今年的ISCA中有一个Tutorial[2]和三篇论文[3-5],直接和推荐系统的加速有关。以此为起点,本文讨论一下如何加速推荐系统这个问题。推荐系统的优化和加速是一个系统性问题。本文主要围绕Facebook的一些分析和工作,后续可能进行更多的讨论。
我们每打开一个App或者访问一个网站,呈现在我们面前的内容有很大的可能就是推荐系统工作的成果。它们都是推荐系统基于用户和“商品”的各种信息(特征),对用户动作进行预测后推送给我们的。和搜索引擎根据明确的搜索请求返回结果不同,推荐系统是主动去”猜“用户”想要什么“,能够在”信息过载“的情况下,推送最合适的内容,这是一个好的推荐系统能够给用户带来的最大的价值。
而对”商品“提供者来说,推荐系统的价值和重要性也是不言而喻的。引用王喆老师的《深度学习推荐系统》[6]中的例子,2019年天猫”双11“的成交额是2684亿元,而天猫的推荐系统实现了首页商品的个性化推荐,其目标是提高转化率和点击率。假设推荐系统进行了优化,整体的转化率提高1%,那么增加的成交额大约就是26.84亿。有这么明确的收益,我们不难想象互联网巨头优化推荐系统的动力。另一个例子是,在ISCA的tutorial[2]中,百度的同学介绍他们为什么在广告推荐系统中使用一个巨大的模型(10TB)而不能进行压缩的时候,给出的原因就是,尝试压缩后的模型会导致0.1%左右的AUC(推荐系统评价标准)下降,直接导致营收下降,这是不能接受的。类似的例子还有很多,总的来说就是,现在的推荐系统往往是直接和营收挂钩的。
因此,“如何加速(优化)推荐系统?”当然是一个高价值问题。
对于不同应用,不同公司,不同商业模式,推荐系统的目标和具体的设计也是有所偏重的。即使是同一类应用,也可能同时存在不同的推荐模式。比如一个视频应用,可能同时存在两种类型的推荐,视频内容推荐和广告推荐。前者是要在大量的视频中快速找到用户可能感兴趣,会点击观看的内容。如果商业模式是观看时间越长,可以插播越多广告,那么推荐的视频还会希望用户尽量长时间观看。后者则是希望推荐的广告是用户可能点击,可以直接转化为广告收入的。此外,不同的应用场景,对于推荐的性能要求也有差别,特别是有些场景对实时性有较高要求,这类情况可能就需要在高准确度(往往需要更多数据和更复杂的模型)和低延时上做tradeoff;或者是throughput和latency间的tradeoff。除了推荐的内容和模式的差别,不同应用能获得或者利用的用户特征(除了用户的基本信息,如性别,年龄等等)也是有所不同的。电商可以获得用户访问和购买商品的信息,那么它给出的推荐主要就是依据这些信息;搜索引擎,可以根据用户的搜索请求和搜索记录给出广告推荐;视频应用可以根据用户的观看记录;社交网络可以依据用户的关系等等。类似的,不同应用提供的”商品“特征也不尽相同。此外,推荐系统往往需要大规模的数据和模型,由于不同公司的技术能力和基础设施水平的差异,推荐系统部署的策略也不尽相同。总之,不同类型的应用,不同公司,在推荐系统的设计和部署中可能存在很大差异(可以参考[6]),这也是我们讨论推荐系统加速问题的一个挑战。
在这次的ISCA的相关tutorial和paper中,很多内容都和Facebook的推荐系统有关,也有比较完整的讨论思路。本文主要是结合这个思路来进行分析。
Facebook的推荐系统优化实践
首先,在PeRSonAl at ISCA2020[2]之前,今年的ASPLOS上也有个PeRSonAl的tutorial,大家也可以参考。在更早的一篇blog,”Deep Learning: It’s Not All About Recognizing Cats and Dogs“[1],Facebook研究人员介绍了推荐系统实际的应用情况。在Facebook,个性推荐在整个AI Inference处理中占了80%左右(占Training的大约占50%),每天大约会做300个Trillions以上的预测。
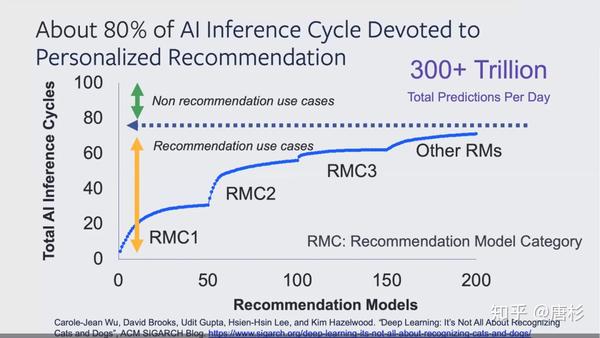
 source:" Introduction to PeRSonAl‘,PeRSonAl Tutorial at ISCA
source:" Introduction to PeRSonAl‘,PeRSonAl Tutorial at ISCA
同时,这篇文章还总结了推荐系统优化的几个挑战,后面的一些工作主要也是围绕这些挑战展开。
