RNN的长期依赖问题
什么是长期依赖?
长期依赖是指当前系统的状态,可能受很长时间之前系统状态的影响,是RNN中无法解决的一个问题。
如果从(1) “ 这块冰糖味道真?”来预测下一个词,是很容易得出“ 甜 ”结果的。但是如果有这么一句话,(2)“ 他吃了一口菜,被辣的流出了眼泪,满脸通红。旁边的人赶紧给他倒了一杯凉水,他咕咚咕咚喝了两口,才逐渐恢复正常。他气愤地说道:这个菜味道真? ”,让你从这句话来预测下一个词,确实很难预测的。因为出现了长期依赖,预测结果要依赖于很长时间之前的信息。
RNN的长期依赖问题
RNN 是包含循环的网络,允许信息的持久化。
预测问题(1): 相关的信息和预测的词位置之间的间隔是非常小时,RNN 可以学会使用先前的信息。
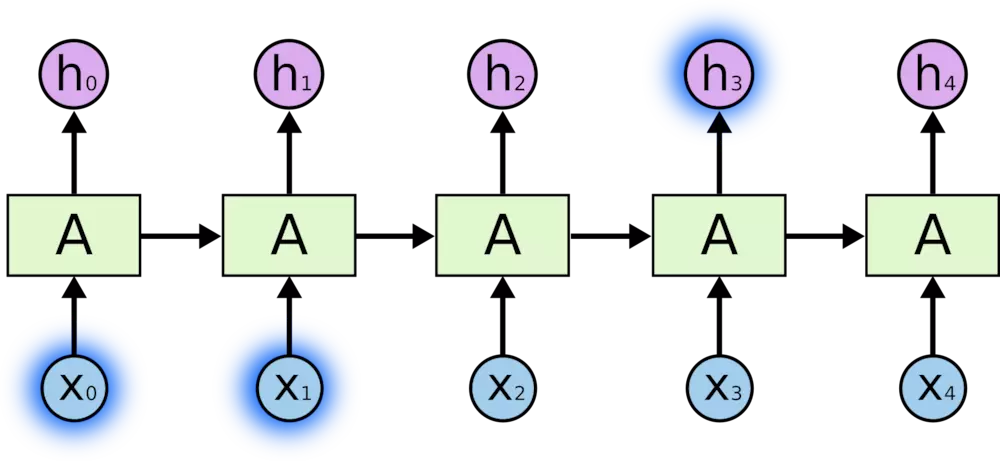
预测问题(2): 在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
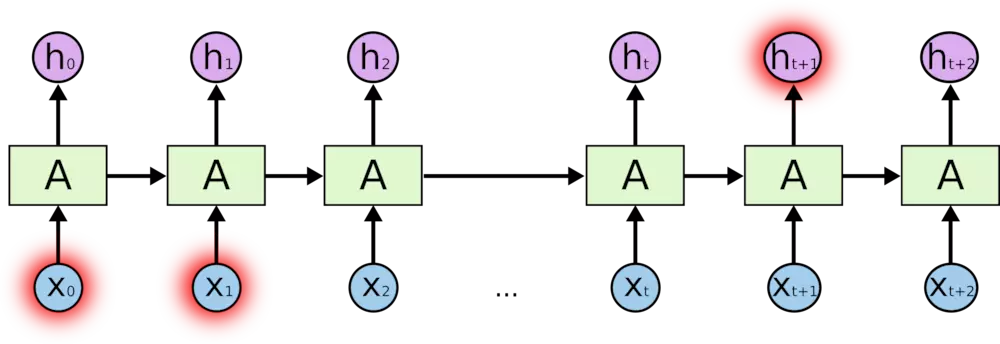
Why?
理论上,通过调整参数,RNN是可以学习到时间久远的信息的。Bengio, et al. (1994)
但是,实践中的结论是,RNN很难学习到这种信息的。 RNN 会丧失学习时间价格较大的信息的能力, 导致长期记忆失效。
RNN中,考虑每个连接的权重,如果abs(W)<1,逐层迭代,将写成含权重的表达式,那么前面的系数会连乘多个权重。当层与层之间距离非常远时,较前层传递到当前层是非常小的一个数,可以认为对几乎不产生影响。也就是较前层的信息几乎被遗忘,就导致了长期记忆失效。
解决长期依赖问题有很多方法的,其中长短期记忆网络(LSTM)是比较常用的一个。
LSTM
LSTM 是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,之后被Alex Graves进行了改良和推广。
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
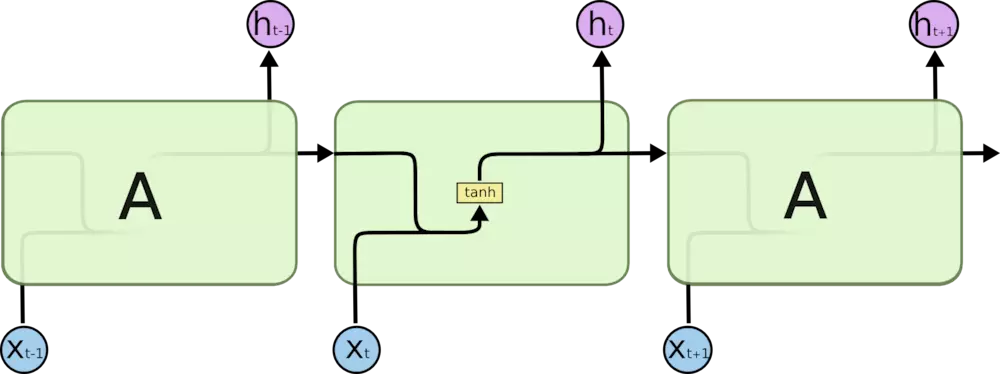
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。包含四个部分,以一种非常特殊的方式进行交互。
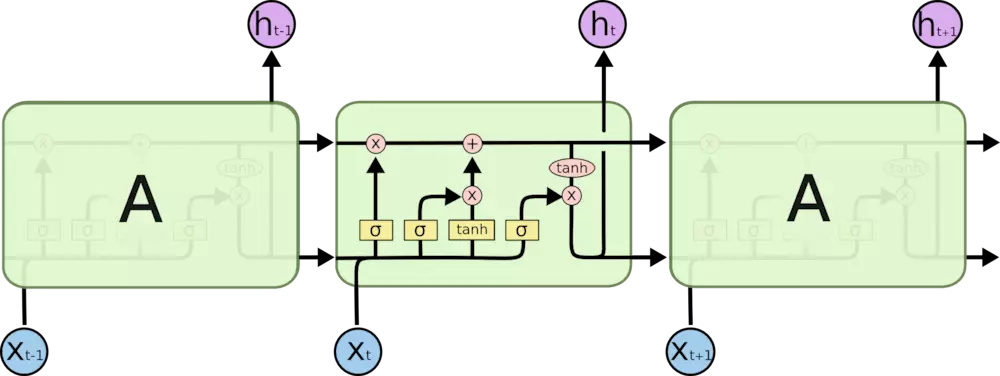
图中的各元素:

每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入;
粉色的圈代表按位 pointwise 的操作,如向量的和;
黄色的矩阵是学习到的神经网络层;
合在一起的线表示向量的连接;
分开的线表示内容被复制,然后分发到不同的位置。
LSTM 的核心思想
LSTM 的关键是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。

LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法,包含一个 sigmoid 神经网络层和一个按位的乘法操作。

Sigmoid 层输出
 到
到  之间的数值,描述每个部分有多少量可以通过。 代表“不许任何量通过”, 就指“允许任意量通过”!
之间的数值,描述每个部分有多少量可以通过。 代表“不许任何量通过”, 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。
逐步理解 LSTM
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取
 和
和  ,输出一个在 到 之间的数值给每个在细胞状态
,输出一个在 到 之间的数值给每个在细胞状态  中的数字。 表示“完全保留”, 表示“完全舍弃”。
中的数字。 表示“完全保留”, 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。

下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,
 ,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。

现在是更新旧细胞状态的时间了,
更新为  。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与
 相乘,丢弃掉我们确定需要丢弃的信息。接着加上
相乘,丢弃掉我们确定需要丢弃的信息。接着加上  。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。

最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在
 到 之间的值)并将它和
到 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。

来源:https://www.cnblogs.com/shona/p/10638320.html