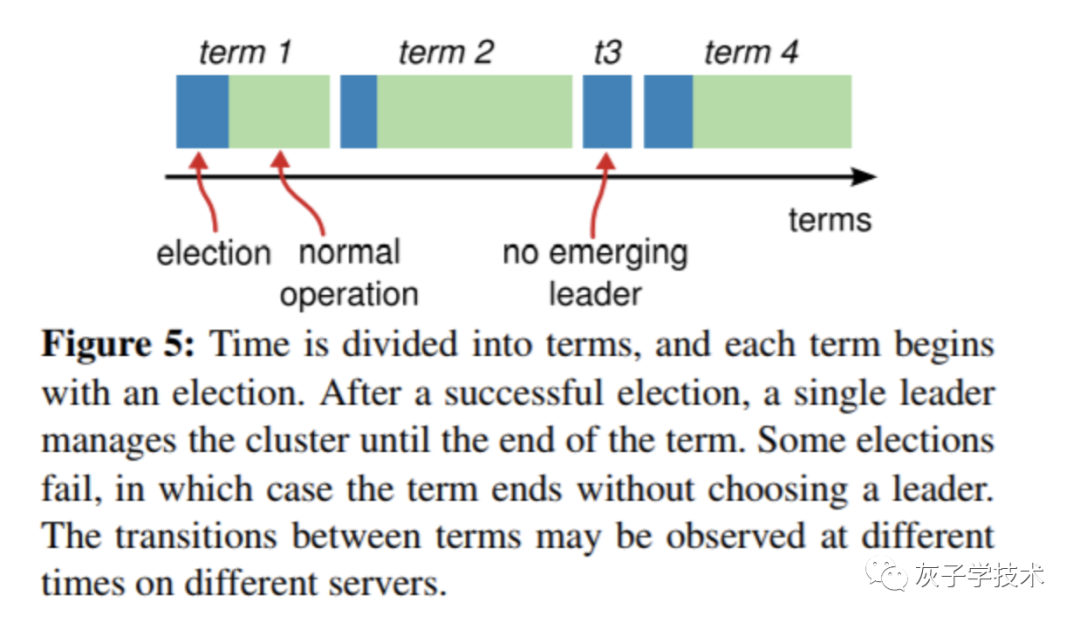
Raft 算法将时间划分成为任意不同长度的任期(term),任期用连续的数字进行表示。
每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。
在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。
Raft 算法保证在给定的一个任期最多只有一个领导人。
3.raft的leader选举过程
1)何时发起选举
集群开始时,所有服务器都是follower,当服务器在指定的时间之内没有收到leader或者candidate的有效消息时会发起选举。这个指定的时间被称为election timeout,是一个随机的值(比如200ms-500ms)。
备注:什么是有效消息?leader的有效消息是指心跳消息,candidate的有效消息是指投票消息。这里引入了两个状态变量,election timeout和heartbeat time interval(leader发送心跳间隔时间),要求heartbeat time interval<<min(election timeout),避免follower重新发起无谓的投票。
2)投票过程
1. follower递增自己的term,将自己的状态变为candidate,投票给自己。
2.向集群其它机器发起投票请求(RequestVote请求)。
3.超过集群一半服务器都同意,结束自己的candidate状态,变成leader。
4.立即向所有服务器发送心跳消息,之后按照心跳间隔时间发送心跳消息。
备注:任意一个term中的任意一个服务器只能投一次票,所有的candidate在此term已经投给了自己,那么需要另外的follower投票才能赢得选举。发现了其它leader并且这个leader的term不小于自己的term,状态转为follower,否则丢弃消息。
5.重新投票:没有服务器赢得选举,可能是由于网络超时或者服务器原因没有leader被选举,这种情况比较简单,超时之后重试。
特殊情况:
有一种情况被称为split votes,比如一个有三个服务器的集群中所有服务器同时发起选举,那么就不可能有leader被选举出来,此时如果超时之后重试很可能所有服务器又同时发起选举,这样永远不可能有leader被选举出来。raft处理这种情况是采用上文提到过的random election timeout,随机超了split votes发生的几率很小。
备注:
1.follower何时会同意:如果发起的投票请求包含的term大于等于当前term,并且日志信息不旧于candidate的日志信息,那么会同意。2.term如何更新:所有请求和响应的接收方在接收到更大的term时都必须更新自己的term,这保证了投票最终能够选出一个leader。
4. 使用例子
1)redis哨兵模式的选举:https://zhuanlan.zhihu.com/p/97492397
redis cluster集群模式master宕机之后,它的多个salve也是采用这种方式进行选举产生的master,不过这里是集群里面其他的master服务器进行的投票。
2)etcd 的选举可以参考:https://jimmysong.io/kubernetes-handbook/concepts/etcd.html
参考资料:
raft一致性论文译文:https://www.infoq.cn/article/raft-paper
https://www.jianshu.com/p/096ae57d1fe0
本文分享自微信公众号 - 灰子学技术(huizixueguoxue)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/4579381/blog/4885614