一、Java基础
Arraylist和LinkedList的区别 底层实现原理
Arraylist:底层是基于动态数组,根据下表随机访问数组元素的效率高,向数组尾部添加元素的效率高;但是,删除数组中的数据以及向数组中间添加数据效率低,因为需要移动数组。
Linkedlist基于链表的动态数组,数据添加删除效率高,只需要改变指针指向即可,但是访问数据的平均效率低,需要对链表进行遍历。
对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
“==”和“equals”区别 hashcode是什么

垃圾回收算法;分代回收中新生代采用的方法,老年代的方法
标记清除算法 复制算法(新生代算法) 标记整理算法(老年代回收算法)
String StringBuilder StringBuffer 区别

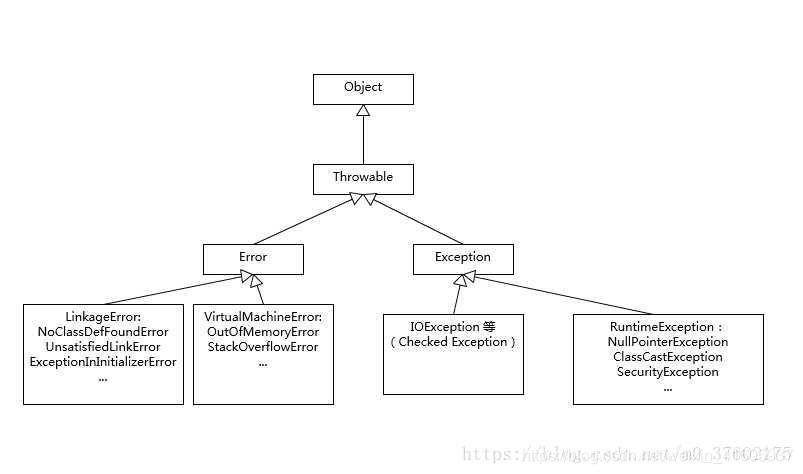
Error和Exception的区别,举例……
Exception和Error都是继承了Throwable类,在java中只有Throwable类型的实例才可以被抛出(throw)或者捕获(catch),他是异常处理机制的基本组成类型。
Exception和Error体现了java平台设计者对不同异常情况的分类,Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应的处理。
Error是指正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序(比如JVM自身)处于非正常状态,不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如OutOfMemoryError之类,都是Error的子类。
Exception又分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源码里必须显示的进行捕获处理,这里是编译期检查的一部分。前面我们介绍的不可查的Error,是Throwable不是Exception。
不检查异常就是所谓的运行时异常,类似NullPointerException,ArrayIndexOutOfBoundsExceptin之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译器强制要求。
数据库中事务特征:原子性的含义
一个事务包含多个操作,这些操作要么全部执行,要么全都不执行。实现事务的原子性,要支持回滚操作,在某个操作失败后,回滚到事务执行之前的状态。
