1、Ceph概述
1.1、什么是分布式存储
- 分布式存储是指一种独特的系统架构,它由一组网络进行通信、为了完成共同的任务而协调工作的计算机节点组成
- 分布式系统是为了用廉价的、普通的机器完成单个计算无法完成的计算、存储任务
- 其目的是利用更多的机器,处理更多的数据
1.2、常见的分布式文件系统
- Lustre
- Hadoop
- FastDFS
- Ceph
- GlusterFS
1.3、什么是Ceph
1.3.1、Ceph简介
- Ceph是一个分布式文件系统
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
1.3.2、Ceph特点
-
具有高扩展、高可用、高性能的特点
-
高性能
- 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。 b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
- 能够支持上千个存储节点的规模,支持TB到PB级的数据。
-
高可用性
-
副本数可以灵活控制。
-
支持故障域分隔,数据强一致性。
-
多种故障场景自动进行修复自愈。
-
没有单点故障,自动管理。
-
-
高可扩展性
-
去中心化。
-
扩展灵活。
-
随着节点增加而线性增长。
-
-
-
特性丰富
- Ceph可以提供对象存储、块存储、文件系统存储
- 支持自定义接口,支持多种语言驱动。
-
Ceph可以提供PB级别的存储空间(PB→TB→GB)
-
软件定义存储(Software Defined Storage)作为存储行业的一大发展趋势,已经越来越受到市场的认可
- 过半原则:必须有一半以上的服务器正常,才能使用,搭建集群通常用奇数
1.3.3、Ceph组件
- OSD
- 存储设备
- 全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。
- Monitor
- 集群监控组件
- 一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。
- RadosGateway(RGW)
- 对象存储网关
- MDSs
- 存放文件系统的元数据(对象存储和块存储不需要该组件)
- 全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
- Client
- ceph客户端
2、实验环境准备
- 准备四台虚拟机,其三台作为存储集群节点,一台安装为客户端,实现如下功能:
- 创建1台客户端虚拟机
- 创建3台存储集群虚拟机
- 配置主机名、IP地址、YUM源
- 修改所有主机的主机名
- 配置无密码SSH连接
- 配置NTP时间同步
- 添加额外的光驱(加载ceph10.iso)
- 创建虚拟机磁盘 (额外添加2块20G磁盘)
| 主机名 | IP地址 |
|---|---|
| client | eth0:192.168.4.10/24 |
| node1 | eth0:192.168.4.11/24 |
| node2 | eth0:192.168.4.12/24 |
| node3 | eth0:192.168.4.13/24 |
- 所有主机设置防火墙和SELinux(以client为例)
[root@client ~]# firewall-cmd --set-default-zone=trusted
[root@client ~]# sed -i '/SELINUX/s/enforcing/permissive/' /etc/selinux/config
[root@client ~]# setenforce 0
- 所有主机挂载ceph光盘和系统光盘
[root@client ~]# mkdir /ceph
[root@client ~]# vim /etc/fstab
[root@client ~]# tail -2 /etc/fstab
/dev/sr1 /mydvd iso9660 defaults 0 0
/dev/sr0 /ceph iso9660 defaults 0 0
[root@client ~]# mount -a
- lsblk检查磁盘情况
[root@client ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
···········省略部分内容
sr0 11:0 1 284M 0 rom /ceph #ceph光盘
sr1 11:1 1 8.8G 0 rom /mydvd #系统光盘
[root@node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
···········省略部分内容
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sr0 11:0 1 284M 0 rom /ceph #ceph光盘
sr1 11:1 1 8.8G 0 rom /mydvd #系统光盘
[root@node2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
···········省略部分内容
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sr0 11:0 1 284M 0 rom /ceph
sr1 11:1 1 8.8G 0 rom /mydvd
[root@node3 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
···········省略部分内容
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sr0 11:0 1 284M 0 rom /ceph
sr1 11:1 1 8.8G 0 rom /mydvd
- 配置无密码连接(包括自己远程自己也不需要密码),在node1操作
[root@node1 ~]# ssh-keygen -f /root/.ssh/id_rsa -N ''
#-f后面跟密钥的文件名称(希望创建密钥到哪个文件)
#-N ''代表不给密钥配置密钥(不能给密钥配置密码)
[root@node1 ~]# for i in 10 11 12 13
>do
> ssh-copy-id 192.168.4.$i
>done
