本文是《剖析Spark数据分区》系列文章的第三篇,本篇我们将分析Spark streaming,TiSpark中的数据分区。
1. Kafka +Spark Streaming

图 1
Spark Streaming从Kafka接收数据,转换为Spark Streaming中的数据结构DStream即离散数据流。
2)使用Direct拉取的新方法(Spark 1.3引入);
receiver模式的并行度由spark.streaming.blockInterval决定,默认是200ms。
receiver模式接收block.batch数据后会封装到RDD中,这里的block对应RDD中的partition。
减少spark.streaming.Interval参数值,会增大DStream中的partition个数。
建议spark.streaming.Interval最低不能低于50ms。
Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
DirectKafkaInputDStream定期生成的RDD的类型是KafkaRDD。
它会根据从初始化时接收的offset信息参数,生成KafkaRDDPartition分区;每个分区对应着Kafka的一个topic partition 的一段数据,这段数据的信息OffsetRange表示, 它保存了数据的位置。
图 4
下面我们详细分析DirectKafkaInputDStream的compute方法:
Partition的计算方法是为topic的每一个partition创建一个OffsetRange,所有的OffsetRange生成一个KafkaRDD。
下面我们分析KafkaRDD的getPartitions方法:
每个OffsetRange生成一个Partition。
如何增大RDD的分区数,让每个partition处理的数据量增大?
通过源码分析,可通过调小Kafka消息中Topic的分区数目;想要增加RDD的并行度,可通过调大Kafka消息中Topic的分区数目。
TiDB Server负责接收SQL请求,处理SQL相关的逻辑,并通过PD找到存储计算所需要的TiKV地址,与TiKV交互获取数据,最终返回结构;
TiDB Server并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件如LVS, HAProxy,F5等对外提供的接入地址。
TiKV负责数据存储,从外部看是一个分布式的提供事物的Key-Value存储引擎。
