Hive 简介
Hive 官方文档:
Hive 产生的背景:
- 在使用MapReduce进行编程的时候,会发现实现一个简单的功能例如WordCount都需要编写不少的代码,可想而知如果实现一个复杂点的应用所需的开发和维护成本就会非常高,为了解决MapReduce编程的不便性,Hive才得以诞生。
- 另外一点就是HDFS上的文件缺少Schema,没法通过SQL去对HDFS上的数据去进行查询,只能通过MapReduce去操作。因此以往可以通过SQL完成的数据统计就没法在HDFS上完成,这会导致上手门槛高。
Hive是什么:
- 由Facebook开源,最初用于解决海量结构化的日志数据统计问题
- 是一个构建在Hadoop之上的数据仓库,可以对已经在存储(HDFS)中的数据进行结构化的映射。并提供了一个命令行工具和JDBC驱动程序来连接并操作Hive
- Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同),使用SQL方便了分布式存储中大型数据集的读取、写入和管理
- 通常用于进行离线数据处理,早期底层采用MapReduce,现在底层支持多种不同的执行引擎
- 支持多种不同的压缩格式(gzip、lzo、snappy、bzip2等)、存储格式(TextFile、SequenceFile、RCFile、ORC、Parquet等)以及自定义函数
为什么要使用Hive:
- 简单、容易上手,提供了类似SQL查询语言HQL,只要有SQL基础就能上手
- 为超大数据集设计的计算/存储扩展能力(MR计算,HDFS存储)
- 统一的元数据管理,可与Presto/Impala/SparkSQL等共享数据
Hive体系架构图: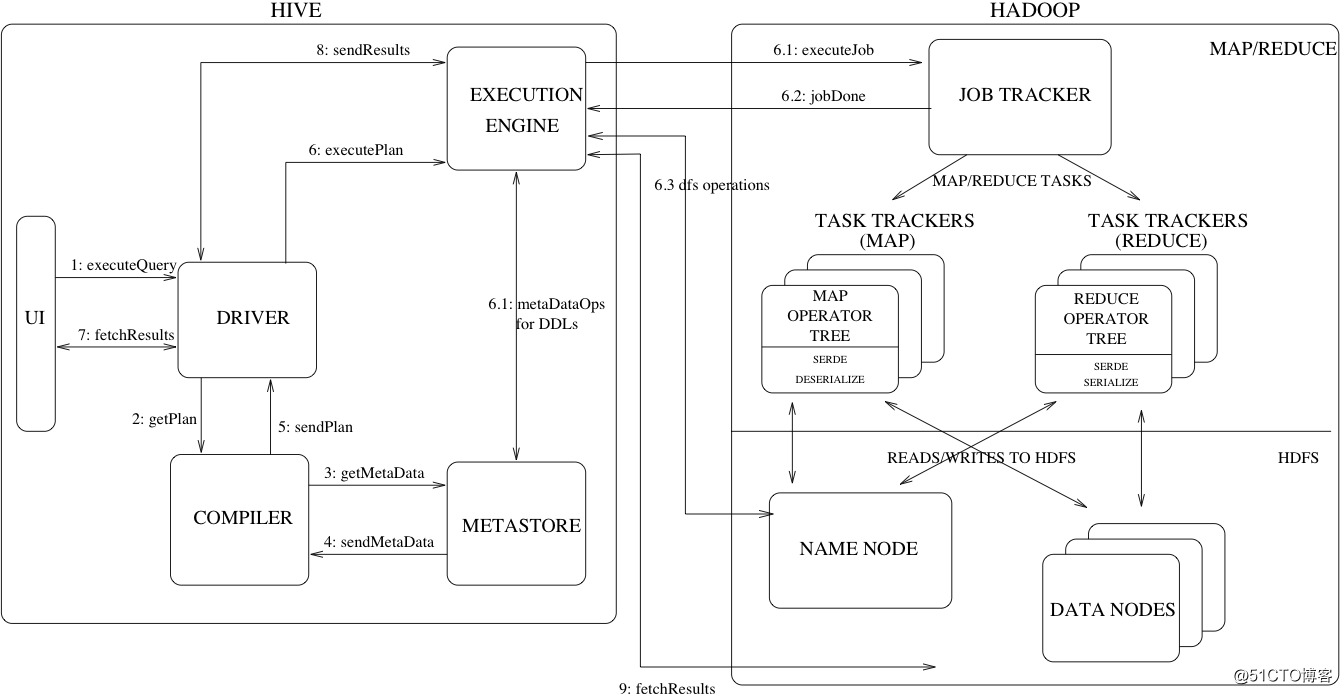
- 图片来自官方文档
部署架构 - 生产环境: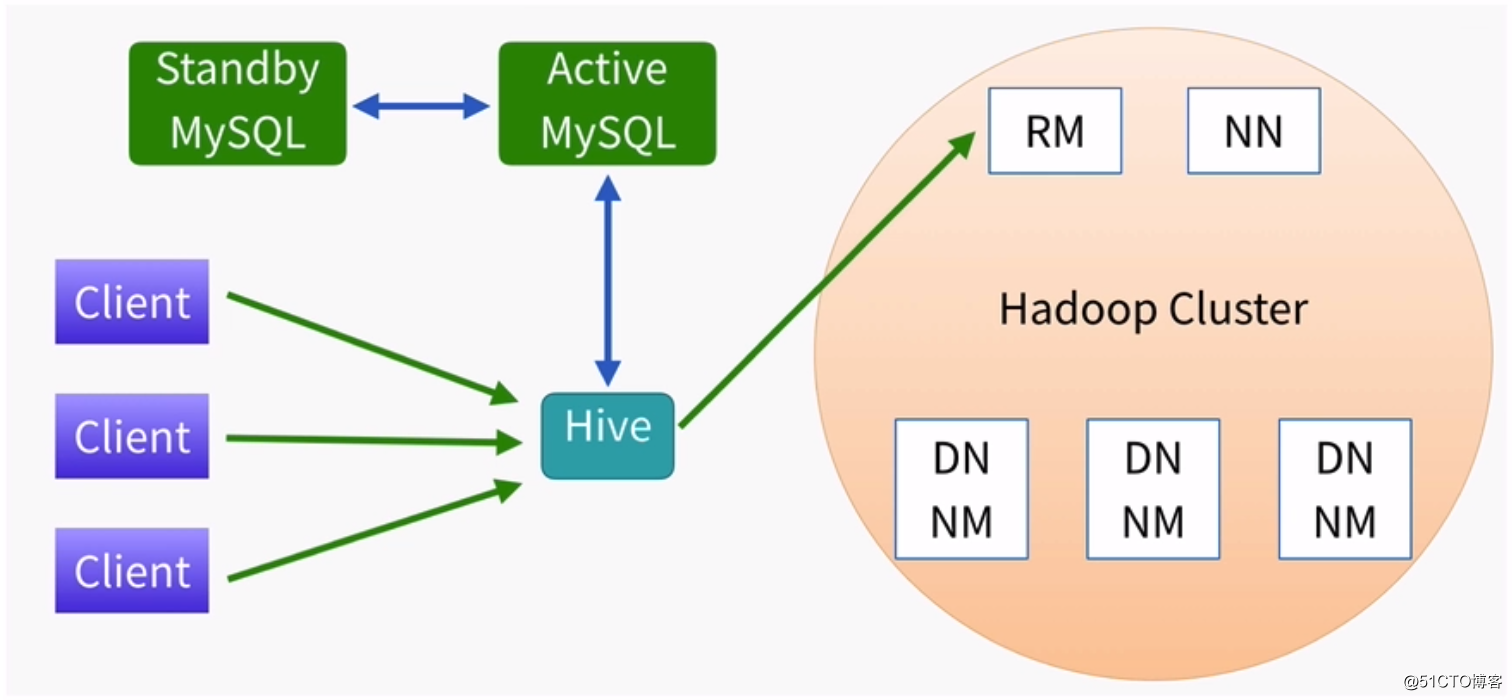
Hive发展历程:
- 08/2007 - Journey Start from Facebook
- 05/2013 - Hive 0.11.0 as Stinger Phase 1 - ORC,HiveServer2
- 10/2013 - Hive 0.12.0 as Stinger Phase 2 - ORC improvement
- 04/2014 - Hive 0.13.0 as Stinger Phase 3 - vectorized query engine and Tez
- 11/2014 - Hive 0.14.0 as Stinger.next Phase 1- Cost-based optimizer
- 01/2015 - Hive 1.0.0
- 03/2015 - Hive 1.1.0
- 05/2015 - Hive 1.2.0
- 02/2016 - Hive 2.0.0
- 06/2016 - Hive 2.1.0
- 07/2017 - Hive 2.2.0
- 05/2018 - Hive 3.0.0
- 08/2019 - Hive 3.1.2
Hive环境搭建
安装Hive
官方文档:
首先需要准备好Java运行环境和Hadoop环境,Hadoop搭建可以参考如下文章:
我这里使用的JDK版本是1.8,Hadoop是CDH5的2.6.0版本:
[root@hadoop01 ~]# java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# ls |grep hadoop
hadoop-2.6.0-cdh5.16.2.tar.gz
[root@hadoop01 /usr/local/src]# 并且确保Hadoop处于运行状态中:
[root@hadoop01 ~]# jps
3425 DataNode