#通过ssh-copy-id将密钥传递给192.168.4.10、192.168.4.11、192.168.4.12、192.168.4.13
- 修改/etc/hosts并同步到所有主机
[root@node1 ~]# cat /etc/hosts #修改文件,手动添加如下内容(不要删除文件原有内容)
···········省略部分内容
192.168.4.10 client
192.168.4.11 node1
192.168.4.12 node2
192.168.4.13 node3
[root@node1 ~]# for i in client node1 node2 node3
>do
> scp /etc/hosts $i:/etc/
>done
- 为所有节点配置yum源,并同步到所有主机。
[root@node1 ~]# cat /etc/yum.repos.d/abc.repo
[abc]
name=abc
baseurl=file:#/mydvd
enabled=1
gpgcheck=0
[root@node1 ~]# cat /etc/yum.repos.d/ceph.repo
[mon]
name=mon
baseurl=file:#/ceph/MON
gpgcheck=0
[osd]
name=osd
baseurl=file:#/ceph/OSD
gpgcheck=0
[tools]
name=tools
baseurl=file:#/ceph/Tools
gpgcheck=0
[root@client ~]# yum repolist
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
repo id repo name status
abc abc 9,911
mon mon 41
osd osd 28
tools tools 33
repolist: 10,013
[root@node1 ~]# for i in client node1 node2 node3
do
scp /etc/yum.repos.d/*.repo $i:/etc/yum.repos.d/
done
- Client主机配置为NTP服务器,node1,node2,node3做为NTP客户端配置
[root@client ~]# yum -y install chrony
[root@client ~]# vim /etc/chrony.conf
allow 192.168.4.0/24 #修改26行
local stratum 10 #修改29行(去注释即可)
[root@client ~]# systemctl restart chronyd
[root@node1 ~]# vim /etc/chrony.conf
server 192.168.4.10 iburst #配置文件第二行,手动添加一行新内容
[root@node1 ~]# systemctl restart chronyd
[root@node1 ~]# chronyc sources -v #查看同步结果,应该是^*
[root@node2 ~]# vim /etc/chrony.conf
server 192.168.4.10 iburst #配置文件第二行,手动添加一行新内容
[root@node2 ~]# systemctl restart chronyd
[root@node2 ~]# chronyc sources -v #查看同步结果,应该是^*
[root@node3 ~]# vim /etc/chrony.conf
server 192.168.4.10 iburst #配置文件第二行,手动添加一行新内容
[root@node3 ~]# systemctl restart chronyd
[root@node3 ~]# chronyc sources -v #查看同步结果,应该是^*
- 环境准备完成后,关机拍摄快照
3、部署Ceph集群
3.1、安装部署软件ceph-deploy
- 在node1安装部署软件ceph-deploy
[root@node1 ~]# yum -y install ceph-deploy
[root@node1 ~]# ceph-deploy --help
[root@node1 ~]# ceph-deploy mon --help
- 创建目录(目录名称可以任意,推荐与案例一致)
[root@node1 ~]# mkdir ceph-cluster #为部署工具创建目录,存放密钥与配置文件
[root@node1 ~]# cd ceph-cluster/
[root@node1 ceph-cluster]# pwd
/root/ceph-cluster
3.2、部署Ceph 集群
- 给所有节点安装ceph相关软件包。
[root@node1 ceph-cluster]# for i in node1 node2 node3
>do
> ssh $i "yum -y install ceph-mon ceph-osd ceph-mds ceph-radosgw"
>done
-
创建Ceph集群配置,在ceph-cluster目录下生成Ceph配置文件(ceph.conf)。
在ceph.conf配置文件中定义monitor主机是谁。
[root@node1 ceph-cluster]# ceph-deploy new node1 node2 node3
[root@node1 ceph-cluster]# ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
-
初始化所有节点的mon服务,也就是启动mon服务。
拷贝当前目录的配置文件到所有节点的/etc/ceph/目录并启动mon服务。
[root@node1 ceph-cluster]# ceph-deploy mon create-initial
#配置文件ceph.conf中有三个mon的IP,ceph-deploy脚本知道自己应该远程谁
- 在每个node主机查看自己的服务(注意每台主机服务名称不同)
[root@node1 ceph-cluster]# systemctl status ceph-mon@node1
[root@node2 ~]# systemctl status ceph-mon@node2
[root@node3 ~]# systemctl status ceph-mon@node3
#备注:管理员可以自己启动(start)、重启(restart)、关闭(stop),查看状态(status).
