机器学习入门的基础知识,包括常见名词的解释(线性回归、容量、过拟合欠拟合、正则化、超参数和验证集、估计、偏差和方差、最大似然估计、KL散度、随机梯度下降)
欢迎关注我的微信公众号“人小路远”哦,在这里我将会记录自己日常学习的点滴收获与大家分享,以后也可能会定期记录一下自己在外读博的所见所闻,希望大家喜欢,感谢支持!
1、数值计算基础
计算机求解问题的步骤:
1、根据实际问题建立数学模型;(应用数学)
2、由数学模型给出数值计算方法;(计算数学)
3、根据计算方法编制算法程序在计算机上算出结果。
数值问题:是输入和输出数据之间的函数关系的一个确定而无歧义的描述。可以理解为:输入和输出均为数据的数学问题。
上溢:当大量级的数被近似为无穷大时发生上溢。
下溢:当接近零的数被四舍五入为零时发生下溢。
优化:改变x以最小化或最大化某个函数f(x)的任务。
目标函数:需要最小化或最大化的函数。可描述为:
成本(cost)或损失(loss):为了训练模型,我们需要定义一个指标来评估这个模型。但通常定义指标来表示一个模型是坏的,这个指标称为成本(cost)或损失(loss),然后尽量最小化这个指标。
损失函数:一般针对单个样本,可描述为:
代价函数, 一般针对总体,可描述为:
基于梯度的优化方法:延方向导数的方向是上升/下降最快的方向。
驻点:局部最大/最小值点
最值点:全局最大/最小值点
2、机器学习基础
概念:
- 致力于研究如何通过计算的手段,利用经验来改善系统自身性能的学科和方法。
- 对于某类任务T和性能度量P,一个计算机程序被认为可以从经验E中学习是指,通过经验E改进后,它在任务T上由性能度量P衡量的性能有所提升。
任务T:计算机要解决的问题。
学习:获得完成任务能力的过程。
样本:量化特征的数据集合。
分类:预测已知输入的类别。预测为离散值时,此类学习任务成为分类。
回归:预测的为连续值时,此类学习任务称为回归。
聚类:按照潜在标准划分为不同类型组,称为聚类学习。
训练集:训练数据模型的数据集。
测试集:评估模型性能P的数据集。
无监督学习:训练含有很多特征的数据集,然后学习出这个数据集上有用的结构性质。
监督学习:训练含有很多特征的数据集,数据集中的样本都有一个标签。
数据集的表示:通过设计矩阵,行向量表示一个样本,每行中的每列元素表征该样本某个特征数字化的结果。
3、线性回归
定义:利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。描述为:
其中, 为预测y的取值。
机器学习任务:通过样本训练,确定参数 和b
均方误差(mean-square error, MSE):度量模型性能的常用方法,反映估计量与被估计量之间差异程度的一种度量。记为:
正规方程:通过解梯度为0时的向量方程,直接求得驻点位置。
解得: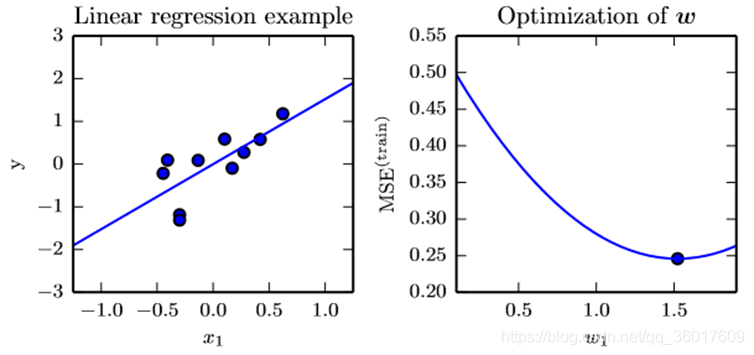
