最近太忙一直没更新,也没空写的特别细,就把Hotchips今年比较有意思的先一股脑儿放上来,我想到哪里写到哪里。
Marvell: ARM based server
Marvell这个应该做了很久了,现在其他公司也不搞了,不清楚会走多远。之前我是不太看好这类东西的,但是苹果都开始做M1了,搞不好这个路子真的有未来。
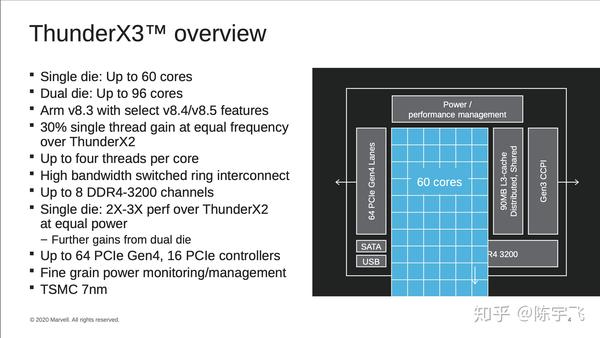

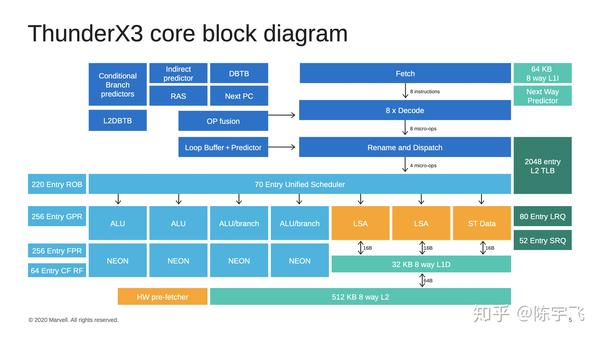
也没什么特别的心意,除了发现,诶,居然还在做,牛啊。
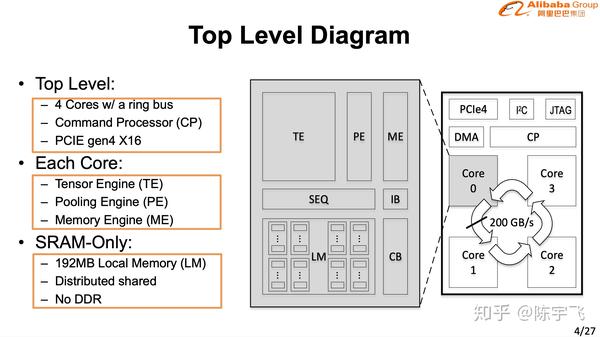
平头哥的玄铁910
之前也有人介绍过了,我就先放个链接
如何看待阿里巴巴旗下 「平头哥」发布首枚芯片 :玄铁 910? www.zhihu.com

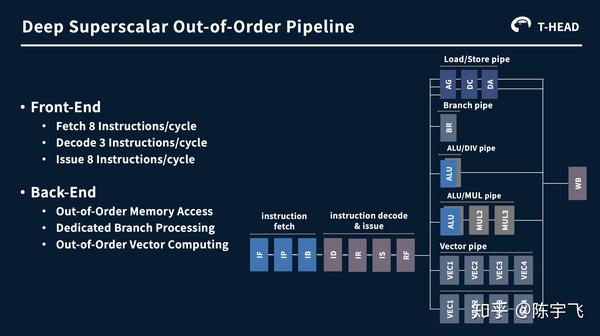
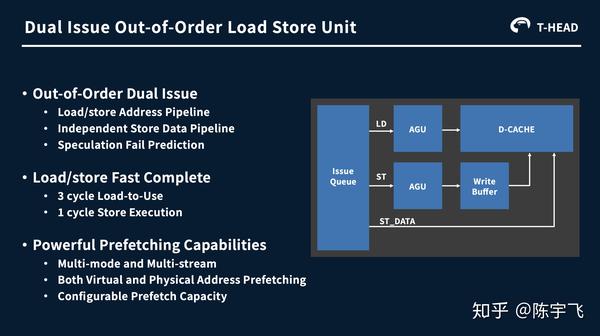

