面向对象编程的三大特性
面向对象的三大特性是指:封装、继承和多态
01对象和类
类(Class) 是现实或思维世界中的实体在计算机中的反映,它将数据以及这些
数据上的操作封装在一起。
对象(Object) 是具有类类型的变量。类和对象是面向对象编程技术中的最基本
的概念。
- 如何定义类?
class 类(): pass - 如何将类转换成对象?
实例化 是指在面向对象的编程中,把用类创建对象的过程称为实例化。是将一个抽象的概
念类,具体到该类实物的过程。实例化过程中一般由类名 对象名 = 类名(参数1,参数2…参数n)构成
类(Class) 是是创建实例的模板
对象(Object) 是一个一个具体的实例
# class 类名称: 定义类的方式
class Person:
# 占位关键字, 什么也不做
pass
print(Person) # <class '__main__.Person'> 存储于当前脚本的Person类
# 对象:将类实例化/具体化产生的值
personObj = Person()
# <__main__.Person object at 0x7f28164b04d0>
# 当前脚本的Person类实例化出来的对象存储的内存地址是0x7f28164b04d0
print(personObj)
Python中自带的类有:
from datetime import datetime
from datetime import date
from collections import defaultdict
02封装特性
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。所以,在使用面向对象的封装特性时,需要:
1). 将内容封装到某处
2). 从某处调用被封装的内容
1). 通过对象直接调用被封装的内容: 对象.属性名
2). 通过self间接调用被封装的内容: self.属性名
3). 通过self间接调用被封装的内容: self.方法名()
构造方法__init__与其他普通方法不同的地方在于,当一个对象被创建后,会立即调
用构造方法。自动执行构造方法里面的内容。
# 构造方法__init__与其他普通方法不同的地方在于,当一个对象被创建后(实例化),会立即调
# 用构造方法。自动执行构造方法里面的内容。
class Student:
# 实例化对象的过程中自动执行的函数
def __init__(self): # self是形参还是实参? - 形参
# self是什么? self实质上实例化出来的对象。系统自动将实例化的对象传递给构造方法。
print("self: ", self)
print("正在运行构造方法........")
print(Student) # <class '__main__.Student'>
# 实例化产生对象的过程
stu1 = Student()
print("stu1: ", stu1)
注意:程序在运行的过程中,遇到class会先执行class中的内容
对于面向对象的封装来说,其实就是使用构造方法将内容封装到对象中,然后通过
对象直接或者self间接获取被封装的内容。
class Student:
def __init__(self, name, score1, score2):
# 将对象和属性封装在一起
self.name = name
self.score1 = score1
self.score2 = score2
# print("self.name: ", self.name)
def compute_sum_score(self):
# 获取封装的属性信息方法一: , 通过self.属性名的方式获取。
return self.score1 + self.score2
stu1 = Student(name="张三", score1=100, score2=100)
# 获取封装的属性信息方法二: , 通过对象名.属性名的方式获取。
print("学生姓名: ", stu1.name)
sum_scores = stu1.compute_sum_score()
print("总分数: ", sum_scores)
封装的案例;
class People(object):
# 创建类的时候类的内容会执行
print('正在创建类。。。')
def __init__(self,name,gender,age):
self.name = name
self.gender = gender
self.age = age
def shopping(self):
print('%s,%d,%s,去西安赛格购物广场' %(self.name,self.age,self.gender))
def playing(self):
print('%s,%d,%s,正在家里玩游戏' %(self.name,self.age,self.gender))
def learning(self):
print('%s,%d,%s,去西部开源学习' %(self.name,self.age,self.gender))
stu1 = People('小名','男',18)
stu2 = People('小王','男',22)
stu3 = People('小红','女',10)
stu1.shopping()
stu2.shopping()
stu3.learning()
03继承特性
继承描述的是事物之间的所属关系,当我们定义一个class的时候,可以从某个现有的class
继承,新的class称为子类、扩展类(Subclass),而被继承的class称为基类、父类或超类
(Baseclass、Superclass)。
问题一: 如何让实现继承?
子类在继承的时候,在定义类时,小括号()中为父类的名字
问题二: 继承的工作机制是什么?
