作者:一枝花算不算浪漫[1]
原文地址:https://www.cnblogs.com/wang-meng/p/ae6d1c4a7b553e9a5c8f46b67fb3e3aa.html
小结:
回表:回到主键索引树搜索的过程,我们称为回表。
覆盖索引:就是 select 的数据列只用从索引中就能够取得,不必从数据表中读取。简单点说就是你要查的数据索引里都有,一次搞定,美滋滋 😎。
延迟关联:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。
1. 前言
上周新系统改版上线,上线第二天就出现了较多的线上慢 sql 查询,紧接着 dba 给出了定位及解决方案,这里较多的是使用延迟关联去优化。
而我对于这个延迟关联也是第一次听说(o(╥﹏╥)o),所以今天一定要学习并产出一篇学习笔记。(^▽^)
2. 回表
我们都知道 InnoDB 采用的 B+ tree 来实现索引的,索引又分为主键索引(聚簇索引)和普通索引(二级索引)。
那么我们就来看下基于主键索引和普通索引的查询有什么区别?
-
如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+树; -
如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
举个栗子:
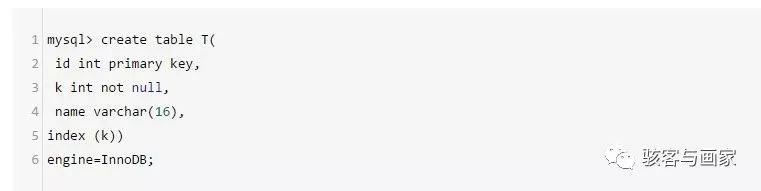
可以看出我们有一个普通索引 k,那么两颗 B+树的示意图如下:
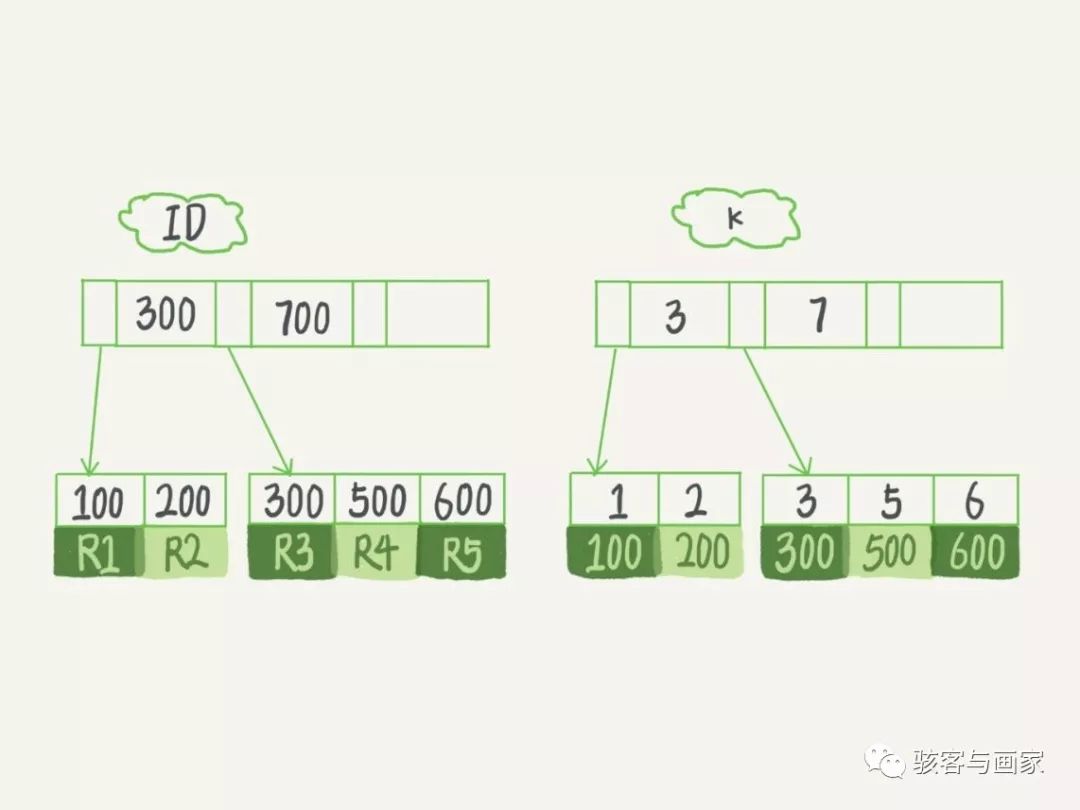
(注:图来自极客时间专栏)
当我们查询 select \* from T where k=5 其实会先到 k 那个索引树上查询 k = 5,然后找到对应的 id 为 500,最后回表到主键索引的索引树找返回所需数据。
如果我们查询**select id from T where k=5** 则不需要回表就直接返回。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
3. 覆盖索引
-
解释一:就是 select 的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。 -
解释二:索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。 -
解释三:是非聚集组合索引的一种形式,它包括在查询里的 Select、Join 和 Where 子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select 子句]与查询条件[Where 子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。 -
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以 MySQL 只能使用 B-Tree 索引做覆盖索引 -
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在 EXPLAIN 的 Extra 列可以看到“Using index”的信息
概念如上,这里我们还是用例子来说明:
(注:图来自极客时间专栏)
现在,我们一起来看看这条 SQL 查询语句的执行流程:select * from T where k between 3 and 5
-
在 k 索引树上找到 k=3 的记录,取得 ID = 300; -
再到 ID 索引树查到 ID=300 对应的 R3; -
在 k 索引树取下一个值 k=5,取得 ID=500; -
再回到 ID 索引树查到 ID=500 对应的 R4; -
在 k 索引树取下一个值 k=6,不满足条件,循环结束。
在这个过程中,**回到主键索引树搜索的过程,我们称为回表。**可以看到,这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)。
在这个例子中,由于查询结果所需要的数据只在主键索引上有,所以不得不回表。那么,有没有可能经过索引优化,避免回表过程呢?
