前置
接口执行慢,需要优化,经过cProfile分析,时间大部分耗在数据库连接查询上,故去深究了下django关于db连接的情况,发现django是不支持数据库连接池的,遂查询django关于为啥不支持连接池的事情,以及试用了下目前开源的一些连接池,做此记录。
这篇主要解决我的以下疑问:
- web请求过来的流程?
- wsgi server 和 wsgi application如何交互?
- django何时建立db连接的?
- django何时关闭db连接的?
- django长连接是怎么回事?
- django为何没有连接池?
- django如何实现连接池?
工具
cProfile
拿它主要看耗时在哪里,不做无用功。
cProfile是Python自带的性能分析的内置模块,使用起来很方便,一段话就看的明白
import cProfile
import re
cProfile.run('re.compile("foo|bar")')
输出如下
197 function calls (192 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1 0.000 0.000 0.001 0.001 re.py:212(compile)
1 0.000 0.000 0.001 0.001 re.py:268(_compile)
1 0.000 0.000 0.000 0.000 sre_compile.py:172(_compile_charset)
1 0.000 0.000 0.000 0.000 sre_compile.py:201(_optimize_charset)
4 0.000 0.000 0.000 0.000 sre_compile.py:25(_identityfunction)
3/1 0.000 0.000 0.000 0.000 sre_compile.py:33(_compile)
解释:
ncall: 表示函数的调用次数,如果这一列有两个数值,表示有递归调用,第一个是总调用次数,第二个是原生调用次数
tottime: 函数调用时间(不包括调用其他函数的时间)
percall: (第一个)函数运行一次的平均时间,tottime/ncalls
cumtime: 函数调用时间(包括内部调用其他函数的时间)
percall: (第二个)函数运行一次的平均时间,cumtime/ncalls
filename:lineno(function): 很直观
也可指定输出的文件
import cProfile
import re
cProfile.run('re.compile("foo|bar")', 'result')
用pstats模块查看结果,可以按指定的字段进行排序,会使结果更易于分析
import pstats
p=pstats.Stats('result')
p.sort_stats('time').print_stats()
一般只关心时间,常用排序字段 tottime cumtime
除了在程序中导入cProflie外,还可以直接通过命令行执行脚本的形式查看
python -m cProfile [-o output_file] [-s sort_order] myscript.py
python cProfile指令接受-o参数后,-s参数无效。-s参数仅在没有-o参数存在下才会生效,即直接输出到屏幕。
Django
讲完了工具,下面可以考虑django数据库连接的事情了,之前一直以为每次objects.filter的时候就会开启一个db连接,查询完了之后会关闭掉,通过看文档以及实验发现,其实django是在一个request请求到来时,如果view里有数据库动作,那么开启连接,之后会一直复用,直到request结束才关闭连接,这个在django文档里有描述
持久连接¶
持久连接避免了在每个请求中重新建立与数据库的连接的开销。它们由CONN_MAX_AGE定义连接的最大生存期的参数控制 。可以为每个数据库独立设置。默认值为0,保留了在每个请求结束时关闭数据库连接的历史行为。要启用持久连接,请将其设置CONN_MAX_AGE为秒的正整数。对于无限的持久连接,请将其设置为None。这个参数的原理就是在每次创建完数据库连接之后,把连接放到一个Theard.local的实例中。在request请求开始结束的时候,打算关闭连接时会判断是否超过CONN_MAX_AGE设置这个有效期。超过则关闭。每次进行数据库请求的时候其实只是判断local中有没有已存在的连接,有则复用。
基于上述原因,Django中对于CONN_MAX_AGE的使用是有些限制的,使用不当,会适得其反。因为保存的连接是基于线程局部变量的,因此如果你部署方式采用多线程,必须要注意保证你的最大线程数不会多余数据库能支持的最大连接数(一个线程一个连接)。另外,如果使用开发模式运行程序(直接runserver的方式),建议不要设置CONN_MAX_AGE,因为这种情况下,每次请求都会创建一个Thread。同时如果你设置了CONN_MAX_AGE,将会导致你创建大量的不可复用的持久的连接。
连接管理¶
