通过前面的实例,可以基本了解MapReduce对于少量输入数据是如何工作的,但是MapReduce主要用于面向大规模数据集的并行计算。所以,还需要重点了解MapReduce的并行编程模型和运行机制。
我们知道,MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。Map和Reduce操作需要我们自己定义相应Map类和Reduce类。而shuffle则是系统自动帮我们实现的,是MapReduce的“心脏”,是奇迹发生的地方。是其主要流程基本如下图所示:
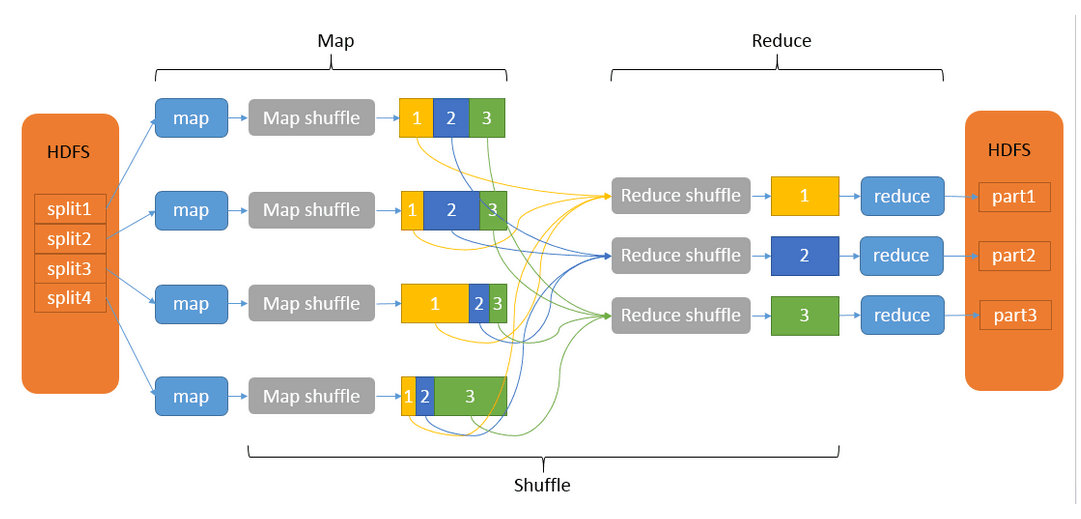
1、数据的输入
首先,对于MapReduce所要处理的数据,应当存储在分布式文件系统(如HDFS)中,通过使用Hadoop资源管理系统YARN,将MapReduce计算转移到存储有部分数据的机器上。
对于输入数据,首先要对其进行输入分片,Hadoop为每个输入分片构建一个map任务,在该任务中调用map函数对分片中的每条数据记录进行处理。处理每个分片的时间小于处理整个数据所花的时间,因此,只要合理分片,整个处理过程就能获得很好的负载均衡。
而关于合理分片,我们不难想到:如果分片数据太大,那么处理所花的时间比较长,整体性能提升不多;反之,如果分片数据切分的太小,那么管理分片的时间和构建map任务的时间又会加大。因此分片要合理,一般情况下,一个合理的分片趋向于一个HDFS块的大小,默认为128M(这也跟map任务的数据本地化有关,当大于一个HDFS块的大小时,就会导致网络传输,降低性能)。
2、Map阶段
Map任务在存储有输入数据的节点上运行,这样可以获得最佳性能,因为无需耗用宝贵的集群带宽,这就是“数据本地化”的优势(主要就是减少了网络传输)。
每个Map任务处理一个输入分片的数据。对于该Map任务所处理的那个分片的数据,通过调用map函数对分片中的每条数据记录进行处理,而Map函数是由用户实现的,因此这里的计算逻辑是用户控制的,但是必须满足输入的是键值对,输出的也是键值对,即完成以下过程:
<k1,v1> ——> list<k2,v2>
这里需要着重理解的是:map任务将其输出写入本地磁盘,而非HDFS。这是因为map的输出只是一个中间结果,一旦整体作业完成就可以删除,因此没有必要在HDFS中进行备份存储,如果在本地磁盘发生丢失,那么只需要在另一个节点上重新执行该map任务即可。
而将Map的输出写入到本地磁盘的整个过程是相当复杂的,这个过程就是在map端的shuffle过程,主要分为以下几步:
(1)map的输出写入环形缓冲区
(2)溢出写:主要包括:分区-->排序(快速排序)-->合并(combiner,如果有的话)--> 溢出写到磁盘
(3)归并:将多个溢出文件归并为一个输出文件
接下来主要介绍这个map端的shuffle过程。
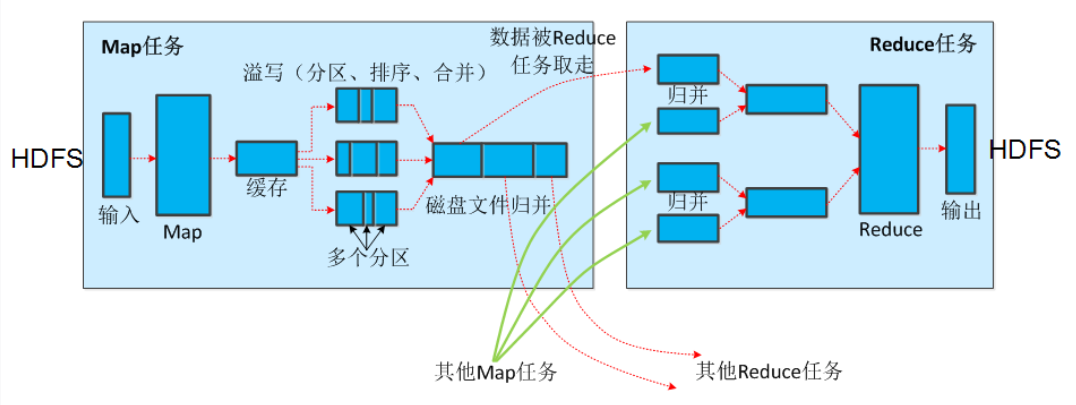