回滚实际上是一个比较高层抽象的概念,大多数DB在实现事务时,是在事务操作的数据快照上进行的(比如,MVCC),并不修改实际的数据,如果有错并不会提交,所以很自然的支持回滚。
而在其他支持简单事务的系统中,不会在快照上更新,而直接操作实际数据。可以先预演一边所有要执行的操作,如果失败则这些操作不会被执行,通过这种方式很简单的实现了原子性。
二、计网
三次握手
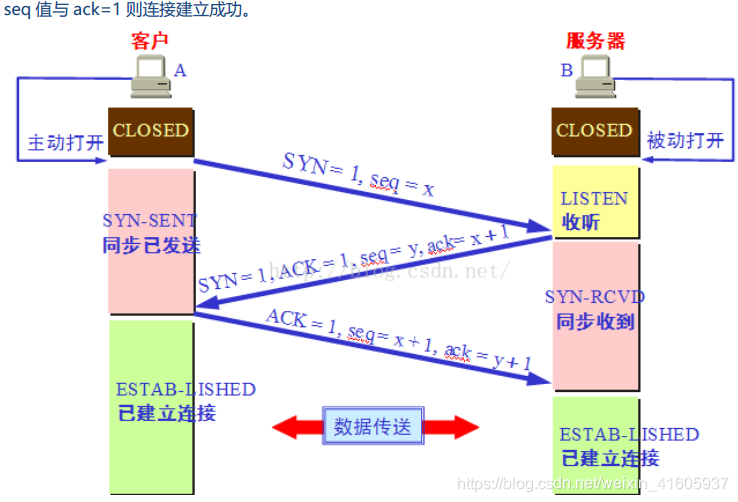
第一次握手:主机 A 发送位码为 syn=1,随机产生 seq number=1234567 的数据包到服务器,主机 B由 SYN=1 知道, A 要求建立联机;
第 二 次 握 手 : 主 机 B 收 到 请 求 后 要 确 认 联 机 信 息 , 向 A 发 送 ack number=( 主 机 A 的seq+1),syn=1,ack=1,随机产生 seq=7654321 的包
第三次握手: 主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码ack 是否为 1,若正确, 主机 A 会再发送 ack number=(主机 B 的 seq+1),ack=1,主机 B 收到后确认
四次挥手(最后一次ack没有的话会怎么样)
端口被占用,主动断开连接的一方需要等待2msl时间才能释放原来使用的端口
三、Spring
IOC和DI的含义,解释:IOC不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
DI即“依赖注入”:是组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”,
AOP的理解 切向编程思想:springAOP是一种的切向编程的思想,通过springAoP实现对软件设计的原则:开闭原则。进而实现对一个类的和一个方法的增强的一种的手段。在传统的架构中都是垂直的流程体系。但是在这个过程中经常产生一些横向问题,比如log日志记录,权限验证,事务处理,性能检查的问题,通过使用的动态代理技术来实现来实现的AOP 的编程思想。
AOP的应用是:log日志记录,权限验证,事务处理,性能检查的问题。AOP在面向过程中产生的一些横向问题,抽象出来就是AOP,主要是是关心逻辑的执行的顺序时间。
事务:ACID 原子性 一致性 隔离性 持久性
事务的隔离级别:读未提交 读读已提交 可重复度 串行化
对象的序列化和反序列化?
序列化:把对象转换成字节序列的过程称为序列化
反序列化:把字节序列恢复成对象的过程称为反序列化
对象的序列化和反序列化主要就是使用ObjectOutputStream 和 ObjectInputStream
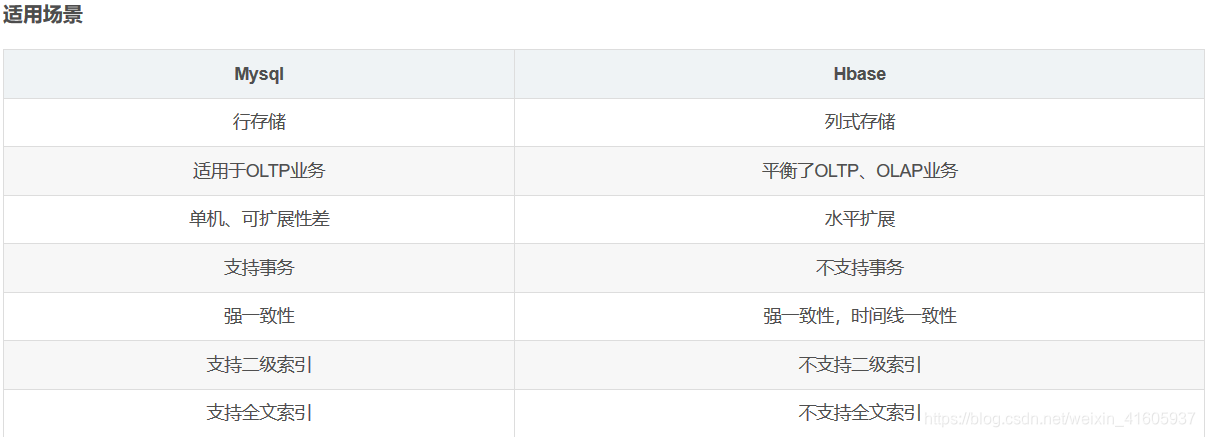