Django首次进行数据库查询时会打开与数据库的连接。它使该连接保持打开状态,并在后续请求中重用它。Django一旦超过了定义的最大CONN_MAX_AGE使用期限或不再可用时,便关闭连接 。详细来说,Django会在需要数据库且尚未建立数据库时自动打开与数据库的连接-要么是因为这是第一个连接,要么是因为上一个连接已关闭。
在每个请求的开始,如果Django已达到最大使用期限,则会关闭该连接。如果您的数据库在一段时间后终止了空闲连接,则应将其设置CONN_MAX_AGE为较低的值,以便Django不会尝试使用已由数据库服务器终止的连接。(此问题可能只影响流量非常小的站点。)
在每个请求结束时,如果Django已达到其最大使用期限或处于不可恢复的错误状态,它将关闭该连接。如果在处理请求时发生任何数据库错误,则Django会检查连接是否仍然有效,如果没有,则将其关闭。因此,数据库错误最多影响一个请求。如果连接变得不可用,则下一个请求将获得新的连接。
注意:
由于每个线程都维护自己的连接,因此你的数据库必须至少支持与工作线程一样多的并发连接。
有时,大多数
views都不会访问数据库,例如,因为它是外部系统的数据库,或者归功于缓存。 在这种情况下,应该将CONN_MAX_AGE设置为较小的值甚至0,因为维护不太可能重用的连接没有意义。这将有助于将与数据库的并发连接数量保持在较小的值。开发模式的Server为它处理的每个请求创建一个新线程,无视长连接的作用。在开发过程中不需要启用长连接。
当Django建立与数据库的连接时,它会根据所使用的后端设置恰当的参数。 如果启用长连接,则不会再对每个请求重复设置。 如果修改连接的隔离级别或时区等参数,则应在每个请求结束时恢复Django的默认值,在每个请求开始时强制使用适当的值,或者禁用长连接。
为啥django不支持连接池
可以参照很久远的一个帖子https://groups.google.com/forum/#!topic/django-developers/NwY9CHM4xpU
大致意思就是:
- django不需要引入这个复杂度
- 好多第三方已经做的很好了
- MySQL的连接非常轻量和高效,大量的Web应用都没有使用连接池
- django一个request内db连接是可以复用的
- django1.6版本后提供了长连接的支持
- 。。。。
那为何还要在Django中启用连接池
依据上面描述,
- Django服务每个线程都维护自己的连接,有多少线程就会就有多少连接;如果采用分布式部署,线程数较多,则会建立较多的连接。不仅非常消耗资源,还可能出现MySQL连接数不够用的情况。
- 从速度上来讲,有了连接池,下次请求过来的直接拿到连接,至少节省了本次request中的db连接时间。
连接池方案
目前测试的是下面2个方案,都是基于SQLAlchemy的连接池做的。
使用方式都非常简单, 参照github上安装即可
注: djorm-ext-pool在python3,django3下跑还有bug,如下方式修正
djorm-pool/__init__.py ... def patch_mysql(): class hashabledict(dict): def __hash__(self): # return hash(tuple(sorted(self.items()))) 注释掉这个,换成下面的 return hash(frozenset(self)) ...
django里的wsgi
django框架实现了wsgi接口(关于wsgi见捅开web应用的那层纱),一般都是和实现了wsgi协议的服务器对接,这里就想了解wsgi在django里如何实现的。
按wsgi要求,应用程序要提供一个可调用对象,来接收2个参数,简单示例如下:
def application(environ, start_response):
status = '200 OK'
response_headers = [('Content-Type', 'text/plain')]
start_response(status, response_headers)
return ['Hello world']
好,我们看Django的实现方式。
比如gunicorn的启动
gunicorn dj_db_pool.wsgi:application -b 0.0.0.0:80 --workers=5
gunicorn实现了server端的功能,监控HTTP请求,提供入口,调用应用程序端的application。
此处的application为dj_db_pool.wsgi:application,即:
# dj_db_pool/wsgi.py
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'dj_db_pool.settings')
application = get_wsgi_application()
get_wsgi_application为:
# django/core/wsgi.py
import django
from django.core.handlers.wsgi import WSGIHandler
def get_wsgi_application():
"""
The public interface to Django's WSGI support. Return a WSGI callable.
