这篇文章,引领了对抗学习的思想,更加可贵的是其中的理论证明,证明很少却直击要害.
目标
GAN,译名生成对抗网络,目的就是训练一个网络来拟合数据的分布,以前的方法,类似高斯核,Parzen窗等都可以用来估计(虽然不是很熟).
GAN有俩个网络,一个是G(z)生成网络,和D(x)判别网络, 其中\(z\)服从一个随机分布,而\(x\)是原始数据, \(z\)服从一个随机分布,是很重要的一点,假设\(\hat{x}=G(x)\), 则:
\[
p(\hat{x})=\int p(z)I(G(z)=\hat{x})\mathrm{d}z
\]
其中\(I\)表示指示函数,这意味着,网络\(G\)也是一个分布,而我们所希望的,就是这个分布能够尽可能取拟合原始数据\(x\)的分布.
框架
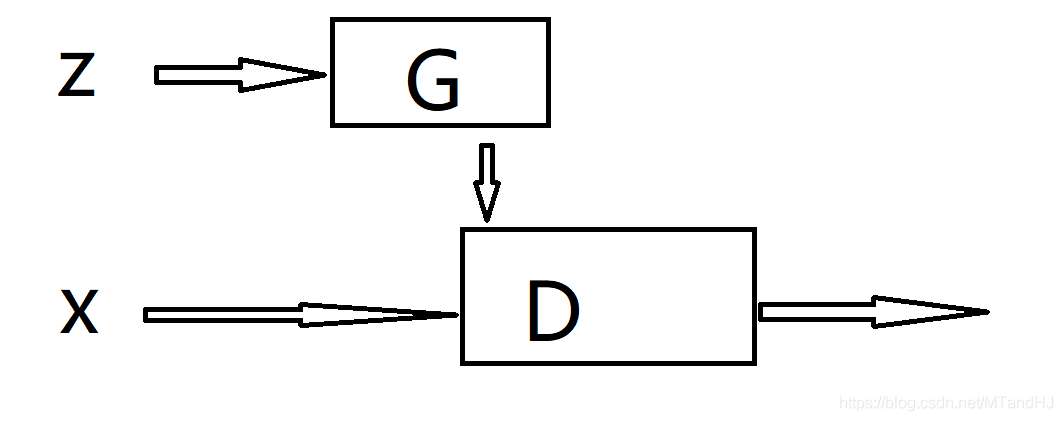
GAN需要训练上面的俩个网络,D的输出是一个0~1的标量,其含义是输入的x是否为真实数据(真实为1), 故其损失函数为(V(D,G)部分):
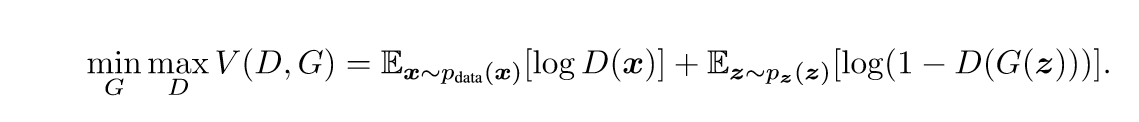
在实际操作中,固定网络G更新网络D,再固定网络D更新网络G,反复迭代:
理论
至于为什么可以这么做,作者给出了精炼的证明.


上面的证明唯一令人困惑的点在于\(p_z \rightarrow p_g\)的变化,我一开始觉得这个是利用换元,但是从别的博客中看到,似乎是用了测度论的导数的知识,最后用到了变分的知识.

其中: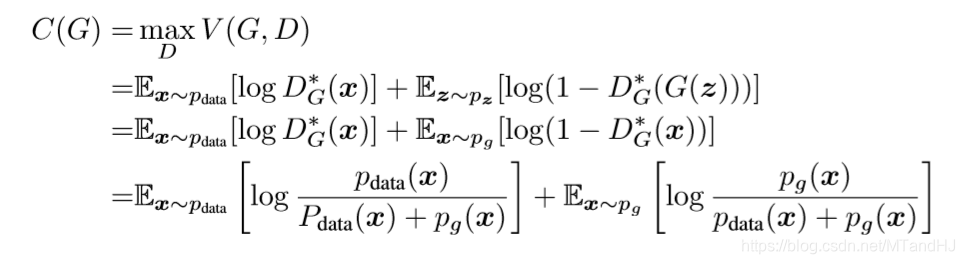
其证明思路是,当\(p_g=p_{data}\)的时候,\(C(G)=-\log 4\), 所以只需证明这个值为最小值,且仅再\(p_g=p_{data}\)的时候成立那么证明就结束了,为了证明这一点,作者凑了一个JSD, 而其正好满足我们要求(实际上只需KL散度即可Gibb不等式).
数值实验
在MNIST数据集上做实验(代码是仿别人的写的), 我们的目标自然是给一个z, G能够给出一些数字.