- Optimizing recommendation translates to large capacity saving: DNN-based personalized recommendation lays an important foundation for many machine learning-powered ranking problems in industries. However, it is less well understood and studied while presenting ample room for optimization. (推荐系统的优化确实有很大空间和很多的可能性,而这个问题目前也越来越受关注,从这次的ISCA也可以看出来。)
- Memory system optimization is the key: For an important subset of personalized recommendation, memory capacity and off-chip memory bandwidth is the primary performance limiting factor. (由于推荐系统涉及的数据和模型的规模巨大,而相对的计算密度比较低,数据访问呈现稀疏不规则的特征,很多情况是受限于内存的容量和访存的带宽的。)
- One size does not fit all: As we build accelerators for this important class of recommendation workloads, we have to be mindful about the balance between flexibility and acceleration efficiency. (针对一个具体的瓶颈问题进行加速的同时,还需要考虑这种加速是否具有灵活性。)
- Full system stack designs enable efficient yet flexible acceleration: Programmability is a critical, but often an overlooked aspect of high performance and efficiency delivery in accelerator-enabled systems. As more and more acceleration logics are making their way into datacenter at scale, being able to program these accelerators to extract the promised theoretical peak TFLOP performance requires a meticulously designed software stack.(推荐系统的加速在技术栈上需要全栈的综合考虑,而在规模上可能是大规模计算集群,是个复杂的系统优化问题。)
当我们考虑对一个应用或者算法进行加速的时候,首先需要对其计算模式进行分析。Facebook在之前的论文”The Architectural Implications of Facebook's DNN-based Personalized Recommendation“[7]中就做了大量的分析工作。
首先,我们看一下对Facebook使用的DNN模型:DLRM[8](开源模型)的简单分析。
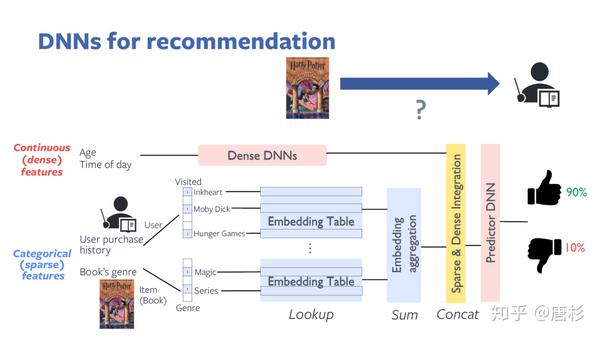 source:"At-scale Inference for Recommendation Systems",PeRSonAl Tutorial at ASPLOS
source:"At-scale Inference for Recommendation Systems",PeRSonAl Tutorial at ASPLOS