Avoids making django.core.handlers.WSGIHandler a public API, in case the
internal WSGI implementation changes or moves in the future.
"""
django.setup(set_prefix=False) # 初始化django环境
return WSGIHandler() # 返回server端可调用的应用程序对象
WSGIHandler为:
# django/core/handlers/wsgi.py
class WSGIHandler(base.BaseHandler):
request_class = WSGIRequest
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.load_middleware() # 加载django中间件
def __call__(self, environ, start_response): # 此作为可调用对象传给wsgi server端,每次有请求进来这里都会执行
set_script_prefix(get_script_name(environ))
signals.request_started.send(sender=self.__class__, environ=environ) # 触发了request_started的信号
request = self.request_class(environ) # 调用WSGIRequest实例化请求
response = self.get_response(request) # 处理response
response._handler_class = self.__class__
status = '%d %s' % (response.status_code, response.reason_phrase)
response_headers = [
*response.items(),
*(('Set-Cookie', c.output(header='')) for c in response.cookies.values()),
]
start_response(status, response_headers) # 此处wsgi协议要求的第二个可调函数,把HTTP状态和头部信息返回给server
if getattr(response, 'file_to_stream', None) is not None and environ.get('wsgi.file_wrapper'):
# If `wsgi.file_wrapper` is used the WSGI server does not call
# .close on the response, but on the file wrapper. Patch it to use
# response.close instead which takes care of closing all files.
response.file_to_stream.close = response.close
response = environ['wsgi.file_wrapper'](response.file_to_stream, response.block_size)
return response # 返回处理结果
http请求到达django内部的过程大概如上所述。
django request里的db连接
好,我们看哪里对db做了处理?
发现前面在WSGIHandler里有对request_started信号的触发:
signals.request_started.send(sender=self.__class__, environ=environ) # 触发了request_started的信号
request_started信号
那么信号的处理在这里
# django/db/__init__.py
......
connections = ConnectionHandler()
router = ConnectionRouter()
......
# For backwards compatibility. Prefer connections['default'] instead.
connection = DefaultConnectionProxy()
# Register an event to reset saved queries when a Django request is started.
def reset_queries(**kwargs):
for conn in connections.all():
conn.queries_log.clear()
signals.request_started.connect(reset_queries) # 这里被处理,调用了reset_queries
# Register an event to reset transaction state and close connections past
# their lifetime.
def close_old_connections(**kwargs):
for conn in connections.all(): #1. connections.all()会给出一个列表,里面的元素为DatabaseWrapper类
conn.close_if_unusable_or_obsolete() #2. 关闭不可用和超时的db连接
signals.request_started.connect(close_old_connections) # 请求开始时request_started被调用,调用了close_old_connections,初始化各db实例化类,如开启长连接,那么检测时间关闭db连接,self.connection为空则不做任务操作
signals.request_finished.connect(close_old_connections) # 请求完成以后request_finished被调用,关闭了不可用连接
可以看到这里request_started触发调用了close_old_connections,而close_old_connections里调用了connections(即ConnetionHandler实例)的all方法,其实它返回的是一个列表,里面的元素为DatabaseWrapper类,其实就是循环setting配置的DATABASES,实例化各ENGINE指定的db后端。
# django/db/utils.py
#
# for conn in connections.all() -->
# |
# |
# v
class ConnectionHandler:
......