#提醒:这些服务在30分钟只能启动3次,超过就报错.
#StartLimitInterval=30min
#StartLimitBurst=3
#在这个文件中有定义/usr/lib/systemd/system/ceph-mon@.service
#如果修改该文件,需要执行命令# systemctl daemon-reload重新加载配置
- 查看ceph集群状态(现在状态应该是health HEALTH_ERR)
[root@node1 ceph-cluster]# ceph -s
cluster d894635f-8a2e-4c78-a6cb-c1f7c9cf6798
health HEALTH_ERR
no osds
monmap e1: 3 mons at {node1=192.168.4.11:6789/0,node2=192.168.4.12:6789/0,node3=192.168.4.13:6789/0}
election epoch 6, quorum 0,1,2 node1,node2,node3
osdmap e1: 0 osds: 0 up, 0 in
flags sortbitwise
pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects
0 kB used, 0 kB / 0 kB avail
64 creating
常见错误(非必要操作,有错误可以参考):
如果提示如下错误信息:(如何无法修复说明环境准备有问题,需要重置所有虚拟机)[node1][ERROR ] admin_socket: exception getting command descriptions: [Error 2] No such file or directory解决方案如下(仅在node1操作):
a. 先检查自己的命令是否是在ceph-cluster目录下执行的!!!!如果确认是在该目录下执行的create-initial命令,依然报错,可以使用如下方式修复。[root@node1 ceph-cluster]# vim ceph.conf #文件最后追加以下内容 public_network = 192.168.4.0/24b. 修改后重新推送配置文件:
[root@node1 ceph-cluster]# ceph-deploy --overwrite-conf config push node1 node2 node3 [root@node1 ceph-cluster]# ceph-deploy --overwrite-conf mon create-initialc. 如果还出错,可能是准备实验环境时配置的域名解析和主机名不一致!!!
3.3、创建OSD
-
初始化清空磁盘数据(仅node1操作即可)。
初始化磁盘,将所有磁盘分区格式设置为GPT格式(根据实际情况填写磁盘名称)。
[root@node1 ceph-cluster]# ceph-deploy disk zap node1:sdb node1:sdc
[root@node1 ceph-cluster]# ceph-deploy disk zap node2:sdb node2:sdc
[root@node1 ceph-cluster]# ceph-deploy disk zap node3:sdb node3:sdc
#相当于ssh 远程node1,在node1执行parted /dev/sdb mktable gpt
#其他主机都是一样的操作
#ceph-deploy是个脚本,这个脚本会自动ssh远程自动创建gpt分区
-
创建OSD存储空间(仅node1操作即可)
远程所有node主机,创建分区,格式化磁盘,挂载磁盘,启动osd服务共享磁盘。
[root@node1 ceph-cluster]# ceph-deploy osd create node1:sdb node1:sdc
#每个磁盘都会被自动分成两个分区;一个固定5G大小;一个为剩余所有容量
#5G分区为Journal日志缓存;剩余所有空间为数据盘。
[root@node1 ceph-cluster]# ceph-deploy osd create node2:sdb node2:sdc
[root@node1 ceph-cluster]# ceph-deploy osd create node3:sdb node3:sdc
- 在三台不同的主机查看OSD服务状态,可以开启、关闭、重启服务。
[root@node1 ~]# systemctl status ceph-osd@0
[root@node2 ~]# systemctl status ceph-osd@2
[root@node3 ~]# systemctl status ceph-osd@4
#备注:管理员可以自己启动(start)、重启(restart)、关闭(stop),查看状态(status).