DLRM从模型的角度来说是个相对简单实用的推荐模型,并没有使用很复杂的神经网络。上图主要是一个inference的例子。它的输入是特征(feature),包括稠密特征(dense feature,一般是连续的数值),比如这个例子中的用户的年龄和访问的时间;稀疏特征(sparse feature),或者说分类的特征,比如这个例子中的用户购买记录,和推荐书籍的类型。稀疏特征用one-hot编码。在做inference的过程中,首先是在Embedding Table(可能是与训练的结果)里面找到后面进行预测所需要的Embedding向量,而稀疏特征实际就是这个查表过程的索引。找到相应的Embedding向量(比如对应于用户购买过的所有书籍)后,进行一个求和(sum)的操作变成一个向量,然后和连续向量(经过了一个DNN网络的处理)进行一个连接(concat)的操作,最后进入一个预测用的DNN网络(MLP,全连接网络)最终得到预测结果,对点击率的估计。
从这个例子我们可以看出几个直观的信息。第一,稀疏特征可能非常稀疏,比如例子中的用户购买历史,这个向量的大小是所有书籍的数量,而用户购买过的,只是很小的一部分(这部分用1表示,其它都是0)。第二,Embedding Table不止一个,而且可能很大,比如这个例子中的第一个Embedding Table,就是包括了所有书籍的Embedding向量。第三,对多个Embedding Table的查找没有规律。
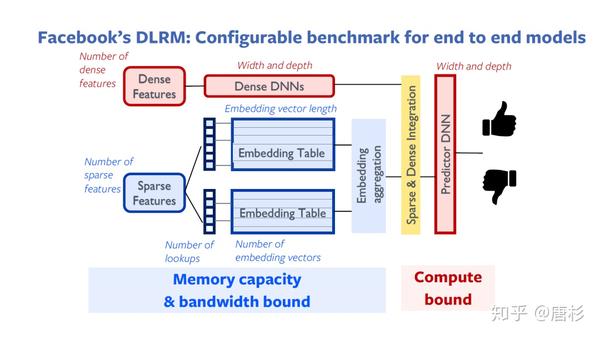 source:"At-scale Inference for Recommendation Systems",PeRSonAl Tutorial at ASPLOS
source:"At-scale Inference for Recommendation Systems",PeRSonAl Tutorial at ASPLOS
在了解了具体的处理过程之后,我们就能够比较容易的分析出瓶颈性问题。第一,巨大的Embedding Table的存储问题(Memory capacity bound);第二,Embedding Table的稀疏无规律查找问题(Memory bandwidth bound);第三是DNN处理(Compute bound)。
DLRM虽然是个比较简单的模型,但是它的结构是具有一定普遍性的。下图(来自论文[4])就把这类推荐模型的分析推广到一个更具一般性的问题。
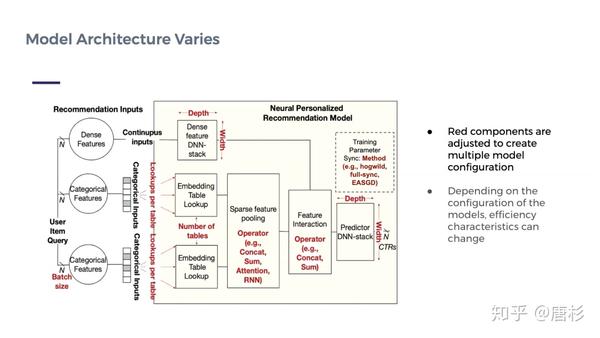 source:"Ins and Outs of Using GPUs for Training Recommendation Models", PeRSonAl Tutorial at ISCA
source:"Ins and Outs of Using GPUs for Training Recommendation Models", PeRSonAl Tutorial at ISCA
在这个图中,红色的部分为不同推荐模型实现中可变的配置(包括不同的模型,算法和参数等)。配置不同,计算瓶颈也不一样。下表[4]则是一些比较知名的公开推荐模型的配置情况。
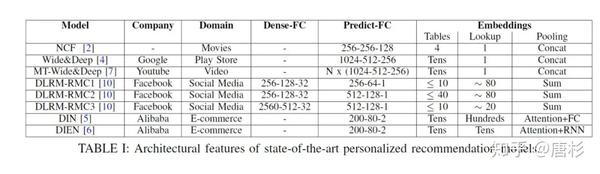
从这个表中我们可以看出,Facebook使用了三种不同的DLRM模型(RMC1,2,3),它们的配置也不尽相同。因此,它们的计算特征也有差别,后面可以看到它们属于不同的分类。[7]对这几个模型在实际系统中的表现做了非常详尽的分析。这里的细节我就不赘述了,感兴趣的朋友可以自己去看看。简而言之,这篇文章“...illustrates how Facebook’s personalized recommendation models are dominated by embedding table operations.”(来自[3]),即Facebook的推荐模型的性能主要取决于embedding table的处理能力(代表性的操作为SLS: SparseLengthsSum)。这也直接引出论文“RecNMP: Accelerating Personalized Recommendation with Near-Memory Processing”的工作[3],在存储器(DDR4 DIMM)的buffer芯片里面增加一个简单的处理单元,完成对稀疏查表和加法的加速。结合之前的分析,这个做法就是很自然而然的优化了。同样,ISCA的另一篇加速器论文,“Centaur: A Chiplet-Based, Hybrid Sparse-Dense Accelerator for Personalized Recommendations”[5],也是试图解决类似的问题,具体方法是:基于CPU+FPGA的chiplet芯片,利用FPGA访问CPU的系统memory(存放Embedding Table)有很高带宽这一特性,在FPGA中实现对Embedding Table访问的加速,同时实现对稠密矩阵运算(DNN)的加速。细节就不赘述了。