存储数据的基本单位是Region,每个Region负责存储一个Key Ra
nge (从StartKey到EndKey的左闭右开区间) 区间的数据,每个TiKV节
点会负责多个Region,数据在多个TiKV之间的负载均衡由PD调度,也是以Region为单位进行调度。
TiDB 的数据分布是以 Region 为单位的。一个 Region 包含了一个范围内的数据,通常是 96MB 的大小,Region 的 meta 信息包含了 StartKey 和 EndKey 这两个属性。
当某个 key >= StartKey && key < EndKey 的时候:
我们就知道了这个 key 所在的 Region,然后我们就可以通过查找该 Region 所在的 TiKV 地址,去这个地址读取这个 key 的数据。
获取 key
所在的 Region, 是通过向 PD 发送请求完成的。
GetRegion(ctx context.Context, key []byte) (*metapb.Region, *metapb.Peer, error)
通过调用这个接口,我们就可以定位这个 key 所在的 Region 了。
如果需要获取一个范围内的多个 Region:我们会从这个范围的 StartKey 开始,多次调用 GetRegion 这个接口,每次返回的 Region 的 EndKey 做为下次请求的 StartKey,直到返回的 Region 的 EndKey 大于请求范围的 EndKey。
以上执行过程有一个很明显的问题:就是我们每次读取数据的时候,都需要先去访问 PD,这样会给 PD 带来巨大压力,同时影响请求的性能。
为了解决这个问题:tikv-client 实现了一个
RegionCache 的组件,缓存 Region 信息。
图 9
当需要定位 key 所在的 Region 的时候:如果 RegionCache 命中,就不需要访问 PD 了。
RegionCache 内部有两种数据结构保存 Region信息:
1) map;
用 map 可以快速根据 region ID 查找到 Region,
2)b-tree;
用 b-tree 可以根据一个 key 找到包含该 key 的 Region。
严格来说:PD 上保存的 Region 信息,也是一层 cache;真正最新的 Region 信息是存储在 tikv-server 上的,每个 tikv-server 会自己决定什么时候进行 Region 分裂。