def all(self): # 1 connections.all()调用这里
return [self[alias] for alias in self] #2 self可迭代,alias即为self.databases。而self[alias]即调用的__getitem__的实现
def __iter__(self): # 2
return iter(self.databases) # 3 self.databases即为setting配置文件里的DATABASES
@cached_property
def databases(self): # 3
if self._databases is None:
self._databases = settings.DATABASES # 4 here
"""
忽略细节
"""
return self._databases
上面的self[alias]就是各db实现的后端,接着往下看
# django/db/utils.py
class ConnectionHandler:
......
def __getitem__(self, alias): # 1.1
#1.2 关键点,如果local内有的话直接返回,调用方式 connections['default']
if hasattr(self._connections, alias):
return getattr(self._connections, alias)
self.ensure_defaults(alias)
self.prepare_test_settings(alias)
db = self.databases[alias] #1.3 获取配置文件里获取db信息
backend = load_backend(db['ENGINE']) #1.4 加载对应数据库ENGINE,如:django.db.backends.mysql
conn = backend.DatabaseWrapper(db, alias) #1.5 上面load的base.py文件里都有DatabaseWrapper类,这里实例化这个类。它主要负责对应db后端的连接和关闭
setattr(self._connections, alias, conn) #1.6 连接放到local里,以接下来的复用
return conn
......
def close_all(self): # 关闭数据库连接
for alias in self:
try:
connection = getattr(self._connections, alias)
except AttributeError:
continue
connection.close()
......
# 101行处
def load_backend(backend_name): #1.4
# This backend was renamed in Django 1.9.
if backend_name == 'django.db.backends.postgresql_psycopg2':
backend_name = 'django.db.backends.postgresql'
try:
return import_module('%s.base' % backend_name) #1.4.1 加载对应的数据库处理类,实际就是django.db.backends.mysql.base类
except ImportError as e_user:
上面可以看到connections.all()里就是DatabaseWrapper类,每个都继承于BaseDatabaseWrapper,提供了基本的connect函数用于数据库连接,且赋值于属性self.connection(self.connection = self.get_new_connection(conn_params) )
# django/db/backends/base/base.py
class BaseDatabaseWrapper:
......
@async_unsafe
def connect(self):
"""Connect to the database. Assume that the connection is closed."""
# Check for invalid configurations.
self.check_settings()
# In case the previous connection was closed while in an atomic block
self.in_atomic_block = False
self.savepoint_ids = []
self.needs_rollback = False
# Reset parameters defining when to close the connection
max_age = self.settings_dict['CONN_MAX_AGE'] # 默认值0
self.close_at = None if max_age is None else time.monotonic() + max_age # 也就是这里是当前时间
self.closed_in_transaction = False
self.errors_occurred = False
# Establish the connection
conn_params = self.get_connection_params()
self.connection = self.get_new_connection(conn_params) # 调用各子类实现的特定后端方法连接数据库
self.set_autocommit(self.settings_dict['AUTOCOMMIT'])
self.init_connection_state()
connection_created.send(sender=self.__class__, connection=self)
self.run_on_commit = []
......
@async_unsafe
def ensure_connection(self): # 主要调这里建立连接
"""Guarantee that a connection to the database is established."""
if self.connection is None:
with self.wrap_database_errors:
self.connect()
......
def _close(self): # 关闭db连接
if self.connection is not None:
with self.wrap_database_errors:
return self.connection.close()
......
@async_unsafe
def close(self):
"""Close the connection to the database."""
self.validate_thread_sharing()
self.run_on_commit = []
# Don't call validate_no_atomic_block() to avoid making it difficult
# to get rid of a connection in an invalid state. The next connect()
# will reset the transaction state anyway.
if self.closed_in_transaction or self.connection is None:
return
try:
self._close()
finally:
if self.in_atomic_block:
self.closed_in_transaction = True
self.needs_rollback = True
else:
self.connection = None
对于mysql后端来说,self.get_new_connection就是通过MySQLdb新建db连接
# django/db/backends/mysql/base.py
class DatabaseWrapper(BaseDatabaseWrapper):
......
def get_new_connection(self, conn_params):
return Database.connect(**conn_params) #通过MySQLdb新建db连接
# 而Database就是
try:
import MySQLdb as Database
except ImportError as err:
raise ImproperlyConfigured(
'Error loading MySQLdb module.\n'
'Did you install mysqlclient?'