优化推荐系统是个系统性问题
前面也提到了,推荐系统的运行,往往需要一个大规模计算平台,而优化推荐系统,也是一个系统性问题。
在这次ISCA的tutorial中,我们也看到百度的分享“Training Massive Scale Deep Learning Ads Systems with GPUs and SSDs”(包括了论文[9][10]),讨论的挑战主要是一个大规模的模型(10TB级别)怎么利用GPU系统进行加速的问题。而Facebook的“Ins and Outs of Using GPUs for Training Recommendation Models”则分享了很多CPU+GPU系统实际部署时的tradeoff和实践经验,也很有参考价值。这些工作中反映出的问题是在一定的硬件平台约束下,如何优化整体推荐系统的。
带着类似的问题,论文“DeepRecSys: A System for Optimizing End-To-End At-scale Neural Recommendation Inference”[4],就试图把不同的推荐模型(NCF, WnD, MT-WnD, DLRM, DIN, DIEN),服务要求(queries per second (QPS)),业务特征(Query Arrival Pattern),硬件平台(CPU,GPU,加速器)这些因素综合在一起构成一个推荐系统Inference性能分析平台(下图)。
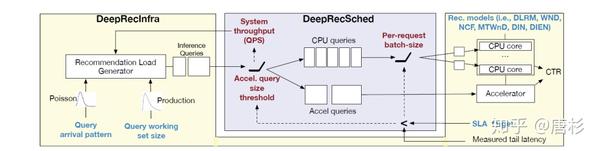
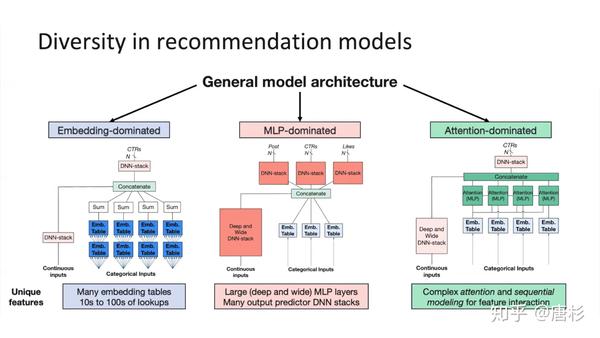
这篇文章也分享了一些有意思的分析和测试结果,比如对模型进行的分类:Embedding主导(主要是查表,比如DLRM-RMC1, DLRM-RMC2),MLP主导(主要是全连接层计算,比如DLRM-RMC3, NCF, WND, MT-WND)和Attention主导(主要是attention层,DIN, DIEN)。当然,我觉得可能不是所有模型都能明确归到其中一类。
下图是不同模型具体操作的分解。
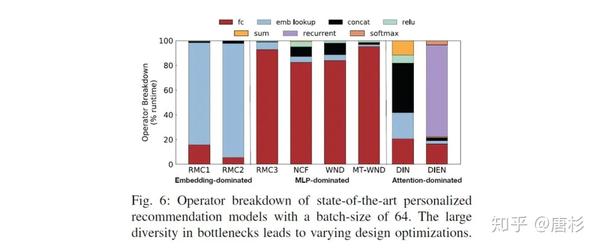
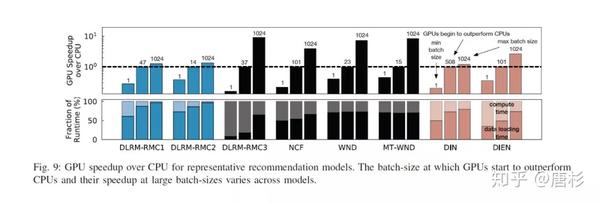
下图为GPU相对CPU的加速效果和batch size的关系,可以看出对于Embedding主导的模型,即使用比较大的batch size,GPU相对CPU的加速也很有限。而对于相对而言计算密集的模型,GPU能体现加速效果也需要比较大的batch size,这个结论也是符合我们的预期的。
总结一下,推荐系统的优化和加速既是一个高价值的问题,也是个很有趣的问题,涉及方方面面的思考。如果再把算法的演进考虑进来,比如图神经网络在推荐系统中的应用,研究和探索的空间就更加广阔了,我也非常欢迎感兴趣的朋友找我交流讨论。
最后做个小广告。我们把近年的体系结构顶会论文和AI加速相关的内容做了一些梳理,形成一个paper list
(https://birenresearch.github.io/AIChip_Paper_List/),供大家大家参考。我们会持续更新,欢迎大家多提意见,多多支持。
Reference:
[1] Carole-Jean Wu, David Brooks, Udit Gupta, Hsien-Hsin Lee, and Kim Hazelwood. "Deep Learning: It’s Not All About Recognizing Cats and Dogs", ACM SIGARCH GLOG[2] "Personalized Recommendation System and Algorithms", https://personal-tutorial.com/