#提醒:这些服务在30分钟只能启动3次,超过就报错.
#StartLimitInterval=30min
#StartLimitBurst=3
#在这个文件中有定义/usr/lib/systemd/system/ceph-osd@.service
#如果修改该文件,需要执行命令# systemctl daemon-reload重新加载配置
常见错误及解决方法(非必须操作)。
使用osd create创建OSD存储空间时,如提示下面的错误提示:
[ceph_deploy][ERROR ] RuntimeError: bootstrap-osd keyring not found; run ‘gatherkeys’
可以使用如下命令修复文件,重新配置ceph的密钥文件:[root@node1 ceph-cluster]# ceph-deploy gatherkeys node1 node2 node3
3.4、验证测试
- 查看集群状态。
[root@node1 ceph-cluster]# ceph -s
cluster d894635f-8a2e-4c78-a6cb-c1f7c9cf6798
health HEALTH_OK
monmap e1: 3 mons at {node1=192.168.4.11:6789/0,node2=192.168.4.12:6789/0,node3=192.168.4.13:6789/0}
election epoch 6, quorum 0,1,2 node1,node2,node3
osdmap e29: 6 osds: 6 up, 6 in
flags sortbitwise
pgmap v56: 64 pgs, 1 pools, 0 bytes data, 0 objects
202 MB used, 91891 MB / 92093 MB avail
64 active+clean
[root@node1 ceph-cluster]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.08752 root default
-2 0.02917 host node1
0 0.01459 osd.0 up 1.00000 1.00000
1 0.01459 osd.1 up 1.00000 1.00000
-3 0.02917 host node2
2 0.01459 osd.2 up 1.00000 1.00000
3 0.01459 osd.3 up 1.00000 1.00000
-4 0.02917 host node3
4 0.01459 osd.4 up 1.00000 1.00000
5 0.01459 osd.5 up 1.00000 1.00000
-
常见错误(非必须操作)。
如果查看状态包含如下信息:
health: HEALTH_WARN
clock skew detected on node2, node3…
clock skew表示时间不同步,解决办法:请先将所有主机的时间都使用NTP时间同步!!!
Ceph要求所有主机时差不能超过0.05s,否则就会提示WARN。
如果状态还是失败,可以尝试执行如下命令,重启所有ceph服务:
[root@node1 ceph-cluster]# systemctl restart ceph.target
3.5、扩展知识:创建ceph用户,查看用户
[root@node1 ~]# ceph auth get-or-create client.nb \
osd 'allow *' \
mds 'allow *' \
mon 'allow *' > 文件名
# >是重定向导出,后面的文件名可以任意,没有文件会创建,有文件则会覆盖文件的内容
[root@node1 ~]# ceph auth list #查看所有用户列表
4、Ceph块存储
-
什么是块存储
- 光盘
- 磁盘
-
分布式块存储
- Ceph
- Cinder
-
Ceph块设备也叫做RADOS块设备
- RADOS block device : RBD
-
RBD驱动已经很好的集成在了Linux内核中
-
RBD提供了企业功能,如快照、COW克隆等等
-
RBD还支持内存缓存,从而能够大大的提高性能
4.1、创建镜像
- 查看存储池,默认存储池名称为rbd。
[root@node1 ceph-cluster]# ceph osd lspools
0 rbd,
#查看结果显示,共享池的名称为rbd,这个共享池的编号为0,英语词汇:pool(池塘、水塘)
- 创建镜像、查看镜像
[root@node1 ceph-cluster]# rbd create demo-image --image-feature layering --size 10G
#创建demo-image镜像,这里的demo-image创建的镜像名称,名称可以为任意字符。
#size可以指定镜像大小
[root@node1 ceph-cluster]# rbd create rbd/jacob --image-feature layering --size 10G
#在rbd池中创建名称为jacob的镜像(rbd/jacob),镜像名称可以任意
#--image-feature参数指定我们创建的镜像有哪些功能,layering是开启COW功能。
#提示:ceph镜像支持很多功能,但很多是操作系统不支持的,我们只开启layering。
[root@node1 ceph-cluster]# rbd list #列出所有镜像
demo-image
jacob
[root@node1 ceph-cluster]# rbd info demo-image #查看demo-image这个镜像的详细信息
rbd image 'demo-image':
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.5e38238e1f29
format: 2
features: layering
flags:
[root@node1 ceph-cluster]# rbd info jacob
rbd image 'jacob':
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.5e3b238e1f29
format: 2
features: layering
flags:
4.2、动态调整
- 扩容容量
[root@node1 ceph-cluster]# rbd resize --size 15G jacob
#调整jacob镜像的大小,jacob是镜像的名称,size指定扩容到15G
Resizing image: 100% complete...done.