) from err
到这里,一个request的过程基本就完了,在这里并没有触发db的连接,只是处理了DatabaseWrapper类的实例化,关闭超时的长连接等。
DB操作
具体的db连接创建是在第一次执行orm操作的时候,比如在for row in xxx.objects.filter()时
# django/db/models/query.py
class ModelIterable(BaseIterable):
"""Iterable that yields a model instance for each row."""
def __iter__(self):
queryset = self.queryset
db = queryset.db
compiler = queryset.query.get_compiler(using=db) # 获取具体sql编译器
# Execute the query. This will also fill compiler.select, klass_info,
# and annotations.
results = compiler.execute_sql(chunked_fetch=self.chunked_fetch, chunk_size=self.chunk_size) #执行sql
compiler.execute_sql见下
# django/db/models/query.py
class SQLCompiler:
......
def execute_sql(self, result_type=MULTI, chunked_fetch=False, chunk_size=GET_ITERATOR_CHUNK_SIZE):
result_type = result_type or NO_RESULTS
try:
sql, params = self.as_sql()
if not sql:
raise EmptyResultSet
except EmptyResultSet:
if result_type == MULTI:
return iter([])
else:
return
if chunked_fetch:
cursor = self.connection.chunked_cursor()
else:
cursor = self.connection.cursor() # 获取数据库连接
try:
cursor.execute(sql, params) # 执行db操作
except Exception:
# Might fail for server-side cursors (e.g. connection closed)
cursor.close()
raise
"""
暂时忽略,主要是result返回的处理
"""
return result
关键点cursor = self.connection.cursor() 处触发数据库连接,并获取对应的cursor,见代码部分
# django/db/backends/base/base.py
class BaseDatabaseWrapper:
......
@async_unsafe
def cursor(self): # 上面的入口
"""Create a cursor, opening a connection if necessary."""
return self._cursor() #1 创建一个cursor,必要时打开数据库连接
def _cursor(self, name=None): #1
self.ensure_connection() #2 无数据库连接时会新建db连接
with self.wrap_database_errors:
return self._prepare_cursor(self.create_cursor(name)) #3
@async_unsafe
def ensure_connection(self): #2
"""Guarantee that a connection to the database is established."""
if self.connection is None: # 无数据库连接时会新建
with self.wrap_database_errors:
self.connect() #2.1 新建db连接
# self.connect()参照上面self.connection = self.get_new_connection(conn_params)处
def _prepare_cursor(self, cursor): #3 此处为MySQLdb的cursor
self.validate_thread_sharing()
if self.queries_logged:
wrapped_cursor = self.make_debug_cursor(cursor)
else:
wrapped_cursor = self.make_cursor(cursor) #3.1 调用mysql的
return wrapped_cursor
def make_cursor(self, cursor): #3.1
"""Create a cursor without debug logging."""
return utils.CursorWrapper(cursor, self) #3.2 调用utils包里的CursorWrapper类包装
上面self._prepare_cursor(self.create_cursor(name)) 黑体部分回调mysql对应的DatabaseWrapper类里的create_cursor,返回对应的mysql的CursorWrapper,这个类里有对应的execute
# django/db/backends/mysql/base.py
class DatabaseWrapper(BaseDatabaseWrapper):
......
@async_unsafe
def create_cursor(self, name=None):
cursor = self.connection.cursor() # 返回MySQLdb连接的cursor
return CursorWrapper(cursor) # 对cursor进行包装,方便循环之类的
接着看self._prepare_cursor(self.create_cursor(name)),self._prepare_cursor部分代码
# django/db/backends/base/base.py
class BaseDatabaseWrapper:
......
def _prepare_cursor(self, cursor): #3 此处为MySQLdb的cursor
self.validate_thread_sharing()
if self.queries_logged:
wrapped_cursor = self.make_debug_cursor(cursor)
else:
wrapped_cursor = self.make_cursor(cursor) #3.1
return wrapped_cursor
def make_cursor(self, cursor): #3.1
"""Create a cursor without debug logging."""