父类的属性、方法,会被继承给子类。 举例如下: 如果子类没有定义__init__方法,父类有,
那么在子类继承父类的时候这个方法就被继承了,所以只要创建对象,就默认执行了那个继承过来的__init__方法。
# 在Python代码中,没有指定父类,默认继承object类
# 父类;object 子类:Student
class Student(object):
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def learn(self):
print('%s正在学习编程。。。。。' %(self.name))
class MathStudent(Student):
# 重写父类learn方法
# 重写父类learn方法:就是子类中,有一个和父类相同名字的方法,在子类中的方法会覆盖掉父类中同名的方法
def learn(self):
# Student.learn(self)
super(MathStudent,self).learn() # 调用父类的方法
print('%s正在学习英语六级。。。' %(self.name))
class EnglishStudent(Student):
pass
s1 = Student('粉条',10,'male')
print(s1.name)
s2 = MathStudent('芬必得',100,'male')
# 当实例化对象,子类中没有构造方法,将自动调用并执行父类的构造方法
s2.learn()
# 当子类调用的方法没有的时候,自动去父类里面寻找并执行
s3 = EnglishStudent('奥巴马',60,'female')
s3.learn()
重写父类方法: 就是子类中,有一个和父类相同名字的方法,在子类中的方法
会覆盖掉父类中同名的方法。
调用父类的方法:
- 父类名.父类的方法名()
- super(): py2.2+的功能
# 私有属性和私有方法:
class Student(object):
"""
需求: 学生成绩保密, 外部不可以访问分数, 只可以访问分数的等级
"""
def __init__(self, name, age, score):
self.name = name
self.age = age
# self.__score是私有属性, 只能在类的内部访问, 类的外部不可以访问。
self.__score = score
# __get_level是私有方法,只能在类的内部访问, 类的外部不可以访问。
def __get_level(self):
if 90 <= self.__score <= 100:
return "优秀"
elif 80 <= self.__score < 90:
return "良好"
elif 60 <= self.__score < 80:
return "及格"
else:
return "不及格"
stu1 = Student("粉条", 10, 59)
# print(stu1.__score) # 调用私有属性失败
# print("学生分数的等级: ", stu1.__get_level()) # 调用私有方法失败
# Python解释器自动将私有属性和私有方法重命名了, 命名方式一般是_类名__属性名、_类名__方法名
print(stu1._Student__score)
print(stu1._Student__get_level())
多继承,即子类有多个父类,并且具有它们的特征
class TeacherMajor(object):
def __init__(self, students_count):
self.student_count = students_count
class DoctorMajor(object):
def __init__(self, patients_count):
self.patients_count = patients_count
# 子类Student拥有2个父类TeacherMajor和DoctorMajor
class Student(TeacherMajor, DoctorMajor):
def __init__(self, name, students_count, patients_count):
self.name = name
TeacherMajor.__init__(self, students_count)
DoctorMajor.__init__(self, patients_count)
# # 继承的顺序如何查看?
# print(Student.__mro__)
stu1 = Student("粉条", 0, 0)
print(stu1.patients_count)
print(stu1.student_count)
在Python 2及以前的版本中,由任意内置类型派生出的类,都属于“新式
类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,
则称之为“经典类”。
新式类: 经典类
class 类名(object): class 类名:
pass pass
“新式类”和“经典类”的区分在Python 3之后就已经不存在,在Python3.x之后的版本,因为所有的类都派生自内置类型object(即使没有显示的继承object类型),即所有的类都是“新式类”。
最明显的区别在于继承搜索的顺序不同,即:
经典类多继承搜索顺序(深度优先算法):先深入继承树左侧查找,然后再返回,开始查找右侧。
新式类多继承搜索顺序(广度优先算法):先在水平方向查找,然后再向上查找,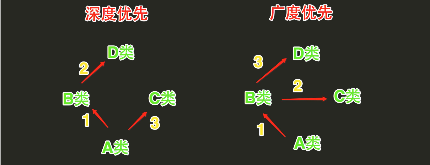
#coding:utf-8
# 注意: Python2环境中做实验
# 类D经典类.
class D:
def hello(self):
print("D...... hello")
class C(D):
def hello(self):
print("C...... hello")
class B(D):
pass
class A(B, C):
pass
# 经典类多继承搜索顺序(深度优先算法):先深入继承树左侧查找,然后再返回,开始查找右侧。
a = A()
a.hello()
# D...... hello
class D(object):
def hello(self):
print("D...... hello")
class C(D):
def hello(self):
print("C...... hello")
class B(D):
pass
class A(B, C):
pass
# 新式类多继承搜索顺序(广度优先算法):先在水平方向查找,然后再向上查找,
a = A()
a.hello()
# C...... hello
默认情况下,属性在 Python 中都是“public”, 大多数 OO 语言提供“访问控制符”来限定成员函数的访问。
在 Python 中,实例的变量名如果以 __ 开头,就变成了一个私有变量/属性(private),实例的函数名如果以 __ 开头,就变成了一个私有函数/方法(private)只有内部可以访问,外部不能访问。
问题: 私有属性一定不能从外部访问吗?