[3] Liu Ke, Udit Gupta, Carole-Jean Wu, Benjamin Youngjae Cho, Mark Hempstead, Brandon Reagen, Xuan Zhang, David Brooks, Vikas Chandra, Utku Diril, Amin Firoozshahian, Kim Hazelwood, Bill Jia, Hsien-Hsin S. Lee, Meng Li, Bert Maher, Dheevatsa Mudigere, Maxim Naumov, Martin Schatz, Mikhail Smelyanskiy, Xiaodong Wang. “RecNMP: Accelerating Personalized Recommendation with Near-Memory Processing", ISCA 2020
[4] Udit Gupta, Samuel Hsia, Vikram Saraph, Xiaodong Wang, Brandon Reagen, Gu-Yeon Wei, Hsien-Hsin S. Lee, David Brooks, Carole-Jean Wu. "DeepRecSys: A System for Optimizing End-To-End At-scale Neural Recommendation Inference", ISCA 2020
[5] Ranggi Hwang, Taehun Kim, Youngeun Kwon, Minsoo Rhu. "Centaur: A Chiplet-Based, Hybrid Sparse-Dense Accelerator for Personalized Recommendations", ISCA 2020
[6] 王喆,《深度学习推荐系统》,电子工业出版社
[7] Udit Gupta, Carole-Jean Wu, Xiaodong Wang, Maxim Naumov, Brandon Reagen, David Brooks, Bradford Cottel, Kim Hazelwood, Bill Jia, Hsien-Hsin S. Lee, Andrey Malevich, Dheevatsa Mudigere, Mikhail Smelyanskiy, Liang Xiong, Xuan Zhang. "The Architectural Implications of Facebook's DNN-based Personalized Recommendation", HPCA20
[8] Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G. Azzolini, Dmytro Dzhulgakov, Andrey Mallevich, Ilia Cherniavskii, Yinghai Lu, Raghuraman Krishnamoorthi, Ansha Yu, Volodymyr Kondratenko, Stephanie Pereira, Xianjie Chen, Wenlin Chen, Vijay Rao, Bill Jia, Liang Xiong, Misha Smelyanskiy. "Deep Learning Recommendation Model for Personalization and Recommendation Systems", arXiv:1906.00091
[9] Weijie Zhao, Deping Xie, Ronglai Jia, Yulei Qian, Ruiquan Ding, Mingming Sun, Ping Li. "Distributed Hierarchical GPU Parameter Server for Massive Scale Deep Learning Ads Systems", MLSys'20
[10] Weijie Zhao, Jingyuan Zhang, Deping Xie, Yulei Qian, Ronglai Jia, Ping Li. "AIBox: CTR Prediction Model Training on a Single Node", CIKM'19
题图来自网络,版权归原作者所有
本文为个人兴趣之作,仅代表本人观点,与就职单位无关
欢迎关注我的微信公众号:
人工智能芯片技术进步 mp.weixin.qq.com来源:oschina
链接:https://my.oschina.net/u/4357381/blog/4406648