return utils.CursorWrapper(cursor, self) #3.2 调用utils包里的CursorWrapper类包装
utils里的CursorWrapper类比较重要的两个方法
# django/db/backends/utils.py
class CursorWrapper:
def __init__(self, cursor, db):
self.cursor = cursor
self.db = db
......
def execute(self, sql, params=None): # 上面query.py里的cursor.execute(sql, params)调用部分
return self._execute_with_wrappers(sql, params, many=False, executor=self._execute) # self._execute的定义见下,其实就是前面的mysql对应的CursorWrapper
def _execute_with_wrappers(self, sql, params, many, executor):
context = {'connection': self.db, 'cursor': self}
for wrapper in reversed(self.db.execute_wrappers):
executor = functools.partial(wrapper, executor)
return executor(sql, params, many, context) # 这里执行的execute实际就是mysql/base.py里的CursorWrapper类里的execute方法
def _execute(self, sql, params, *ignored_wrapper_args):
self.db.validate_no_broken_transaction()
with self.db.wrap_database_errors:
if params is None:
# params default might be backend specific.
return self.cursor.execute(sql)
else:
return self.cursor.execute(sql, params)
至此,触发db连接的过程也分析结束了
request_finished信号
那么,关闭db连接是在什么地方?
我们发现前面的django/db/__init__.py文件里不光request_started的信号在这里处理,request_finished的信号也在这里处理。
那么request_finished的信号是在哪里触发的?见下
# django/http/response.py
......
class HttpResponseBase:
......
# The WSGI server must call this method upon completion of the request.
# See http://blog.dscpl.com.au/2012/10/obligations-for-calling-close-on.html
def close(self): # 此处不是django里代码调用,而是由wsgi server去调用,这里注意
for closer in self._resource_closers:
try:
closer()
except Exception:
pass
# Free resources that were still referenced.
self._resource_closers.clear()
self.closed = True
signals.request_finished.send(sender=self._handler_class) # 请求结束时会统一调用close,这里触发了request_finished的信号
注意:HttpResponseBase里的close是由wsgi server去调用的,具体分析见此处
close_if_unusable_or_obsolete
好,知道了请求在哪里结束,那么我们回头来看下close_if_unusable_or_obsolete这个方法里都干了啥
# django/db/backends/base/base.py
class BaseDatabaseWrapper:
......
@async_unsafe
def connect(self):
......
max_age = self.settings_dict['CONN_MAX_AGE'] # 默认是0
self.close_at = None if max_age is None else time.monotonic() + max_age #1 那close_at这里就是连接开始的时间
......
......
def close_if_unusable_or_obsolete(self):
# 有连接才处理,对于request_started信号触发的调用,一般情况下self.connection都是None,这里一般都忽略掉
if self.connection is not None:
if self.get_autocommit() != self.settings_dict['AUTOCOMMIT']:
self.close()
return
if self.errors_occurred:
if self.is_usable():
self.errors_occurred = False
else:
self.close()
return
# 请求结束时db连接关闭就是在这里做的,看上面1注释,close_at有值,max_age默认0的情况下time.monotonic()肯定大于close_at,所以请求结束db连接是关闭的。
if self.close_at is not None and time.monotonic() >= self.close_at:
self.close()
return
上面特别注意close_at,之前就是看了半天都以为不是在这里关闭的,其实max_age默认是0,不配置默认也是0,坑爹。
所以 if self.close_at is not None and time.monotonic() >= self.close_at,这个地方就肯定是True了,所以默认情况下请求结束db连接是关闭的。
至此,我们也分析完了db何时关闭。
试验连接池
我们拿django-db-connection-pool来测试。
安装
pip install django-db-connection-pool
配置
'default': {
......
'ENGINE': 'dj_db_conn_pool.backends.mysql',
......