4、容量、过拟合和欠拟合
泛化:训练模型在未观测到的输入上表现良好的能力。
训练误差:模型在训练集上表现出的误差。
泛化误差:新输入数据的误差期望。通常通过在测试集上的性能来评估泛化误差。
决定机器学习算法好坏的两个因素:
-
降低训练误差;
-
缩小训练误差和测试误差的差距。
欠拟合(underfitting):模型不能再训练集上获得足够低的误差;
过拟合(overfitting):训练误差和测试误差的差距太大。
容量(capacity):指模型拟合各种函数的能力。
容量不足的模型不能解决复杂问题;容量高的模型能够解决复杂任务,但当其容量高于任务所需时,有可能会过拟合。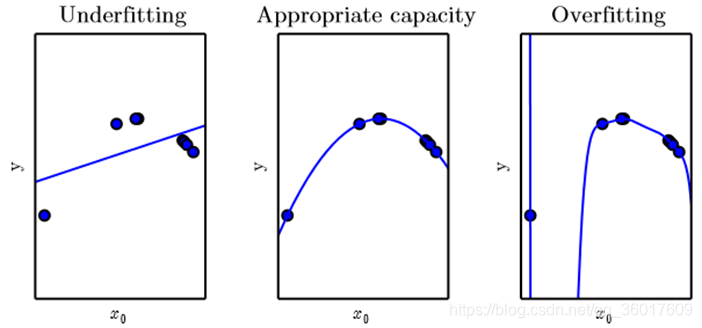
5、正则化
没有免费午餐定理:在所有可能的数据生成分布上平均之后,每一个分类算法在未事先观测的点上都有相同的错误率。
正则化(λ):通过引入权重衰减,来修改训练标准,突出学习算法的偏好。目的是为了降低模型的泛化误差。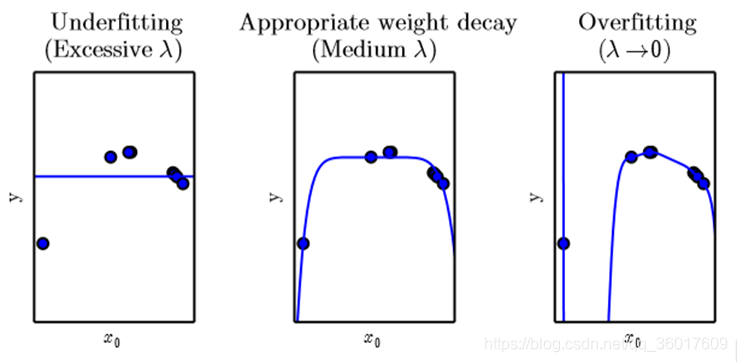
6、超参数和验证集
超参数:指不通过学习学得,而直接设定或指定的参数。适用于控制模型容量的所有参数。这些参数总是趋向于最大可能的模型容量,导致过拟合。
验证集:从训练集中分出,用于调整超参数的数据集。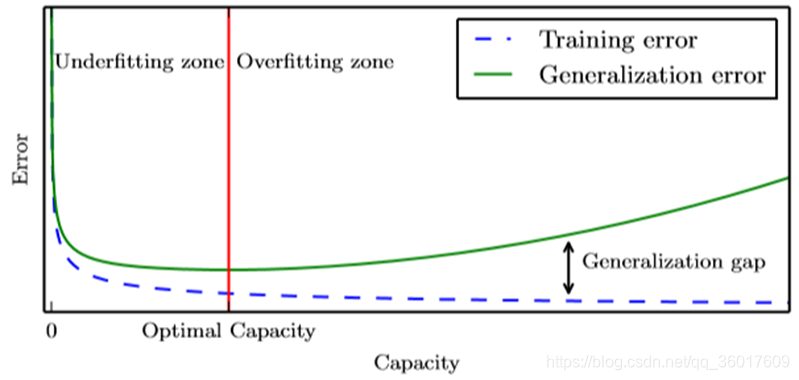
7、估计、偏差和方差
点估计:输入数据样本的函数,估计出的模型中的参数值。记为:
偏差:参数的点估计的数学期望与参数真实值之间的差。记为:
偏差度量偏离真实函数或参数的误差期望;方差度量数据上任意特定采样可能导致的估计期望的偏差。
方差(Variance)
均方误差:权衡偏差和方差的方式实现误差估计。记为: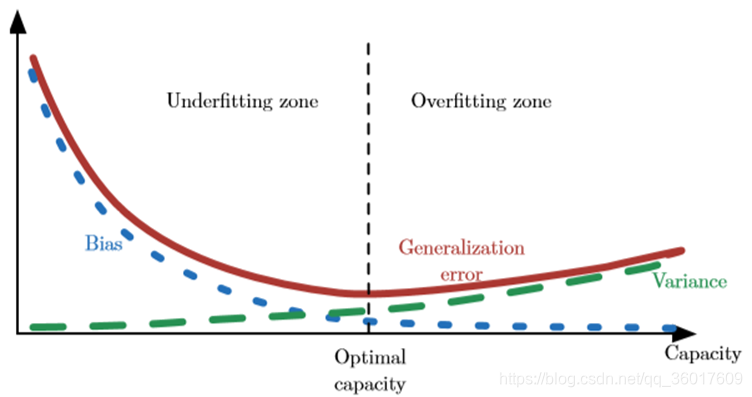
8、最大似然估计
似然函数:给出输出x时,关于θ的似然函数L(x,θ)等于给定参数θ后变量X的概率,即:
最大似然估计:在θ的所有可能取值中,找到一个能使数据出现的“可能性”最大的值。记为:
9、KL散度
KL散度:训练集上的经验分布$ \hat p_{data} $和模型分布之间的差异的度量方式。记为:
最小化散度:最小化分布间的交叉熵。即只用最小化部分:
10、随机梯度下降
问题:梯度下降当样本空间很大时,训练过程消耗过大。
思路:每次训练不必采用全部样本数据,而是均匀抽取一部分样本训练,通过大量的训练步骤,使小批量数据训练的模型拟合全部样本。
解决方法:
-
随机梯度下降(一次选一个样本)
-
批梯度下降(一次选小批量样本)
-
……
来源:CSDN
作者:湖大李桂桂
链接:https://blog.csdn.net/qq_36017609/article/details/104363266