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
需要注意的是,在引擎内部使用覆盖索引在索引 k 上其实读了三个记录,R3~R5(对应的索引 k 上的记录项),但是对于 MySQL 的 Server 层来说,它就是找引擎拿到了两条记录,因此 MySQL 认为扫描行数是 2。
4. 延迟关联
上面介绍了那么多 其实是在为延迟关联做铺垫,这里直接续上我们本次慢查询的 sql:
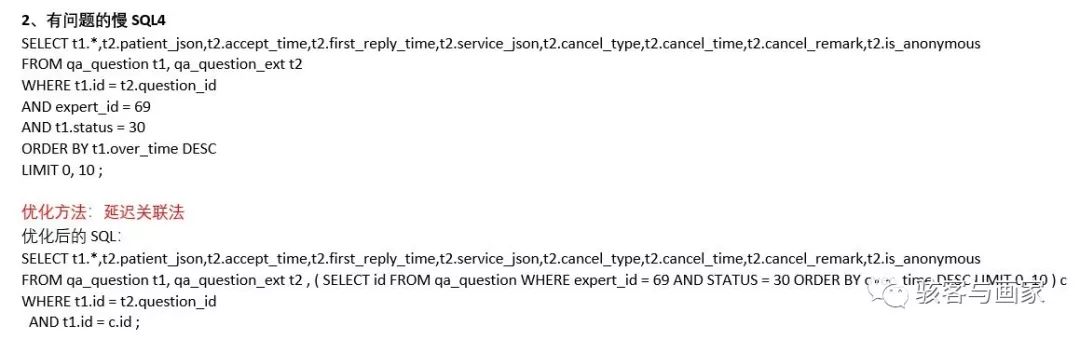
我们都知道在做分页时会用到 Limit 关键字去筛选所需数据,limit 接受 1 个或者 2 个参数,接受两个参数时第一个参数表示偏移量,即从哪一行开始取数据,第二个参数表示要取的行数。如果只有一个参数,相当于偏移量为 0。
当偏移量很大时,如 limit 100000,10 取第 100001-100010 条记录,mysql 会取出 100010 条记录然后将前 100000 条记录丢弃,这无疑是一种巨大的性能浪费。
这个 sql 并没有利用索引覆盖,因为所要 select 的字段不全都在索引上,每次根据二级索引(expert_id) 查询到一条记录,都要再走一遍主键索引去表里找出所需要的其他列,速度自然慢。
当有这种写法时,我们可以采用延迟关联来进行优化,重点关注:SELECT id FROM qa_question WHERE expert_id = 69 AND STATUS = 30 ORDER BY over_time DESC LIMIT 0, 10, 这里其实利用了索引覆盖,where 条件后的 expert_id 是有添加索引的,这里查询 id 可以避免回表,大大提升效率。
5. 结语
工作中会遇到各种各样的问题,对于一个研发来说最重要的是能够从这些问题中学到什么。好久没有写博客了,究其原因还是自己变得懒惰了。( ̄ェ ̄)
最后以《高性能 Mysql》中的一段话结束:

参考资料
一枝花算不算浪漫: https://www.cnblogs.com/wang-meng/
本文分享自微信公众号 - 骇客与画家(hacker-and-painter)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/3861898/blog/4352101