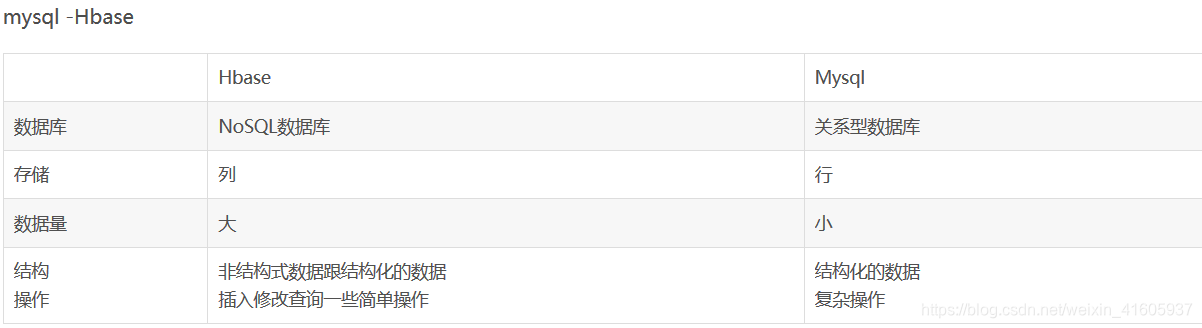
大数据中的Hbase和mysql的区别:
Mysql:关系型数据库,主要面向OLTP,支持事务,支持二级索引,支持sql,支持主从、Group Replication架构模型(此处以Innodb为例,不涉及别的存储引擎)。
b)Hbase:基于HDFS,支持海量数据读写(尤其是写),支持上亿行、上百万列的,面向列的分布式NoSql数据库。天然分布式,主从架构,不支持事务,不支持二级索引,不支持sql。
数据存储方式
a)MySQL采用行存储,MySQL行存储的方式比较适合OLTP业务。
b)HBase是面向列的NoSql数据库,列存储的方式比较适合OLAP业务,而HBase采用了列族的方式平衡了OLTP和OLAP,支持水平扩展,如果数据量比较大、对性能要求没有那么高、并且对事务没有要求的话,HBase也是个不错的选择。
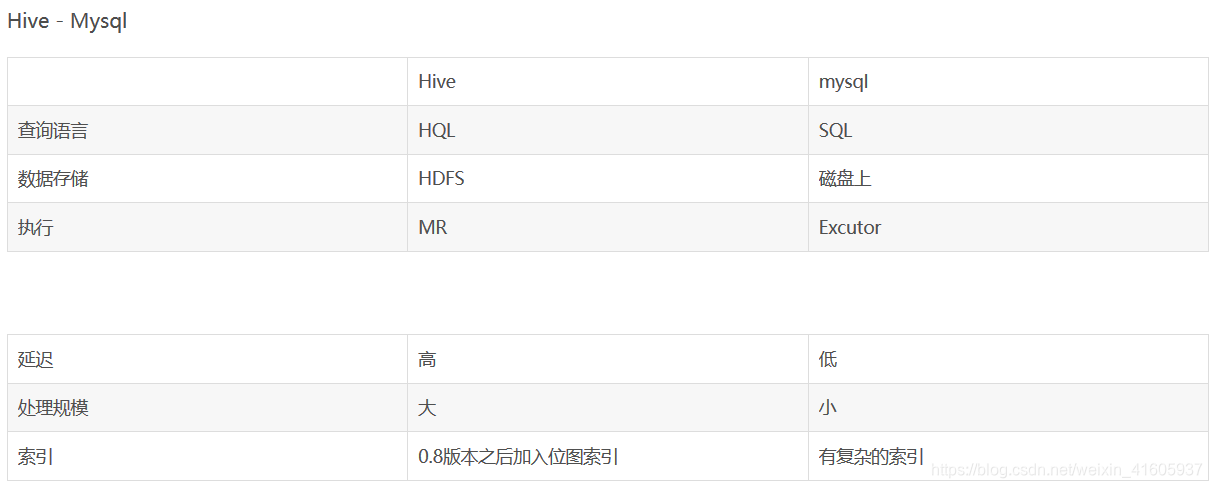
Redis、MySQL、hive、hbase的区别
redis:分布式缓存,强调缓存,基于内存,支持数据持久化,支持事务操作
传统数据库:注重关系,注重事务性
hbase:列式数据库,字典查询,稀疏性存储,无法做关系数据库的主外键,用于存储海量数据,底层基于hdfs
hive:数据仓库工具,底层是mapreduce。不是数据库,不能用来做用户的交互存储
HBase和Redis都是基于Key、Value的数据库。
增、删、改、查、 库、表的概念在hbase 和hive 中 哪些有哪些没有?
虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询–因为它只能够在Haoop上批量的执行Hadoop,Hive中有增、查、库、表的概念。
Hbase的能够在它的数据库上实时运行,Hbase中有增删、改、查、表的概念。
数据库和数据仓库的区别
数据仓库:分析型处理
是为了企业所有级别的决策制定计划过程,提供所有类型数据类型的战略集合。它出于分析性报告和决策支持的目的而创建。
数据仓库是面向主题的;
数据是随着时间的变化而变化的;
数据仓库的数据是不可修改的。 数据仓库的数据主要提供企业决策分析之用,所涉及的数据操作主要是数据查询,一般情况下并不进行修改操作。
属于读模式:在数据查询时会进行检查
hive数据仓库可理解为hdfs的一个数据管理工具
数据库:操作型处理
支持事务性操作,属于写模式,即写入数据时进行检查
它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。
来源:oschina
链接:https://my.oschina.net/u/4368375/blog/4316654