[root@node1 ceph-cluster]# rbd info jacob
rbd image 'jacob':
size 15360 MB in 3840 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.5e3b238e1f29
format: 2
features: layering
flags:
- 缩小容量
[root@node1 ceph-cluster]# rbd resize --size 7G jacob --allow-shrink
#英文词汇:allow(允许),shrink(缩小)
Resizing image: 100% complete...done.
[root@node1 ceph-cluster]# rbd info jacob
rbd image 'jacob':
size 7168 MB in 1792 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.5e3b238e1f29
format: 2
features: layering
flags:
#查看jacob这个镜像的详细信息(jacob是前面创建的镜像)
4.3、通过KRBD访问
Linux内核可用直接访问Ceph块存储,KVM可用借助于librbd访问Ceph块存储。
客户端访问结构如图所示
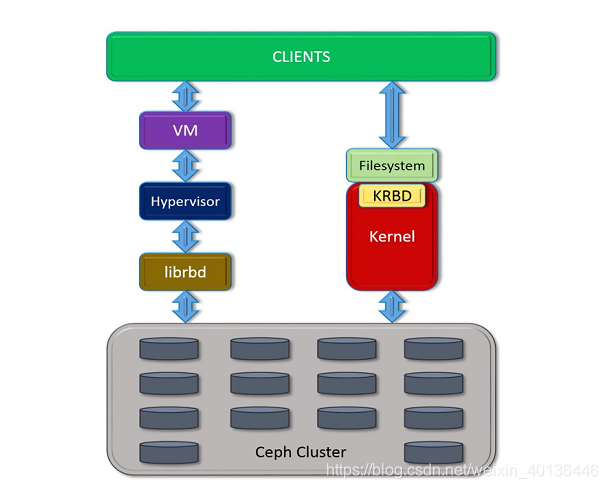
- 客户端通过KRBD访问
#客户端需要安装ceph-common软件包
#拷贝配置文件(否则不知道集群在哪)
#拷贝连接密钥(否则无连接权限)
[root@client ~]# yum -y install ceph-common
[root@client ~]# scp 192.168.4.11:/etc/ceph/ceph.conf /etc/ceph/
[root@client ~]# scp 192.168.4.11:/etc/ceph/ceph.client.admin.keyring /etc/ceph/
[root@client ~]# rbd map jacob #客户端访问映射服务器的jacob共享镜像
/dev/rbd0
[root@client ~]# rbd map demo-image #客户端访问映射服务器的demo-image共享镜像
/dev/rbd1
[root@client ~]# lsblk #查看结果(会多一块磁盘)
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sr0 11:0 1 284M 0 rom /ceph
sr1 11:1 1 8.8G 0 rom /mydvd
rbd0 252:0 0 7G 0 disk /mnt
rbd1 252:16 0 10G 0 disk
[root@client ~]# rbd showmapped #查看磁盘名和共享镜像名称的对应关系
id pool image snap device
0 rbd jacob - /dev/rbd0
1 rbd demo-image - /dev/rbd1
- 客户端格式化、挂载分区
[root@client ~]# mkfs.xfs /dev/rbd1 #格式化,格式为xfs
[root@client ~]# mount /dev/rbd1 /mnt/ #挂载(可以挂载到任意目录)
[root@client ~]# echo "test" > /mnt/test.txt #写入数据
[root@client ~]# cat /mnt/test.txt
test
4.4、删除镜像
- 客户端撤销磁盘映射
[root@client ~]# umount /mnt #卸载
[root@client ~]# rbd showmapped #查看磁盘名和共享镜像名称的对应关系
id pool image snap device
0 rbd jacob - /dev/rbd0
1 rbd demo-image - /dev/rbd1
[root@client ~]# rbd unmap /dev/rbd1 #撤销磁盘映射
[root@client ~]# rbd showmapped
id pool image snap device
0 rbd jacob - /dev/rbd0
