经典数据结构和算法你了解几个?想去大厂面试?想成为算法工程师?收下这份全面的复习材料。
机器之心报道,参与:Racoon、Jamin。
不想做低级码农,不想成为前端抠图达人或是后台「增删改查」小王子?那你可能需要好好复习下算法与数据结构。想成为算法工程师,基础知识是绕不开的大山。机器之心这次要推荐的项目是数据结构与算法的开源项目集,覆盖多种主流语言,实现各类经典数据结构及算法。
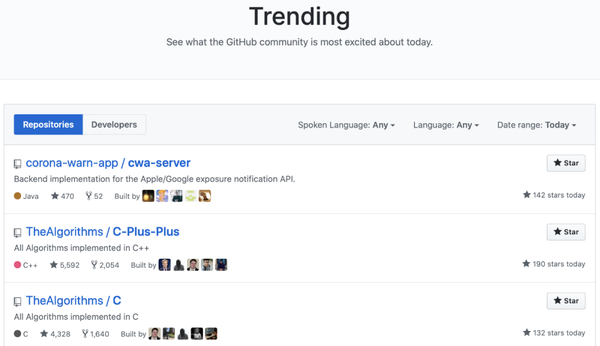

项目地址:https://github.com/trending
The Algorithms 项目介绍
正如 The Algorithms 项目主页上介绍的那样,这是一个使用多种编程语言,实现经典数据结构与算法的开源项目集。这里的「any Programming Language」真是没有虚假宣传,我们可以看到 The Algorithms 里从较为流行的 Python、Java、C、C++到 C#、Go、Rust、Kotlin 语言应有尽有,当然有的编程语言实现的算法还不是那么的丰富,其中维护较好的还是 Python 和 Java。
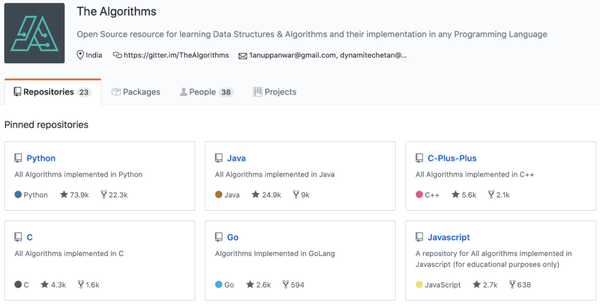
本文以 The Algorithms 的 Python 项目为例进行介绍。
截至目前,该项目已经有 7 万多星,内容涵盖加密算法、图像处理、动态规划、线性代数、经典机器学习算法、搜索算法、排序算法以及各种数据结构等,单是所实现算法的目录就有 600 多行……当然,项目作者也指出,该项目的主要目的是用作各种算法的学习资料,项目中的一些实现可能没有 Python 标准库中的那么高效。
项目地址:https://github.com/TheAlgorithms/Python
部分算法展示
该项目吸引人的地方不单是里面有丰富的算法实现,部分算法还配有相关解释、维基百科链接和交互网页链接。我们选取了其中的部分算法实现进行展示。
排序算法
1. 冒泡排序
冒泡排序是一种简单的排序算法。它重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就将其交换过来。重复以上过程直到没有需要交换的元素,即表示完成排序。该算法名字的由来是越小的元素会经由交换慢慢「浮」到数列的顶端。
算法复杂度:
- 最坏 O(n^2)
- 最好 O(n)
- 平均 O(n^2)
交互网页地址:https://www.toptal.com/developers/sorting-algorithms/bubble-sort
2. 插入排序
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上通常采用 in-place 排序,因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
算法复杂度:
- 最坏 O(n^2)
- 最好 O(n)
- 平均 O(n^2)
交互网页地址:https://www.toptal.com/developers/sorting-algorithms/insertion-sort
3. 归并排序

归并排序是建立在归并操作上的一种有效的排序算法,由约翰·冯·诺伊曼首次提出。该算法是采用分治法的一个非常典型的应用,且各层分治递归可以同时进行。
算法复杂度:
- 最坏 O(n log n)
- 最好 O(n)
- 平均 O(n)
交互网页地址:https://www.toptal.com/developers/sorting-algorithms/merge-sort
4. 快速排序

快速排序算法最早由东尼·霍尔提出。使用分治法策略把一个序列分为较小和较大 2 个子序列,然后递归地排序两个子序列。
算法复杂度:
- 最坏 O(n^2)
- 最好 O(n log n) 或 O(n)
- 平均 O(n^2)
交互网页地址:https://www.toptal.com/developers/sorting-algorithms/quick-sort
5. 希尔排序