用不带卷积层的网络:
带卷积层的网络,不过不论\(z\)怎么变,结果都一样,感觉有点怪,但是实际上,如果\(G\)一直生成的都是比方说是1, 那也的确能够骗过\(D\), 这个问题算是什么呢?有悖啊...
代码
代码需要注意的一点是,用BCELoss, 但是更新G网络的时候,并不是传入fake_label, 而是real_label,因为G需要骗过D, 不知道该怎么说,应该明白的.
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class Generator(nn.Module):
def __init__(self, input_size):
super(Generator, self).__init__()
self.dense = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 784)
)
def forward(self, x):
out = self.dense(x)
return out
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.dense = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), -1)
out = self.dense(x)
return out
class Train:
def __init__(self, trainset, batch_size, z_size=100, criterion=nn.BCELoss(), lr=1e-3):
self.generator = Generator(z_size)
self.discriminator = Discriminator()
self.opt1 = torch.optim.SGD(self.generator.parameters(), lr=lr, momentum=0.9)
self.opt2 = torch.optim.SGD(self.discriminator.parameters(), lr=lr, momentum=0.9)
self.trainset = trainset
self.batch_size = batch_size
self.real_label = torch.ones(batch_size)
self.fake_label = torch.zeros(batch_size)
self.criterion = criterion
self.z_size = z_size
def train(self, epoch_size, path):
running_loss1 = 0.0
running_loss2 = 0.0
for epoch in range(epoch_size):
for i, data in enumerate(self.trainset, 0):
try:
real_img, _ = data
out1 = self.discriminator(real_img)
real_loss = self.criterion(out1, self.real_label)
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.fake_label)
loss = real_loss + fake_loss
self.opt2.zero_grad()
loss.backward()
self.opt2.step()
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.real_label) #real_label!!!!
self.opt1.zero_grad()
fake_loss.backward()
self.opt1.step()
running_loss1 += fake_loss
running_loss2 += real_loss
if i % 10 == 9:
print("[epoch:{} loss1: {:.7f} loss2: {:.7f}]".format(
epoch,
running_loss1 / 10,
running_loss2 / 10
))
running_loss1 = 0.0
running_loss2 = 0.0
except ValueError as err:
print(err) #最后一批的数据可能不是batch_size
continue
torch.save(self.generator.state_dict(), path)
def loading(self, path):
self.generator.load_state_dict(torch.load(path))
self.generator.eval()
"""
加了点卷积
"""
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
class Generator(nn.Module):
def __init__(self, input_size):
super(Generator, self).__init__()
self.dense = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 784)
)
def forward(self, x):
out = self.dense(x)
return out
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5, 3, 2), # 1x28x28 --> 32x10x10
nn.ReLU(),
nn.MaxPool2d(2, 2), # 32 x 10 x 10 --> 32x5x5
nn.Conv2d(32, 64, 3, 1, 1), # 32x5x5-->32x5x5
nn.ReLU()
)
self.dense = nn.Sequential(
nn.Linear(1600, 512),
nn.ReLU(),
nn.Linear(512, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), 1, 28, 28)
x = self.conv(x)
x = x.view(x.size(0), -1)
out = self.dense(x)
return out
class Train:
def __init__(self, trainset, batch_size, z_size=100, criterion=nn.BCELoss(), lr=1e-3):
self.generator = Generator(z_size)
self.discriminator = Discriminator()
self.opt1 = torch.optim.SGD(self.generator.parameters(), lr=lr, momentum=0.9)
self.opt2 = torch.optim.SGD(self.discriminator.parameters(), lr=lr, momentum=0.9)
self.trainset = trainset
self.batch_size = batch_size
self.real_label = torch.ones(batch_size)
self.fake_label = torch.zeros(batch_size)
self.criterion = criterion
self.z_size = z_size
def train(self, epoch_size, path):
running_loss1 = 0.0
running_loss2 = 0.0
for epoch in range(epoch_size):
for i, data in enumerate(self.trainset, 0):
try:
real_img, _ = data
out1 = self.discriminator(real_img)
real_loss = self.criterion(out1, self.real_label)
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.fake_label)
loss = real_loss + fake_loss
self.opt2.zero_grad()
loss.backward()
self.opt2.step()
z = torch.randn(self.batch_size, self.z_size)
fake_img = self.generator(z)
out2 = self.discriminator(fake_img)
fake_loss = self.criterion(out2, self.real_label) #real_label!!!!
self.opt1.zero_grad()
fake_loss.backward()
self.opt1.step()
running_loss1 += fake_loss
running_loss2 += real_loss
if i % 10 == 9:
print("[epoch:{} loss1: {:.7f} loss2: {:.7f}]".format(
epoch,
running_loss1 / 10,
running_loss2 / 10
))
running_loss1 = 0.0
running_loss2 = 0.0
except ValueError as err:
print(err) #最后一批的数据可能不是batch_size
continue
torch.save(self.generator.state_dict(), path)
def loading(self, path):
self.generator.load_state_dict(torch.load(path))
self.generator.eval()
来源:https://www.cnblogs.com/MTandHJ/p/11332262.html