5、块存储应用案例
5.1、创建镜像快照
- 查看镜像快照(默认所有镜像是没有快照的)
[root@node1 ceph-cluster]# rbd snap ls jacob
#查看某个镜像有没有快照,jacob是镜像的名称,ls是list查看
- 给镜像创建快照
[root@node1 ceph-cluster]# rbd snap create jacob --snap jacob-snap1
#为jacob镜像创建快照,--snap指定快照名称,快照名称为jacob-snap1,快照名称可以任意
[root@node1 ceph-cluster]# rbd snap ls jacob
SNAPID NAME SIZE
4 jacob-snap1 7168 MB
- 删除客户端写入的测试文件
[root@client ~]# rm -rf /mnt/test.txt
[root@client ~]# umount /mnt
- 还原快照
[root@node1 ceph-cluster]# rbd snap rollback jacob --snap jacob-snap1
# rollback是回滚的意思,使用jacob-snap1快照回滚数据,对jacob镜像进行回滚数据
[root@client ~]# mount /dev/rbd0 /mnt/ #客户端重新挂载分区
[root@client ~]# ls /mnt #查看数据是否被恢复
5.2、创建快照克隆
- 克隆快照
[root@node1 ceph-cluster]# rbd snap list jacob
SNAPID NAME SIZE
4 jacob-snap1 7168 MB
[root@node1 ceph-cluster]# rbd snap protect jacob --snap jacob-snap1 #保护快照
#jacob是镜像名称,jacob-snap1是前面创建的快照(被保护的快照,不可以被删除)
[root@node1 ceph-cluster]# rbd snap rm jacob --snap jacob-snap1 #删除被保护的快照,会失败
rbd: snapshot 'jacob-snap1' is protected from removal.
2020-07-30 23:42:27.226184 7f1e8973fd80 -1 librbd::Operations: snapshot is protected
[root@node1 ceph-cluster]# rbd clone jacob --snap jacob-snap1 jacob-clone --image-feature layering
#使用jacob镜像的快照jacob-snap1克隆一个新的名称为jacob-clone的镜像
#新镜像名称可以任意
- 查看克隆镜像与父镜像快照的关系
[root@node1 ceph-cluster]# rbd list
demo-image
jacob
jacob-clone
[root@node1 ceph-cluster]# rbd info jacob-clone
rbd image 'jacob-clone':
size 7168 MB in 1792 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.5e55238e1f29
format: 2
features: layering
flags:
parent: rbd/jacob@jacob-snap1
overlap: 7168 MB
#克隆镜像的很多数据都来自于快照链
#如果希望克隆镜像可以独立工作,就需要将父快照中的数据,全部拷贝一份,但比较耗时!!!
- 让新克隆的镜像与快照脱离关系
[root@node1 ~]# rbd flatten jacob-clone #让新克隆的镜像与快照脱离关系
[root@node1 ~]# rbd info jacob-clone #查看镜像信息
rbd image 'jacob-clone':
size 7168 MB in 1792 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.5e55238e1f29
format: 2
features: layering
flags:
#注意,父快照信息没了!