在 Region 变化的时候,把信息上报给 PD,PD 用上报上来的 Region 信息,满足 tidb-server 的查询需求。
当我们从 cache 获取了 Region 信息,并发送请求以后, tikv-server 会对 Region 信息进行校验,确保请求的 Region 信息是正确的。
如果因为 Region 分裂,Region 迁移导致了 Region 信息变化。请求的 Region 信息就会过期,这时 tikv-server 就会返回 Region 错误。
遇到了 Region 错误,我们就需要清理 RegionCache,重新获取最新的 Region 信息,并重新发送请求。
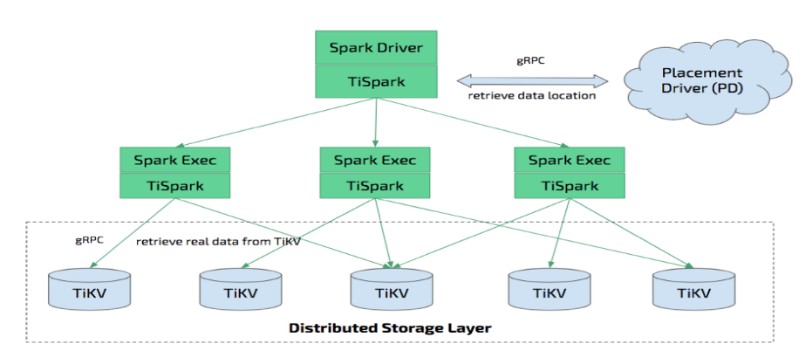
TiSpark深度整合了Spark Catalyst引擎,使得Spark能够高效的读取TiKV中存储的数据进行分布式计算。
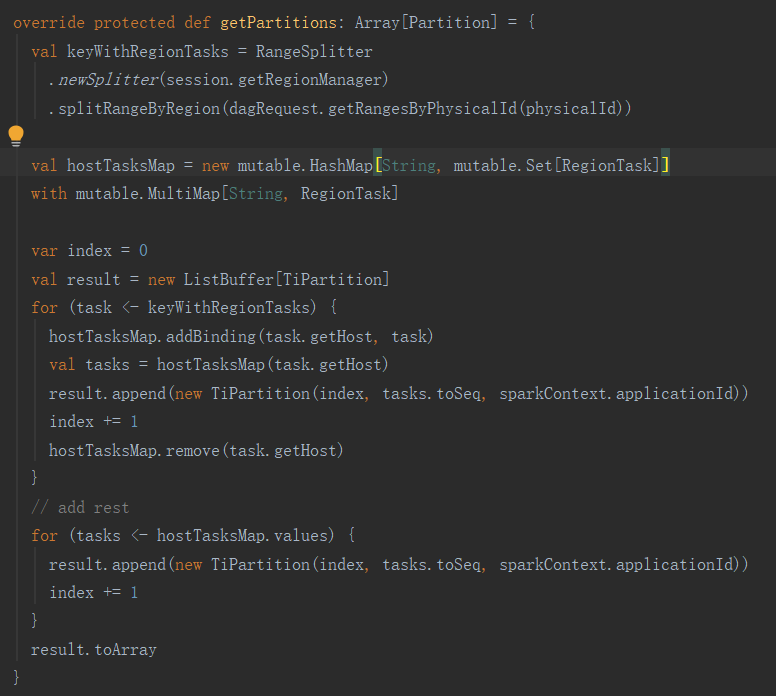
下面分析TiRDD中的getPartitions方法:
首先通过splitRangeByRegion获取keyWithRegionTasks, 对于每一个RegionTask创建一个TiPartition。
可见TiSpark的Partition分区数目与TiKV的region数目一致,如果想要提高TiSpark任务的并行度,可修改如下两个参数值:
通过以上种种情况的分析,只要我们能正确的认识在各种场景下分区与task的关系,进而加以实际的对影响分区的参数调优,也可以让数据量大的任务也能快起来,同时能清楚的解答数据分析师的问题。
☆ END ☆
OPPO互联网基础技术团队招聘一大波岗位,涵盖C++、Go、OpenJDK、Java、DevOps、Android、ElasticSearch等多个方向,请点击这里查看详细信息及JD。
本文分享自微信公众号 - OPPO互联网技术(OPPO_tech)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/4273516/blog/4550058

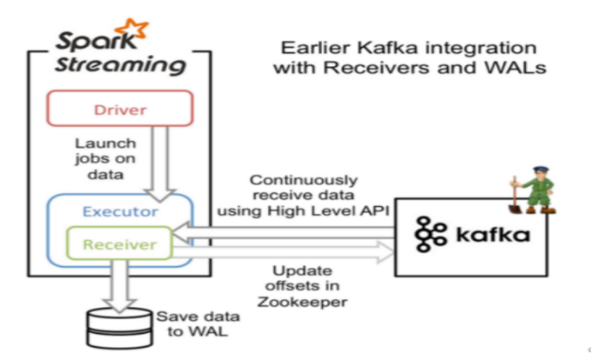

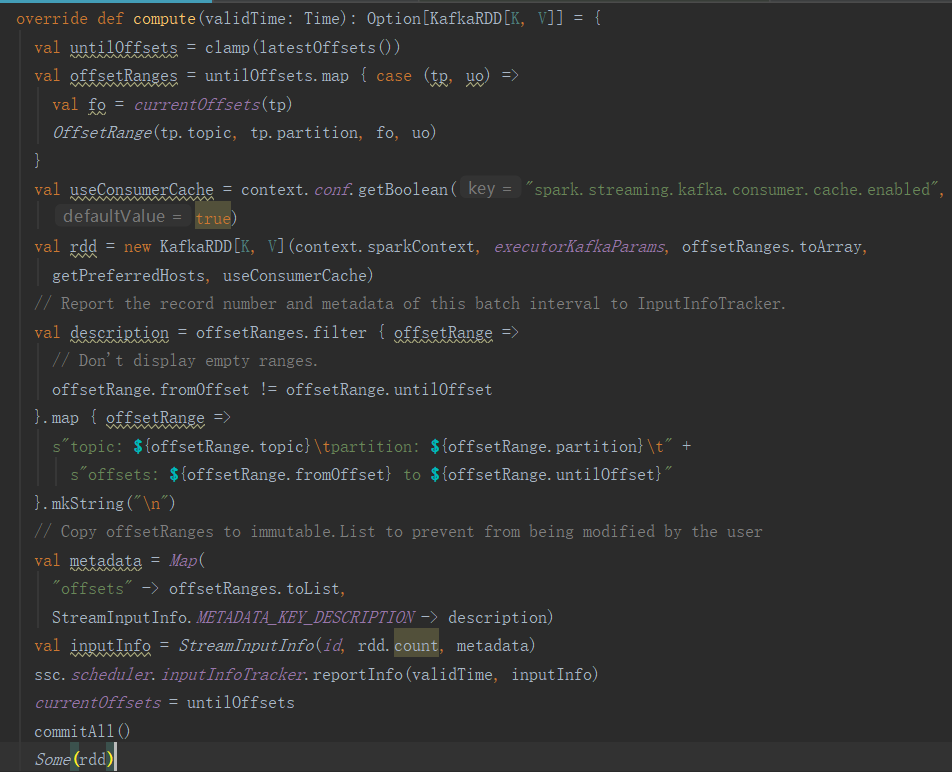


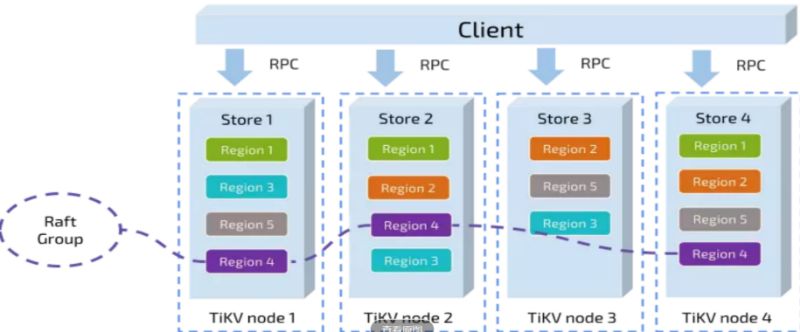
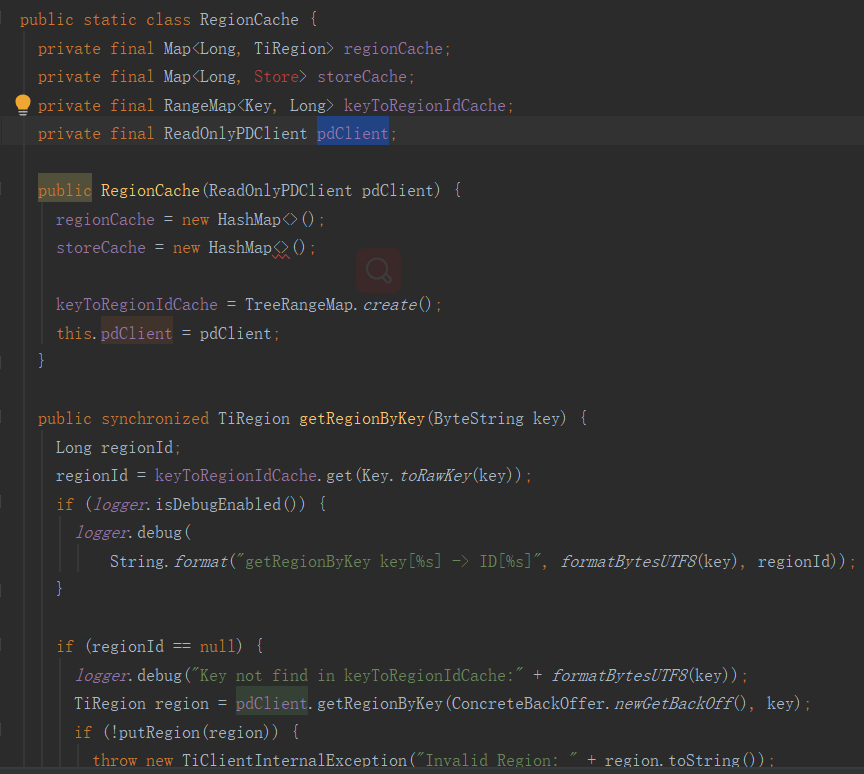 图 9
图 9