Map函数产生输出时,不是简单的写入到磁盘。首先,每个map任务在内存中都有一个环形缓冲区,一般默认大小为100M。Map开始产生输出后,先将数据存入这个缓冲区,当缓冲区存储内容达到阈值(比如80%)时,启动一个后台线程将内容溢出(spill)到本地磁盘。在溢出写的同时,map继续输出到缓冲区,如果此期间缓冲区填满,则需要阻塞等待写磁盘的过程完成。
而这个后台线程将内容溢出到磁盘的过程也不是直接的简单写,它首先根据这个数据最终要传的reducer把数据分成相应的分区(patition),在每个分区中按照键在内存中对数据进行排序。如果指定了combiner,那么就在排序后得到的输出上运行,使得map的输出更加紧凑,从而减少写到磁盘的数据和传递给reducer的数据。
最后,由于每次缓冲区内容达到阈值,都会产生一个溢出文件,最终在map任务结束时,可能会有多个溢出文件,在结束之前将这些溢出文件进行归并,形成一个输出文件。
理解这个过程后,我们就可以知道:map任务结束后最终写到本地磁盘的是一个已经分区并且已经排序的输出文件。顺便一提,将map的输出写入到磁盘时进行压缩是个好办法,因为减小了写到磁盘的数据和传递给reducer的数据量。
如下的图可以更好的理解这一过程。这里注意合并和归并的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>。
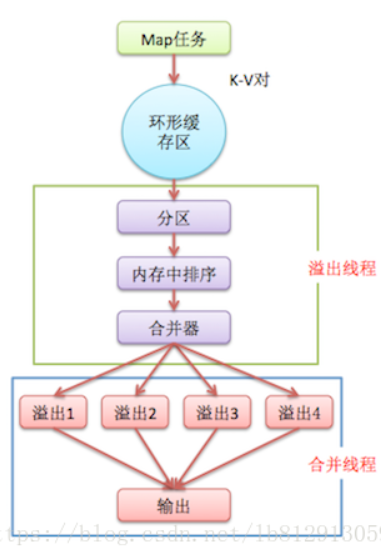
3、Reduce阶段
Reduce任务并不具备数据本地化的优势,单个reduce任务的输入通常情况下是来自于所有Mapper的输出,因此,排过序的map输出需要通过网络传输到运行reduce任务的节点,数据在这里进行归并,然后由用户定义的reduce函数进行处理,最终将得到的输出结果存储在HDFS中,从而完成整个MapReduce作业,即完成以下过程:
<k2,list< v2>> ——> <k3,v3>
这里需要注意的是:Reducer任务的数量并不是由输入数据的大小决定的,而是可以独立指定的,可以在程序中指定reduce任务的数量,可以有1个,可以有多个,甚至没有reduce任务也是可以的。
如果有多个reduce任务,每个map任务就会将自己的输出进行分区(partition),每个renduce任务对应一个分区,每个键对应的所有键值对记录都在同一个分区中(因为同样的key经过同样的哈希函数可以得到相同的结果,就会进入同一个分区)。分区函数通常使用默认的哈希函数。
接下来我们还是重点关注reduce端的shuffle过程,主要分为以下三个过程:
(1)复制(Copy)
(2)归并(Merge)
(3)reduce
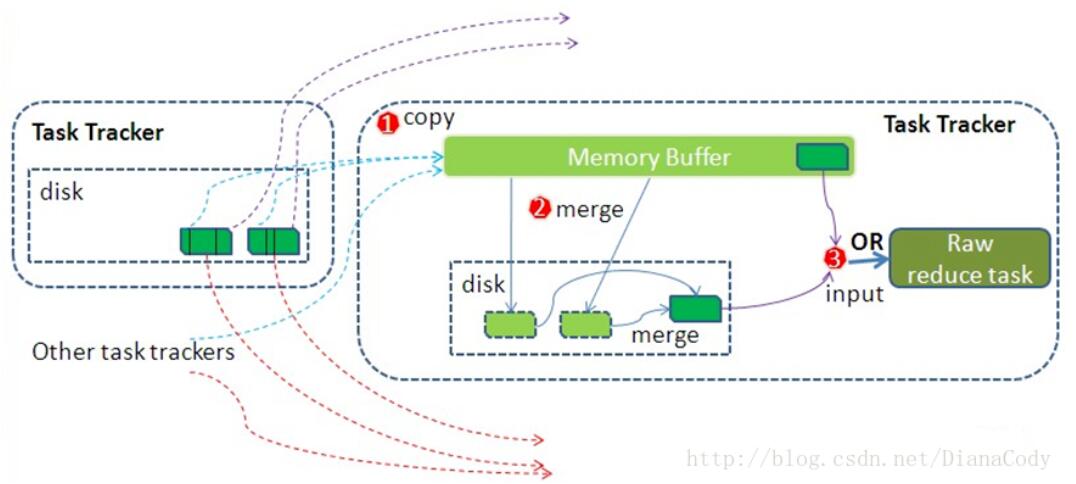
(1)复制(Copy)
首先,在复制阶段,由于map的输出位于运行该任务的节点的本地磁盘上,而reduce任务需要集群上若干个map任务的输出作为其分区文件,每个map任务完成时间可能不同,所以一旦有某个任务完成时,reduce任务就开始复制其输出。reduce任务有少量的复制线程(默认是5个),因此可以并行地复制map的输出。
这里有两个问题可能会有疑问:
1、Reducer如何知道自己应该处理哪些数据呢?