3331 NameNode
3782 ResourceManager
3881 NodeManager
3582 SecondaryNameNode
4623 Jps
[root@hadoop01 ~]# 由于Hive默认是使用derby这种内嵌数据库来存储在Hive中创建的表、列、分区等元数据信息,但在生产环境中肯定不会使用内嵌数据库,而是将元数据存储在外部的数据库中,例如MySQL。所以我们还需要准备一台MySQL数据库,我这里使用的是一台现成的8.0.13版本MySQL:
[root@aliyun-server ~]# mysql --version
mysql Ver 8.0.13 for linux-glibc2.12 on x86_64 (MySQL Community Server - GPL)
[root@aliyun-server ~]# 然后下载Hive,Hive可以到Apache上下载,也可以到CDH上下载。Apache官网下载地址:
CDH5版本的下载地址(CDH5最新版本只到1.1.0,即hive-1.1.0-cdh5.16.2.tar.gz):
我这里作为演示下载的是Apache的3.1.2版本,通过如下命令下载Hive的二进制压缩包并解压:
[root@hadoop01 /usr/local/src]# wget https://mirror.bit.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
[root@hadoop01 /usr/local/src]# tar -zxvf apache-hive-3.1.2-bin.tar.gz
[root@hadoop01 /usr/local/src]# ls apache-hive-3.1.2-bin
bin binary-package-licenses conf examples hcatalog jdbc lib LICENSE NOTICE RELEASE_NOTES.txt scripts
[root@hadoop01 /usr/local/src]# - 如果Hadoop使用的是CDH版本那么最好安装对应CDH版本的Hive,否则可能会出现不兼容的问题,例如报找不到类啥的错误,Apache版本和CDH版本配置方式都是一样的
为了让Hive能够正常连接MySQL8.x,需要准备一个8.x版本的JDBC驱动包,然后放到Hive的lib目录下:
[root@hadoop01 /usr/local/src]# ls |grep mysql
mysql-connector-java-8.0.21.jar
[root@hadoop01 /usr/local/src]# cp mysql-connector-java-8.0.21.jar apache-hive-3.1.2-bin/lib/
[root@hadoop01 /usr/local/src]# ls apache-hive-3.1.2-bin/lib/ |grep mysql
mysql-connector-java-8.0.21.jar
mysql-metadata-storage-0.12.0.jar
[root@hadoop01 /usr/local/src]# 将Hive放到合适的目录下,我一般喜欢放在/usr/local:
[root@hadoop01 /usr/local/src]# mv apache-hive-3.1.2-bin ../配置环境变量:
[root@hadoop01 ~]# vim .bash_profile
export HIVE_HOME=/usr/local/apache-hive-3.1.2-bin
PATH=$PATH:$HOME/bin:$HIVE_HOME/bin
export PATH
[root@hadoop01 ~]# source .bash_profile 修改Hive的环境配置文件:
[root@hadoop01 ~]# cd /usr/local/apache-hive-3.1.2-bin/
[root@hadoop01 /usr/local/apache-hive-3.1.2-bin]# cp conf/hive-env.sh.template conf/hive-env.sh
[root@hadoop01 /usr/local/apache-hive-3.1.2-bin]# vim conf/hive-env.sh
HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh5.16.2/新建hive-site.xml配置文件:
[root@hadoop01 /usr/local/apache-hive-3.1.2-bin]# vim conf/hive-site.xml文件内容如下,主要是连接MySQL的相关配置“
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.11:3306/hive?createDatabaseIfNotExist=true&serverTimezone=Asia/Shanghai</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456a.</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>system:user.name</name>
<value>root</value>
<description>user name</description>
</property>
</configuration>安装tez引擎
Hive3默认使用tez作为引擎,依赖了tez的一些类,如果找不到的话启动会报错,所以我们需要安装一下tez,官网下载页面如下:
这里我下载的是二进制压缩包,二进制包需要注意兼容Hadoop版本,所以我这里选择0.8.5版本,下载tez压缩包并解压到合适的目录下:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/tez/0.8.5/apache-tez-0.8.5-bin.tar.gz
[root@hadoop01 /usr/local/src]# tar -zxvf apache-tez-0.8.5-bin.tar.gz -C /usr/local/将tez压缩包上传一份到HDFS中:
[root@hadoop01 /usr/local/src]# hadoop fs -mkdir /tez
[root@hadoop01 /usr/local/src]# hadoop fs -put apache-tez-0.8.5-bin.tar.gz /tez在Hive的conf目录下创建tez-site.xml文件:
[root@hadoop01 /usr/local/src]# cd ../apache-hive-3.1.2-bin
[root@hadoop01 /usr/local/apache-hive-3.1.2-bin]# vim conf/tez-site.xml配置内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>hdfs://hadoop01:8020/tez/apache-tez-0.8.5-bin.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>在conf/hive-env.sh文件末尾增加如下内容:
[root@hadoop01 /usr/local/apache-hive-3.1.2-bin]# vim conf/hive-env.sh
...