这么宽的vector instruction功耗没问题么,如果是为了AI不应该扔给另外一个专门做AI小东西做么。

总的感觉不是特别明确具体应用场景是啥,好像也买不到,但是看着还挺有意思的。要是能说出更具体的应用场景,然后在这个场景下如何吊打别人,可能更有利于大家理解吧。
哈佛大学的Baysian Inference Accelerator
哈佛大学做这些的感觉路子一直很野啊。


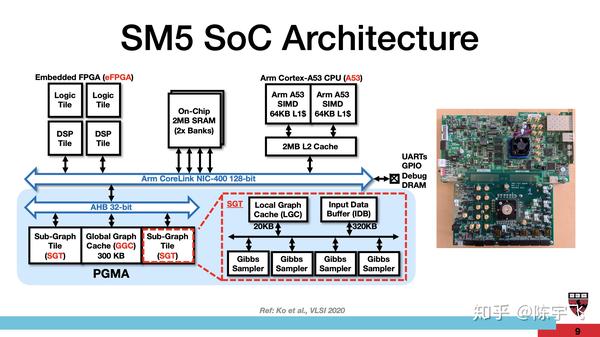
实现上这个PGMA是优化的实现,一个大的cache加上一堆Gibbs Sampler。忘记Gibbs sampling是干啥的,这里复习
http://www.mit.edu/~ilkery/papers/GibbsSampling.pdf www.mit.edu
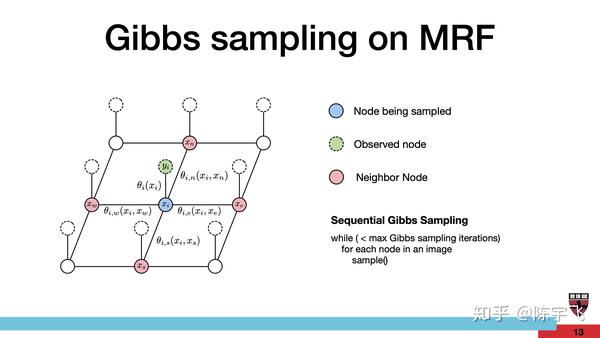