python2版本不能直接访问了__属性名,所以,是因为 Python 解释器对外把__属性名改成了_类名__属性名 。所以,仍然可以通过_类名__属性名来访问__属性名
因为不同版本的 Python 解释器可能会把 __ 属性名 改成不同的变量名。
私有属性私有方法的优势:
- 确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加壮。
- 如果又要允许外部代码修改属性怎么办?可以给类增加专门设置属性方法。 为什么大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数。
# 私有属性和私有方法:
class Student(object):
"""
需求: 学生成绩保密, 外部不可以访问分数, 只可以访问分数的等级
"""
def __init__(self, name, age, score):
self.name = name
self.age = age
# self.__score是私有属性, 只能在类的内部访问, 类的外部不可以访问。
self.__score = score
# __get_level是私有方法,只能在类的内部访问, 类的外部不可以访问。
def __get_level(self):
if 90 <= self.__score <= 100:
return "优秀"
elif 80 <= self.__score < 90:
return "良好"
elif 60 <= self.__score < 80:
return "及格"
else:
return "不及格"
stu1 = Student("粉条", 10, 59)
# print(stu1.__score) # 调用私有属性失败
# print("学生分数的等级: ", stu1.__get_level()) # 调用私有方法失败
# Python解释器自动将私有属性和私有方法重命名了, 命名方式一般是_类名__属性名、_类名__方法名
print(stu1._Student__score)
print(stu1._Student__get_level())
04 多态特性
多态(Polymorphism)按字面的意思就是“多种状态”。在面向对象语言中,接口
的多种不同的实现方式即为多态。通俗来说: 同一操作作用于不同的对象,可以有不
同的解释,产生不同的执行结果。
多态的好处就是,当我们需要传入更多的子类,只需要继承父类就可以了,而方法既可以直
接不重写(即使用父类的),也可以重写一个特有的。这就是多态的意思。调用方只管调用,不
管细节,而当我们新增一种的子类时,只要确保新方法编写正确,而不用管原来的代码。这就是
著名的“开闭”原则:
对扩展开放(Open for extension):允许子类重写方法函数
对修改封闭(Closed for modification):不重写,直接继承父类方法函数
案例1 栈的封装
根据列表的数据结构封装栈的数据结构
属性: 栈元素stack
方法:
get_top()
get_bootom()
push()
pop()
class Stack(object):
def __init__(self):
self.stack = [] # [1, 2, 3]
def top(self):
return self.stack[-1]
def bootom(self):
return self.stack[0]
def push(self, item):
"""
:param item: 入栈元素
:return:
"""
self.stack.append(item)
return True
def pop(self):
item = self.stack.pop()
return item
def show(self):
return self.stack
# 魔术方法, 使得代码运行更加简洁
def __len__(self):
return len(self.stack)
if __name__ == '__main__':
stack = Stack()
print(stack.show())
# print(stack.top())
# stack.push(1)
# stack.push(2)
# stack.push(3)
# print("入栈后: ", stack.show())
# item = stack.pop()
# print("出栈元素为: ", item)
# print("出栈后: ", stack.show())
# print('栈元素个数: ', stack.__len__())
print('栈元素个数: ', len(stack))
案例二:二叉树节点的封装
class Node(object):
def __init__(self,data,lchild=None,rchild=None):
self.data = data
self.lchild = lchild
self.rchild = rchild
#魔术方法:len() __len__ str() __str__
def __str__(self): # 友好的字符串显示信息
return 'Node<%s>' %(self.data)
def pre_view( root):
"""
先序遍历: 根节点-左子树节点-右子树节点
传递根节点
:param root:
:return:
"""
if root == None:
return
print(root.data)
pre_view(root.lchild)
pre_view(root.rchild)
def last_view(root):
"""
后序遍历: -左子树节点-右子树节点-根节点
传递根节点
:param root:
:return:
"""
if root == None:
return
last_view(root.lchild)
last_view(root.rchild)
print(root.data)
def mid_view(root):
"""
中序遍历: -左子树节点--根节点-右子树节点
传递根节点
:param root:
:return:
"""
if root == None:
return
mid_view(root.lchild)
print(root.data)
mid_view(root.rchild)
if __name__ == '__main__':
D = Node('D')
B = Node('B', D)
C = Node('C')
A = Node('A', B, C)
# print("A-left: ", str(A.lchild))
# print("A-right: ", str(A.rchild))
# 先序遍历(根左右)、中序遍历(左根右)、后序遍历(左右根)
print("先序遍历:")
pre_view(A)
print("后序遍历:")
last_view(A)
print("中序遍历:")
mid_view(A)
来源:CSDN
作者:C_teacher
链接:https://blog.csdn.net/C_teacher/article/details/103819813