问题
When I am writing the data of a spark dataframe into SQL DB by using JDBC connector. It is overwritting the properties of the table.
So, i want to set the keyfield in spark dataframe before writing the data.
url = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4};encrypt=true;trustServerCertificate=false; hostNameInCertificate=*.database.windows.net;loginTimeout=30;".format(jdbcHostname, jdbcPort, jdbcDatabase, JDBCusername, JDBCpassword)
newSchema_Product_names = [StructField('product__code',StringType(), False),
StructField('product__names__lang_code',StringType(),False),
StructField('product__names__name',StringType(),True),
StructField('product__country__code',StringType(),True),
StructField('product__country__name',StringType(),True)
]
Product_names1 = sqlContext.createDataFrame(Product_names_new,StructType(newSchema_Product_names))
Product_names1.write.mode("overwrite").jdbc(url, "product_names")
Before:
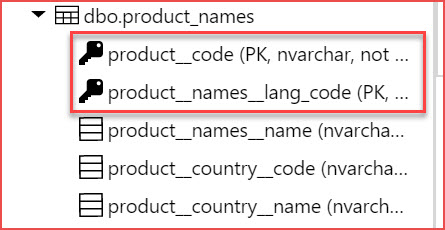
After:
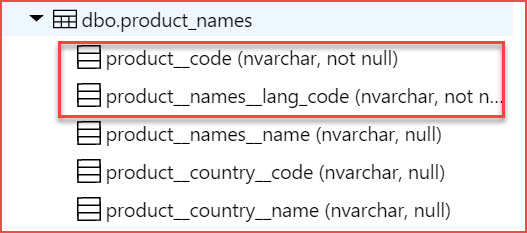
回答1:
@cronoik yes its correct. I thought JDBC connector is not supporting truncate option. But after changing the size of the fields, it worked for me.
来源:https://stackoverflow.com/questions/57238213/how-to-set-an-existing-field-as-a-primary-key-in-spark-dataframe