'POOL_OPTIONS': {
'POOL_SIZE': 10, # 池大小
'MAX_OVERFLOW': 0 # 池满了之后允许溢出的大小,最大连接数就是POOL_SIZE+MAX_OVERFLOW
}
}
测试
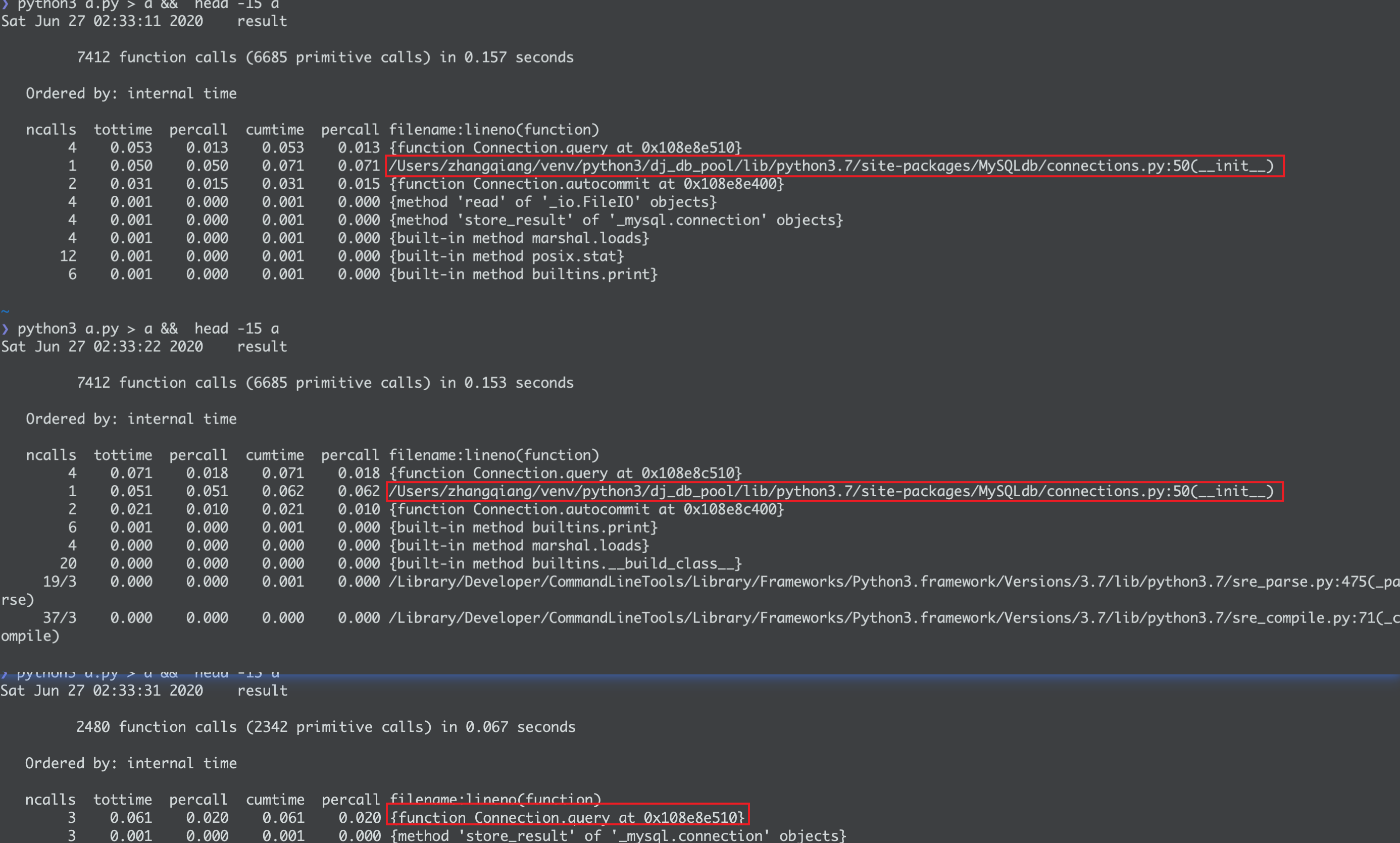
随便查询一个表用cProfile看查看时间
为了测试效果pool_size我配置1,且gunicorn启动时我只启动了一个出来进程
gunicorn dj_db_pool.wsgi:application -b 0.0.0.0:80 --workers=1
这样,第一次请求应该是需要连接db的,第二次应该是不需要的。

可见,连接池起效果了,👍
原理
原理不复杂,主要就是覆盖了mysql/base.py的DatabaseWrapper里的get_new_connection和close方法,用sqlalchemy里的pool来实现连接池。
class PooledDatabaseWrapperMixin(object):
def get_new_connection(self, conn_params):
"""
覆盖 Django 的 get_new_connection 方法
在 Django 调用此方法时,检查 pool_container 中是否有 self.alias 的连接池
如果没有,则初始化 self.alias 的连接池,然后从池中取出一个连接
如果有,则直接从池中取出一个连接返回
:return:
"""
with pool_container.lock:
# 获取锁后,判断当前数据库(self.alias)的池是否存在
# 不存在,开始初始化
if not pool_container.has(self.alias):
# 复制一份默认参数给当前数据库
pool_params = deepcopy(pool_container.pool_default_params)
# 开始解析、组装当前数据库的连接配置
pool_setting = {
# 把 POOL_OPTIONS 内的参数名转换为小写
# 与 QueuePool 的参数对应
key.lower(): value
# 取每个 POOL_OPTIONS 内参数
for key, value in
# self.settings_dict 由 Django 提供,是 self.alias 的连接参数
self.settings_dict.get('POOL_OPTIONS', {}).items()
# 此处限制 POOL_OPTIONS 内的参数:
# POOL_OPTIONS 内的参数名必须是大写的
# 而且其小写形式必须在 pool_default_params 内
if key == key.upper() and key.lower() in pool_container.pool_default_params
}