希尔排序也称递减增量排序算法,是插入排序的一种更高效的改进版本,按其设计者希尔(Donald Shell)的名字命名,该算法由 1959 年公布。希尔排序是非稳定排序算法。
算法复杂度:
- 最坏 O(nlog2 2n)
- 最好 O(n log n)
- 平均复杂度取决于步长序列
交互网页地址:https://www.toptal.com/developers/sorting-algorithms/shell-sort
搜索算法
1. 线性搜索算法
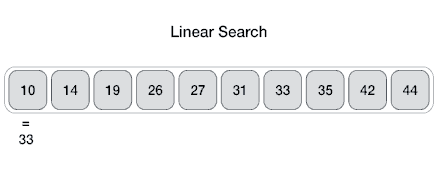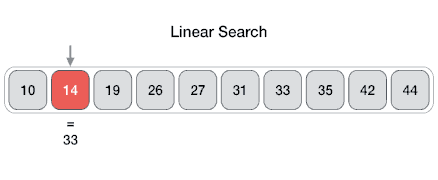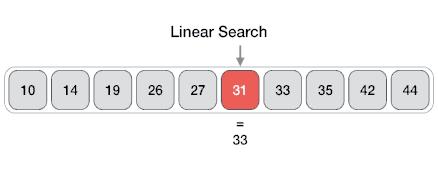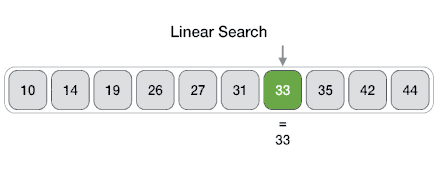
线性搜索也称为顺序搜索,其使用一个循环按顺序遍历整个数组,将每个元素与正在搜索的值进行比较,并在找到该值或遇到数组末尾时停止。
算法特性:
- 最坏算法复杂度 O(n)
- 最好算法复杂度 O(1)
- 平均算法复杂度 O(n)
- 最坏空间复杂度 O(1)
2. 二分查找算法
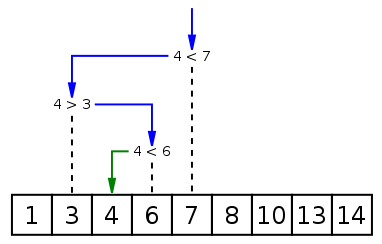
二分查找算法也称折半搜索算法、对数搜索算法,是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
算法特性:
- 最坏算法复杂度 O(log n)
- 最好算法复杂度 O(1)
- 平均算法复杂度 O(log n)
- 最坏空间复杂度 O(1)
作者简介
该项目作者是位印度籍工程师,对技术开发非常痴迷,并坦言自己是一个非常有「雄心壮志」的小伙,之后想成为一名企业家。从技术角度看,作者对全栈开发、android 开发、深度学习以及区块链等技术都很感兴趣。目前,他已经在 3 家创业公司工作过,并在开发领域积累了 2 年的经验。
从过往经历来看,印度小哥的工作经历还是很「丰富多彩」的,从开始将自己定位为软件工程师,到目前在 Gojek 任职产品工程师。
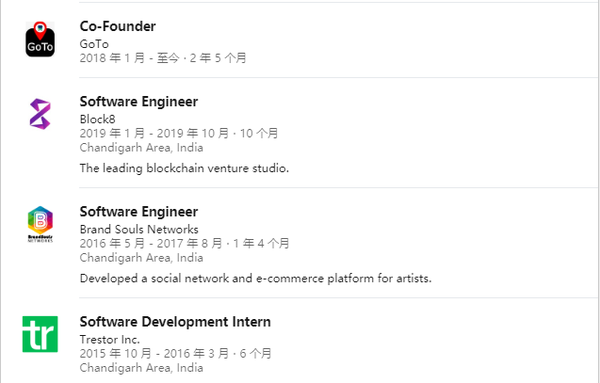
Gojek 是印度尼西亚第一家独角兽公司,于 2010 年在印度尼西亚成立。我们可以将这家公司理解为呼叫中心,将消费者与快递和两轮叫车服务连接起来。该公司同时在印度尼西亚、越南、新加坡、泰国和菲律宾都有不少的业务发展。
来源:oschina
链接:https://my.oschina.net/u/4277371/blog/4295195