因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition。
2、reducer如何知道要从哪台机器上去取map输出呢?
map任务完成后,它们会使用心跳机制通知它们的application master、因此对于指定作业,application master知道map输出和主机位置之间的映射关系。reducer中的一个线程定期询问master以便获取map输出主机的位置。知道获得所有输出位置。
(2)归并(Merge)
接下来,关于复制过来的数据如何保存也是比较复杂的。如果数据量比较小,则会复制到reduce任务JVM的内存缓冲区中,一旦缓冲区达到阈值,则归并后溢出写到磁盘中,如果指定Combiner,则在归并期间运行它以降低写入硬盘的数据量。随着磁盘上数据的增多,会有一个后台线程将它们归并为更大的、排好序的文件,为后面的归并做准备。
实际上,这已经开始了Merge过程,也就是说复制和归并两个阶段不是完全分开的,是重叠进行的,一边copy一边merge。
当所有map的输出复制完毕后,会进行总的merge(也可以说是排序),这个阶段将所有的map输出进行合并,维持其顺序排序。这个过程是循环进行的,比如有50个map的输出,合并因子为10,那么合并将进行5趟,每趟将10个文件合成一个,最后有5个中间文件。不过作为一个优化,并没有将这5个文件再归并为一个。
所谓最后总的merge,得到的是一个整体并且有序的数据块作为reduce的输入。这里有一个优化措施:默认情况下,reduce从磁盘获得所有的数据,可以通过参数来配置使得buffer中的一部分数据可以直接输送到reduce,从而可以减少了一次磁盘的读写。
总结起来看,整个merge过程实际分为三种类型:内存到内存merge、内存到磁盘merge、磁盘到磁盘merge。如果复制过来的数据量比较小,在内存中可以存放,则会发生内存到内存的merge。当内存缓冲区的数据量达到阈值时,会启动溢出写的过程,这时将内存中的数据归并后写到磁盘,此时发生的就是内存到磁盘的merge。每次触发溢出写都会生成一个磁盘文件,随着磁盘文件的增多,会将多个文件归并为一个文件,这时发生的是磁盘到磁盘的merge。
因此,经过了复制和归并两个阶段后,reduce段的shuffle过程就得到了一个整体按键有序的数据块(即<k2,list< v2>>,注意它可以是来自内存和磁盘片段),这就是reduce函数的输入。
(3)reduce
reduce阶段是最后一个阶段,merge得到的数据直接输入reduce函数,输入是所有的Key和它的Value迭代器,此阶段的输出直接写到输出文件系统,一般为HDFS。如果采用HDFS,由于NodeManager也运行数据节点,所以第一个块副本将被写到本地磁盘。
至此,整个MapReduce的执行过程就结束了,可以发现,整个shuffle过程确实是其核心所在,是工作得以进行的保证,是“奇迹”发生的地方。
【MapReduce整个过程有几次排序?分别发生在什么地方?】
通过对以上编程模型的理解,我们可以总结得出实际上MapReduce有三次排序的过程,第一次发生在map端溢出写之前,后台线程对缓冲区的键值对进行sort,这里用的是快速排序。第二次是发生在map端将磁盘上多个溢出文件归并为一个输出文件时,这是会将key值相同的归并的一起,这用的是归并排序。第三次不难理解,发生在reduce端的merge阶段,对给reduce任务要处理的数据进行归并,这同样是归并排序。因此,实际上,只有第一次可以说是真正的排序,而后两次排序是由归并带来的,说其为归并更加合适。
参考:
作者:ASN_forever
来源:CSDN
原文:https://blog.csdn.net/ASN_forever/article/details/81233547
版权声明:本文为博主原创文章,转载请附上博文链接!
来源:https://www.cnblogs.com/gzshan/p/11161944.html