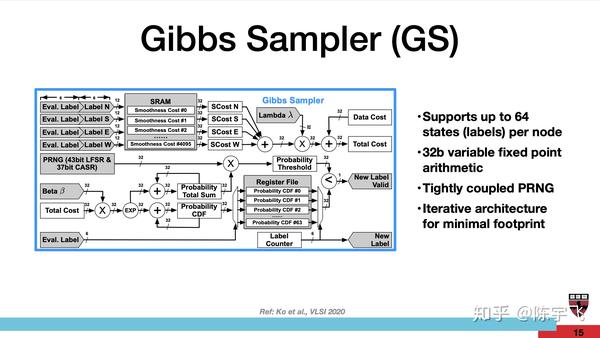
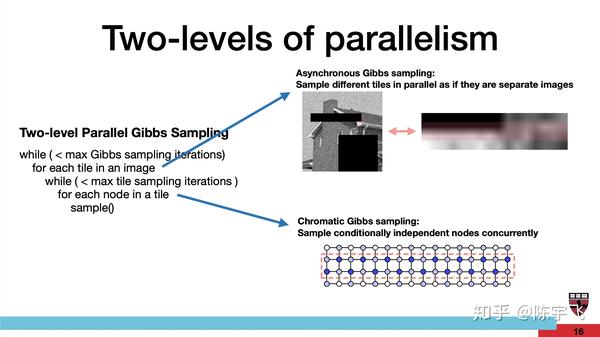
这个创意的硬件实现主要应该是所谓的Chromatic Gibbs sampling。这个想法好像之前就发出来了。
http://proceedings.mlr.press/v15/gonzalez11a/gonzalez11a.pdf proceedings.mlr.press具体感觉还挺有意思的把,说是快了很多,但是后面benchmark比的都是embedding platform。具体应用场景里面Bayesian的东西不多,几个GPU估计也就顶过去了,所以这个东西可能还是好玩居多吧。
Deepmind: AI Research at Scale - Opportunities on the Road Ahead
甲方来提需求来了,我觉得几个点还挺有意思的
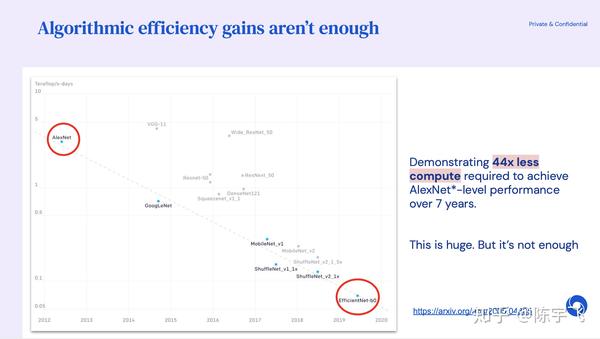
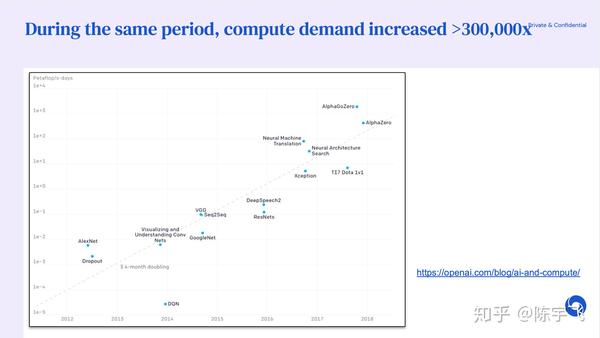
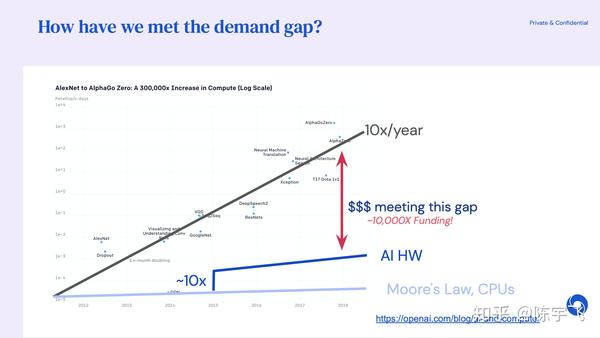
需求正在爆发,算法能优化的东西非常有限,只能靠特殊的硬件去支持这些研究。

整体系统的utilization还是很低,当成系统工程来优化还有很多东西可以做。
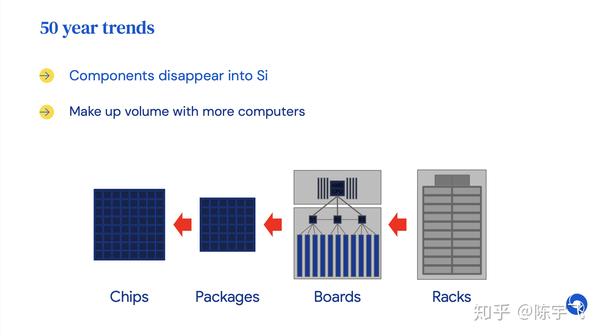