# 现在 pool_setting 已经组装完成
# 覆盖 pool_params 的参数(以输入用户的配置)
pool_params.update(**pool_setting)
# 现在参数已经具备
# 创建 self.alias 的连接池实例
alias_pool = pool.QueuePool(
# QueuePool 的 creator 参数
# 在获取一个新的数据库连接时,SQLAlchemy 会调用这个匿名函数
lambda: super(PooledDatabaseWrapperMixin, self).get_new_connection(conn_params),
# 数据库方言
# 用于 SQLAlchemy 维护该连接池
dialect=self.SQLAlchemyDialect(dbapi=self.Database),
# 一些固定的参数
pre_ping=True, echo=False, timeout=None, **pool_params
)
logger.debug(_("%s's pool has been created, parameter: %s"), self.alias, pool_params)
# 数据库连接池已创建
# 放到 pool_container,以便重用
pool_container.put(self.alias, alias_pool)
# 调用 SQLAlchemy 从连接池内取一个连接
conn = pool_container.get(self.alias).connect()
logger.debug(_("got %s's connection from its pool"), self.alias)
return conn
def close(self, *args, **kwargs):
logger.debug(_("release %s's connection to its pool"), self.alias)
return super(PooledDatabaseWrapperMixin, self).close(*args, **kwargs)
gunicorn多worker表现
上面启动了一个worker,多个worker如何表现
gunicorn dj_db_pool.wsgi:application -b 0.0.0.0:80 --workers=3
--worker是多进程方式,上面起了3个进程
还可以--threads=2,每个进程再启动2个线程
会看到请求第一次到一个worker上还是有新的db连接建立,之后就走池里连接了
所以起连接池时,要算好起的进程数(or线程数)以及POOL_SIZE的大小,以防止起过多DB连接。
结语
现在数据库连接已经很快了,我测试过程中,基本在50-100ms之间,对于需要精准耗时的,这个时间优化还是可以的,对于正常1,2秒返回的,可能优化效果不大。
来源:oschina
链接:https://my.oschina.net/u/914655/blog/4316518