- 删除快照
[root@node1 ceph-cluster]# rbd snap unprotect jacob --snap jacob-snap1 #取消快照保护
[root@node1 ceph-cluster]# rbd snap rm jacob --snap jacob-snap1 #可以删除快照
[root@node1 ceph-cluster]# rbd snap ls jacob
6、Ceph文件系统
-
块共享,仅允许同时一个客户端访问,无法实现多人同时使用块设备。
-
而Ceph的文件系统共享则允许多人同时使用。
6.1、什么是CephFS
- 分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。
- CephFS使用Ceph集群提供与POSIX兼容的文件系统
- 允许Linux直接将Ceph存储mount到本地
6.2、什么是元数据
- 元数据(Metadata)
- 任何文件系统中的数据分为数据和元数据
- 数据是指普通文件中的实际数据
- 而元数据指用来描述一个文件的特征到的系统数据
- 比如:访问权限、文件拥有者以及文件数据库的分布信息(inode)等
6.3、部署元数据服务器
- 使用虚拟机node3,部署MDS节点
| 主机名称 | IP地址 |
|---|---|
| node3 | 192.168.4.13 |
-
要求如下:
IP地址:192.168.4.13
主机名:node3
配置yum源(包括操作系统的源、ceph的源)
与Client主机同步时间
node1允许无密码远程node3
修改node1的/etc/hosts,并同步到所有node主机
部署元数据服务器 -
安装软件
[root@node3 ~]# yum -y install ceph-mds
- 登陆node1部署节点操作
[root@node1 ~]# cd /root/ceph-cluster
#该目录,是最早部署ceph集群时,创建的目录
[root@node1 ceph-cluster]# ceph-deploy mds create node3
#远程nod3,拷贝集群配置文件,启动mds服务
- 创建存储池
备注:一个文件系统是由inode和block两部分组成,效果如图-1所示。
inode存储文件的描述信息(metadata元数据),block中存储真正的数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GK8GEBN4-1598752772810)(https:#img-blog.csdnimg.cn/20200731140330651.png)]
[root@node3 ~]# ceph osd pool create cephfs_data 64
#创建存储池,共享池的名称为cephfs_data,对应有64个PG
#共享池名称可以任意
[root@node3 ~]# ceph osd pool create cephfs_metadata 64
#创建存储池,共享池的名称为cephfs_metadata,对应有64个PG
- PG拓扑
PG是一个逻辑概念,没有对应的物质形态,是为了方便管理OSD而设计的概念。
为了方便理解,可以把PG想象成为是目录,可以创建32个目录来存放OSD,也可以创建64个目录来存放OSD。
6.4、创建Ceph文件系统
[root@node3 ~]# ceph fs new myfs1 cephfs_metadata cephfs_data
#myfs1是名称,名称可以任意,注意,先写metadata池,再写data池
#fs是filesystem的缩写,filesystem中文是文件系统
#默认,只能创建1个文件系统,多余的会报错
[root@node3 ~]# ceph fs ls
name: myfs1, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
6.5、客户端挂载
客户端挂载(客户端需要安装ceph-common,前面已经安装)
[root@client ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQByhCFfC4HwKBAABv3PCDF8siwPlq4JlwYPAQ==
[root@client ~]# mount -t ceph 192.168.4.11:6789:/ /mnt -o name=admin,secret=AQBTsdRapUxBKRAANXtteNUyoEmQHveb75bISg==
#注意:-t(type)指定文件系统类型,文件系统类型为ceph
#-o(option)指定mount挂载命令的选项,选项包括name账户名和secret密码
#192.168.4.11为MON节点的IP(不是MDS节点),6789是MON服务的端口号
#admin是用户名,secret后面是密钥
#密钥可以在/etc/ceph/ceph.client.admin.keyring中找到
[root@client ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17G 1.3G 16G 8% /
devtmpfs 224M 0 224M 0% /dev
tmpfs 236M 0 236M 0% /dev/shm
tmpfs 236M 5.6M 230M 3% /run
tmpfs 236M 0 236M 0% /sys/fs/cgroup
/dev/sr0 284M 284M 0 100% /ceph
/dev/sr1 8.8G 8.8G 0 100% /mydvd
/dev/sda1 1014M 130M 885M 13% /boot
192.168.4.11:6789:/ 90G 364M 90G 1% /mnt
tmpfs 48M 0 48M 0% /run/user/0
7、对象存储服务器
7.1、什么是对象存储
-
对象存储
- 也就是键值存储,通其接口指令,也就是简单的GET、PUT、DEL和其他扩展,向存储服务上传下载数据
- 对象存储中所有数据都被认为是一个对象,所以,任何数据都可以存入对象存储服务器,如图片、视频、音频等
-
RGW全称是Rados Gateway
-
RGW是Ceph对象存储网关,用于向客户端应用呈现存储界面,提供RESTful API访问接口