export TEZ_HOME=/usr/local/apache-tez-0.8.5-bin
for jar in `ls $TEZ_HOME |grep jar`; do
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$TEZ_HOME/lib/$jar
done启动Hive
初始化数据库和表:
[root@hadoop01 ~]# schematool -dbType mysql -initSchema
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sql
Initialization script completed
schemaTool completed配置yarn,在yarn-site.xml文件中增加如下配置:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/root/hadoop-tmp/nm-local-dir</value>
</property>- 如果
/root/hadoop-tmp/nm-local-dir不存在的话需要创建
完成以上配置后,就可以启动Hive服务了,命令如下:
[root@hadoop01 ~]# nohup hiveserver2 -hiveconf hive.execution.engine=mr &如果报了如下错误:
User: root is not allowed to impersonate anonymous (state=08S01,code=0)只需要在Hadoop的core-site.xml配置文件添加如下配置并重启即可:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>Hive的默认服务端口是10000,然后使用如下命令连接Hive:
[root@hadoop01 ~]# beeline -u jdbc:hive2://localhost:10000 -n root
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://localhost:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (0.91 seconds)
0: jdbc:hive2://localhost:10000> Hive基本使用
DDL操作官方文档:
DML操作官方文档:
SQL操作官方文档:
在Hive中创建数据表示例:
0: jdbc:hive2://localhost:10000> create table hive_wordcount(context string);
No rows affected (0.122 seconds)
0: jdbc:hive2://localhost:10000> 如果创建表时报如下错误:
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=anonymous, access=EXECUTE, inode="/user":root:supergroup:drwx------这是因为没有hdfs上的文件权限,修改相应文件的权限即可:
[root@hadoop01 ~]# hdfs dfs -chmod 777 /user表创建成功后,此时在MySQL中就可以看到表和字段的元数据信息:
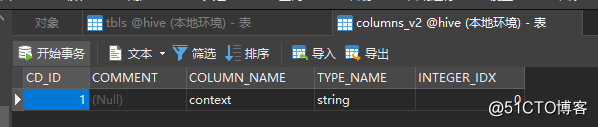
在Hive中查看已创建的表:
0: jdbc:hive2://localhost:10000> show tables;
+-----------------+
| tab_name |
+-----------------+
| hive_wordcount |
+-----------------+
1 row selected (0.043 seconds)
0: jdbc:hive2://localhost:10000> 现在有一个文本文件,内容如下:
[root@hadoop01 ~]# cat hello.txt
hello world welcome
hello welcome
[root@hadoop01 ~]# 使用如下语句可以将该文件的内容加载到Hive的数据表中:
0: jdbc:hive2://localhost:10000> load data local inpath '/root/hello.txt' into table hive_wordcount;
No rows affected (0.803 seconds)
0: jdbc:hive2://localhost:10000> 此时使用select语句可以看到该表内有两行数据了:
0: jdbc:hive2://localhost:10000> select * from hive_wordcount;
+-------------------------+
| hive_wordcount.context |
+-------------------------+
| hello world welcome |
| hello welcome |
+-------------------------+
2 rows selected (0.762 seconds)
0: jdbc:hive2://localhost:10000> 在Hive中使用SQL实现词频统计(WordCount)的例子:
0: jdbc:hive2://localhost:10000> select word, count(1) from hive_wordcount lateral view explode(split(context, '\t')) wc as word group by word;
+----------+------+
| word | _c1 |
+----------+------+
| hello | 2 |
| welcome | 2 |
| world | 1 |
+----------+------+
3 rows selected (14.795 seconds)
0: jdbc:hive2://localhost:10000> lateral view explode(split(context, '\t')):是把每行记录按照指定分隔符进行拆分
来源:oschina
链接:https://my.oschina.net/u/4282636/blog/4690607