参考链接:https://blog.csdn.net/weixin_41519463/article/details/100863313


import torch
import torch.nn as nn
from pytorch_transformers import BertModel, BertConfig,BertTokenizer
#使用gpu
device0 = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#输入处理
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')#从预训练模型中加载tokenizer
# text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"#开始结束标记
# tokenized_text = tokenizer.tokenize(text) #用tokenizer对句子分词
# indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)#词在预训练词表中的索引列表
# segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# #用来指定哪个是第一个句子,哪个是第二个句子,0的部分代表句子一, 1的部分代表句子二
# print(tokenized_text)
# print(indexed_tokens)
# #转换成PyTorch tensors,作为BERT的输入
# tokens_tensor = torch.tensor([indexed_tokens])
# segments_tensors = torch.tensor([segments_ids])
texts = ["[CLS] Who was Jim Henson ? [SEP]",
"[CLS] Jim Henson was a puppeteer [SEP]"]
tokens, segments, input_masks = [], [], []
for text in texts:
tokenized_text = tokenizer.tokenize(text) # 用tokenizer对句子分词
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text) # 索引列表
tokens.append(indexed_tokens)
segments.append([0] * len(indexed_tokens))
input_masks.append([1] * len(indexed_tokens))#input_masks有什么用?
max_len = max([len(single) for single in tokens]) # 最大的句子长度
for j in range(len(tokens)):
padding = [0] * (max_len - len(tokens[j]))
tokens[j] += padding
segments[j] += padding
input_masks[j] += padding
# segments列表全0,因为只有一个句子1,没有句子2
# input_masks列表1的部分代表句子单词,而后面0的部分代表paddig,只是用于保持输入整齐,没有实际意义。
# 相当于告诉BertModel不要利用后面0的部分
#原来是这个意思,明白了!
# 转换成PyTorch tensors
tokens_tensor = torch.tensor(tokens).to(device0)
segments_tensors = torch.tensor(segments).to(device0)
input_masks_tensors = torch.tensor(input_masks).to(device0)
#构造模型
class TextNet(nn.Module):
def __init__(self, code_length): #code_length为fc映射到的维度大小
super(TextNet, self).__init__()
# {
# "attention_probs_dropout_prob": 0.1,
# "hidden_act": "gelu",
# "hidden_dropout_prob": 0.1,
# "hidden_size": 768,
# "initializer_range": 0.02,
# "intermediate_size": 3072,
# "max_position_embeddings": 512,
# "num_attention_heads": 12,
# "num_hidden_layers": 12,
# "type_vocab_size": 2,
# "vocab_size": 30522
# }#加载模型为什么要传hidden_size??隐层数是在预训练的时候就确定了啊。
#12-layer, 768-hidden, 12-heads, 110M parameters
#如果已经下载到了本地
# modelConfig = BertConfig.from_pretrained('bert-base-uncased-config.json')#这指定的算是超参数?
# self.textExtractor = BertModel.from_pretrained(
# 'bert-base-uncased-pytorch_model.bin', config=modelConfig)
#访问外网下载模型
modelConfig = BertConfig.from_pretrained('bert-base-uncased')
self.textExtractor = BertModel.from_pretrained('bert-base-uncased', config=modelConfig)
embedding_dim = self.textExtractor.config.hidden_size#768,
#定义模型使用的
self.fc = nn.Linear(embedding_dim, code_length)#32
self.tanh = torch.nn.Tanh()#用tanh有什么好处呢?
def forward(self, tokens, segments, input_masks):
output=self.textExtractor(tokens, token_type_ids=segments,#句子id和mask
attention_mask=input_masks)
#对于单个句子分类任务
text_embeddings = output[0][:, 0, :]#outputs[0] # The last hidden-state is the first element of the output tuple
#output[0](batch size, sequence length, model hidden dimension)
#即取所有的batch size,第一行的所有hidden输出
features = self.fc(text_embeddings)
features=self.tanh(features)
return features
#——————提取文本特征——————
textNet = TextNet(code_length=32)
textNet.to(device0)
text_hashCodes = textNet(tokens_tensor , segments_tensors , input_masks_tensors) #text_hashCodes是一个32-dim文本特征
print(text_hashCodes)
1.在服务器上运行的时候,指定到GPU上训练:
#使用gpu
device0 = torch.device("cuda" if torch.cuda.is_available() else "cpu")但是提示:
Found GPU1 NVS 315 which is of cuda capability 2.1.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability that we support is 3.5.
warnings.warn(old_gpu_warn % (d, name, major, capability[1]))但是在服务器上,我查看可用的GPU的时候,却显示1080的:
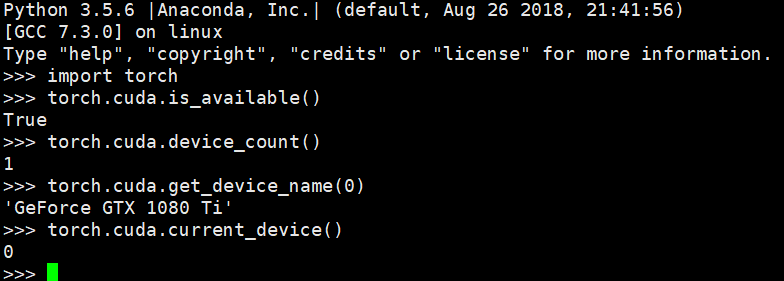
真是蜜汁结果。
但随之我又输出
device0 = torch.device("cuda:0")
print(device0)
print(torch.cuda.get_device_name(0))结果:
cuda:0
GeForce GTX 1080 Ti虽然仍旧有以上的warning,但是使用的是1080没问题了,所以不用它了。
实验输出为:
tensor([[-0.2077, -0.3166, -0.1718, 0.0716, -0.2770, -0.4189, 0.2297, -0.1312,
0.0529, -0.4312, -0.4459, -0.0964, 0.0368, -0.1870, -0.1538, 0.3730,
-0.1625, 0.4385, -0.0500, -0.0737, -0.1764, -0.0373, 0.0415, -0.3696,
-0.1461, 0.1578, 0.3311, -0.2346, -0.3398, 0.4256, 0.1504, 0.0888],
[-0.1483, -0.0490, -0.1577, -0.2698, -0.2393, -0.2391, 0.0198, -0.0661,
0.0709, -0.4828, -0.3091, -0.1409, 0.1786, -0.2377, -0.2294, 0.1859,
-0.0221, 0.2809, -0.2025, 0.0664, -0.0588, 0.0449, 0.1962, -0.3905,
-0.3253, -0.0885, 0.2716, -0.3307, -0.2973, 0.5517, 0.1286, -0.0632]],
device='cuda:0', grad_fn=<TanhBackward>)#应该它之后就可以经过softmax来分类属于哪一类?应该不是分类问题
以上实验结果就是对两个句子的特征提取~
来源:oschina
链接:https://my.oschina.net/u/4357584/blog/3345641