7.2、创建对象存储
-
准备实验环境,要求如下:
IP地址:192.168.4.13
主机名:node3
配置yum源(包括操作系统的源、ceph的源)
与Client主机同步时间
node1允许无密码远程node3
修改node1的/etc/hosts,并同步到所有node主机
-
部署RGW软件包
[root@node3 ~]# yum -y install ceph-radosgw
-
新建网关实例
拷贝配置文件,启动一个rgw服务
[root@node1 ~]# cd /root/ceph-cluster
[root@node1 ceph-cluster]]# ceph-deploy rgw create node3 #远程mode3启动rgw服务
- 登陆node3验证服务是否启动
[root@node3 ~]# ps aux |grep radosgw
root 1285 0.0 0.2 112720 984 pts/0 D+ 15:53 0:00 grep --color=auto radosgw
ceph 131059 0.4 3.1 2290320 15180 ? Ssl 15:52 0:00 /usr/bin/radosgw -f --cluster ceph --name client.rgw.node3 --setuser ceph --setgroup ceph
[root@node3 ~]# systemctl status ceph-radosgw@\*
- 修改服务端口
[root@node3 ~]# vim /etc/ceph/ceph.conf
·········省略部分内容
[client.rgw.node3]
host = node3
rgw_frontends = "civetweb port=8000"
#node3为主机名
#civetweb是RGW内置的一个web服务
[root@node3 ~]# systemctl restart ceph-radosgw@\*
7.3、客户端测试
- curl测试
[root@client ~]# curl 192.168.4.13:8000
- 使用第三方软件访问
登陆node3(RGW)创建账户
[root@node3 ~]# radosgw-admin user create \
> --uid="testuser" --display-name="First User"
{
"user_id": "testuser",
"display_name": "First User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "testuser",
"access_key": "G05OCFYUM53JLCKJ34UA",
"secret_key": "jDELhwqUvnevawsjDWmz9kuWaH8njTkYB50roNoE"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"temp_url_keys": []
}
[root@node3 ~]# radosgw-admin user info --uid=testuser #testuser为用户名,access_key和secret_key是账户密钥
{
"user_id": "testuser",
"display_name": "First User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "testuser",
"access_key": "G05OCFYUM53JLCKJ34UA",
"secret_key": "jDELhwqUvnevawsjDWmz9kuWaH8njTkYB50roNoE"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"temp_url_keys": []
}
- 客户端安装软件(软件需要自己上网搜索下载)
[root@client ~]# yum install s3cmd-2.0.1-1.el7.noarch.rpm
修改软件配置(注意,除了下面设置的内容,其他提示都默认回车)
[root@client ~]# s3cmd --configureAccess Key: 5E42OEGB1M95Y49IBG7BSecret Key: i8YtM8cs7QDCK3rTRopb0TTPBFJVXdEryRbeLGK6S3 Endpoint [s3.amazonaws.com]: 192.168.4.13:8000[%(bucket)s.s3.amazonaws.com]: %(bucket)s.192.168.4.13:8000Use HTTPS protocol [Yes]: NoTest access with supplied credentials? [Y/n] nSave settings? [y/N] y#注意,其他提示都默认回车
- 创建存储数据的bucket(类似于存储数据的目录)
[root@client ~]# s3cmd ls[root@client ~]# s3cmd mb s3:#my_bucketBucket 's3:#my_bucket/' created[root@client ~]# s3cmd ls2018-05-09 08:14 s3:#my_bucket[root@client ~]# s3cmd put /var/log/messages s3:#my_bucket/log/[root@client ~]# s3cmd ls s3:#my_bucketDIR s3:#my_bucket/log/[root@client ~]# s3cmd ls s3:#my_bucket/log/2018-05-09 08:19 309034 s3:#my_bucket/log/messages
- 测试下载功能
[root@client ~]# s3cmd get s3:#my_bucket/log/messages /tmp/
- 测试删除功能
[root@client ~]# s3cmd del s3:#my_bucket/log/messages
来源:oschina
链接:https://my.oschina.net/u/4405841/blog/4540261