这个老哥讲的还是挺有意思的,大家有空可以看看全文。
百度的昆仑

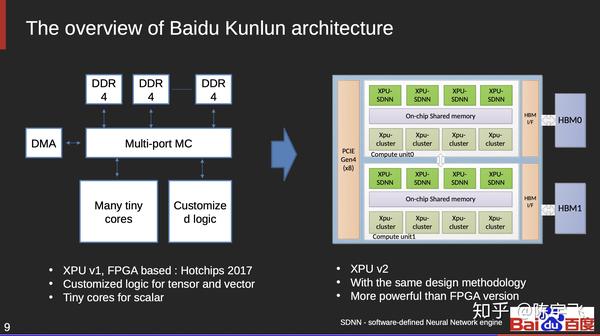
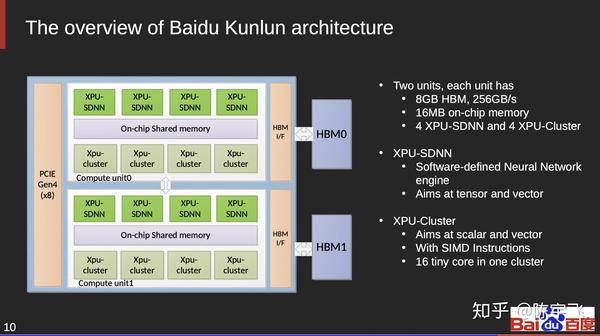
主要拿来做inference的,TDP 150W也不低,没有什么意料之外的地方。
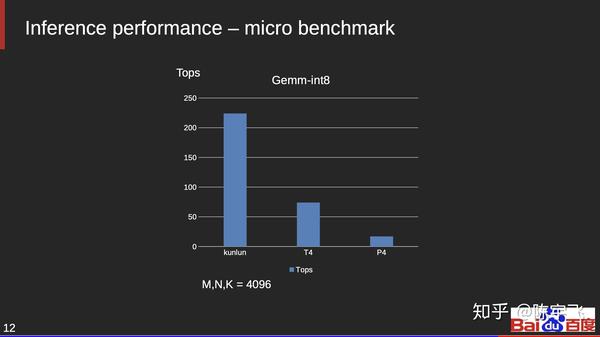
阿里的含光
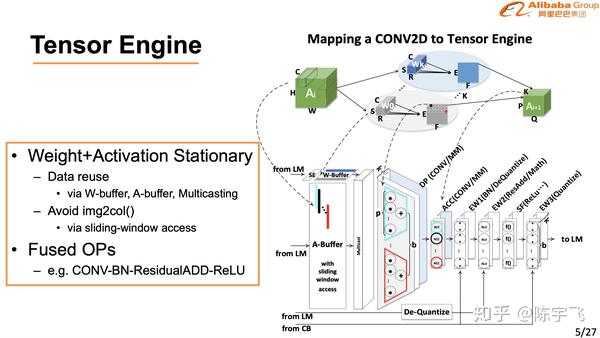
上图那个梯形是含光效率高的地方。
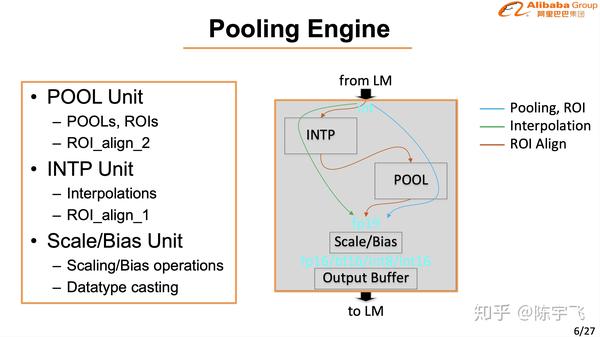
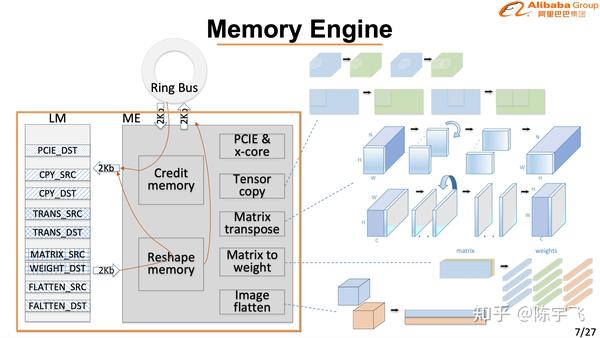
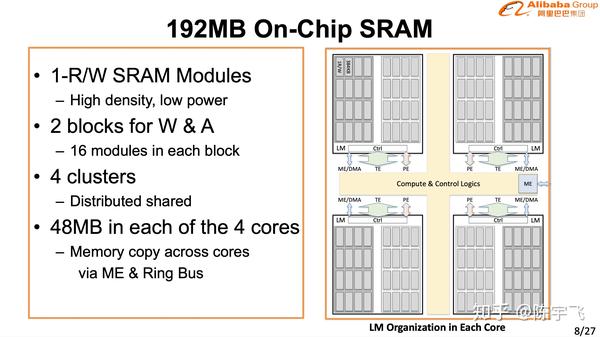
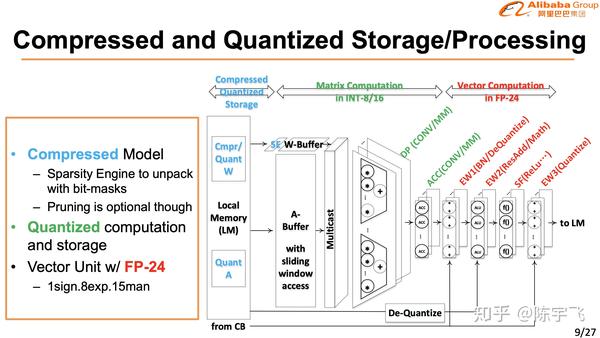
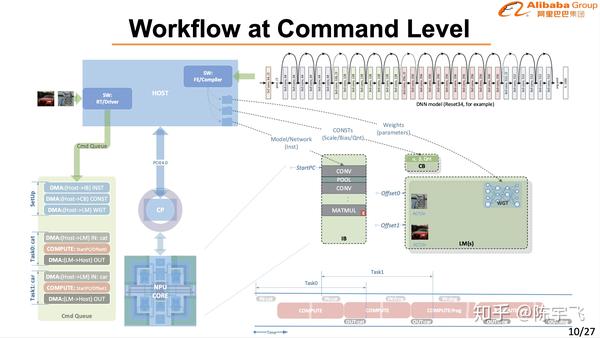
讲的很细也做的很好,在CV的场景下确实已经是最好的解决方案了。下次慢慢细讲。
Lightmatter: Silicon Photonics for Artificial Intelligence Acceleration
这个解决方案不单是用Silicon Photonic做芯片之间的通讯,而是连计算的方案都是光学的。

中间主要是讲现在芯片太热了。
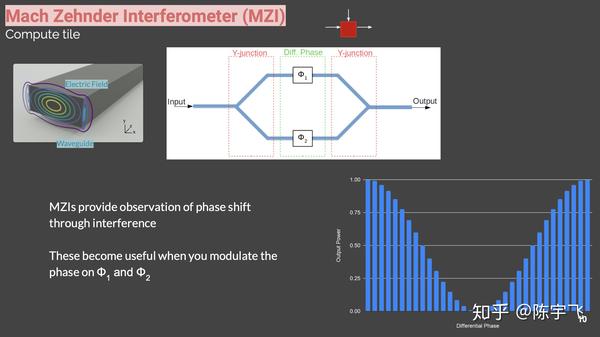


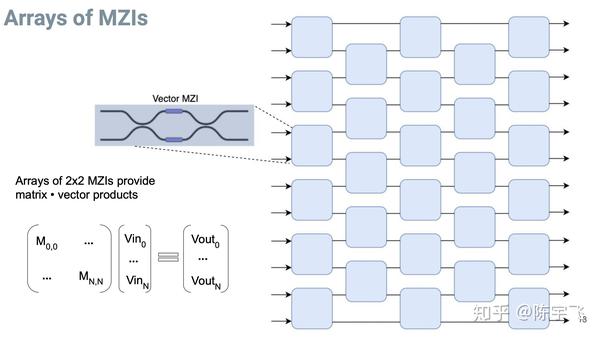
用一堆mdi堆出来了可以做矩阵运算。
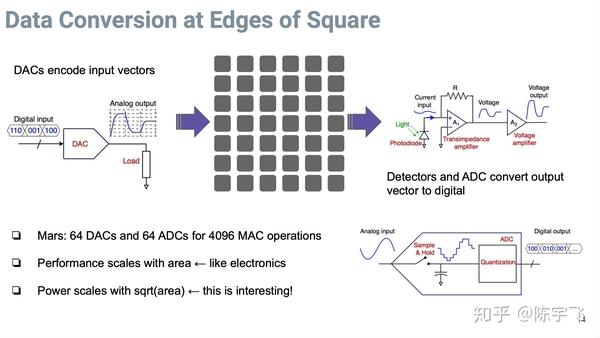
最后得转换成电子信号,但是转换电子型号部分的器件只是沿着这个输入跟输出的边来安排的,所以最后写到 power = sqrt(area)
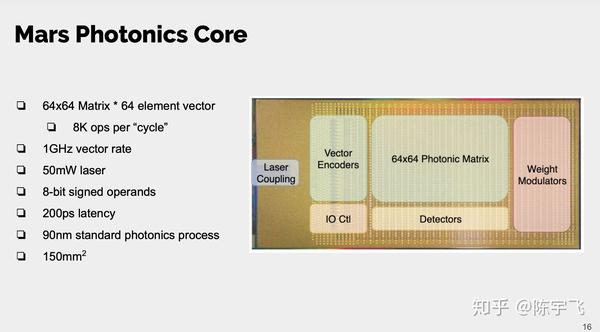
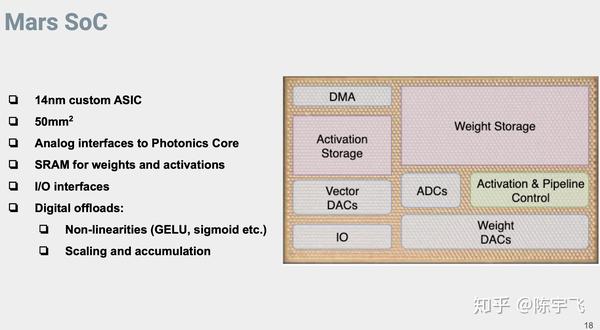
这里写到非限行的东西都得是现有的电子器件来做,所以应该是不适合训练,单纯适合推理。
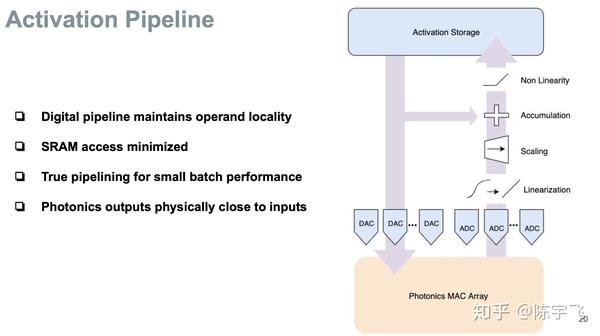
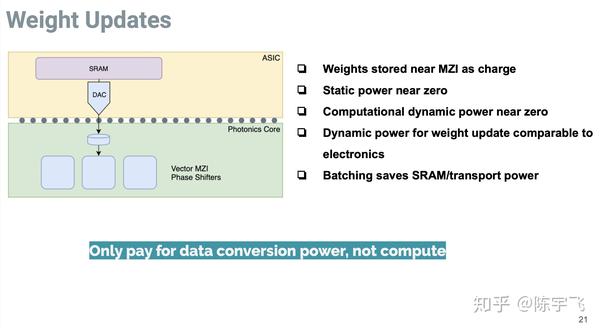
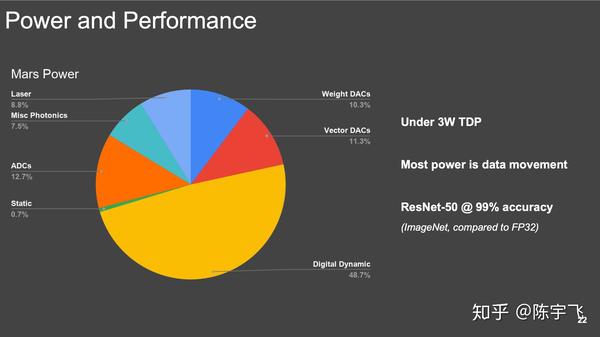
总共只有3W TDP也是很清奇了。这个不单纯是热量的问题,能省电费也是好事。具体没给出相对速度和能效比,但是也算是最新路线了,跟之前所有看到的都最不一样。
总的来说今年hotchips还是挺好玩的,各种正常跟非正常路线都有。有空好好的挖一挖具体每个东西的细节。
来源:oschina
链接:https://my.oschina.net/u/4416988/blog/4754713