一、内存数据库:
在SQLite中,数据库通常是存储在磁盘文件中的。然而在有些情况下,我们可以让数据库始终驻留在内存中。最常用的一种方式是在调用sqlite3_open()的时候,数据库文件名参数传递":memory:",如:
rc = sqlite3_open(":memory:", &db);
在调用完以上函数后,不会有任何磁盘文件被生成,取而代之的是,一个新的数据库在纯内存中被成功创建了。由于没有持久化,该数据库在当前数据库连接被关闭后就会立刻消失。需要注意的是,尽管多个数据库连接都可以通过上面的方法创建内存数据库,然而它们却是不同的数据库,相互之间没有任何关系。事实上,我们也可以通过Attach命令将内存数据库像其他普通数据库一样,附加到当前的连接中,如:
ATTACH DATABASE ':memory:' AS aux1;
二、临时数据库:
在调用sqlite3_open()函数或执行ATTACH命令时,如果数据库文件参数传的是空字符串,那么一个新的临时文件将被创建作为临时数据库的底层文件,如:
rc = sqlite3_open("", &db);
或
ATTACH DATABASE '' AS aux2;
和内存数据库非常相似,两个数据库连接创建的临时数据库也是各自独立的,在连接关闭后,临时数据库将自动消失,其底层文件也将被自动删除。
尽管磁盘文件被创建用于存储临时数据库中的数据信息,但是实际上临时数据库也会和内存数据库一样通常驻留在内存中,唯一不同的是,当临时数据库中数据量过大时,SQLite为了保证有更多的内存可用于其它操作,因此会将临时数据库中的部分数据写到磁盘文件中,而内存数据库则始终会将数据存放在内存中。
由于sqlite对多进程操作支持效果不太理想,在项目中,为了避免频繁读写 文件数据库带来的性能损耗,我们可以采用操作sqlite内存数据库,并将内存数据库定时同步到文件数据库中的方法。
实现思路如下:
1、创建文件数据库;
2、创建内存数据库(文件数据库、内存数据库的内部表结构需要一致);
3、在内存数据库中attach文件数据库,这样可以保证文件数据库中的内容在内存数据库中可见;
4、对于insert、select操作,在内存数据库中完成,对于delete、update操作,需要同时访问内存、文件数据库;
5、定时将内存数据库中的内容flush到文件数据库。
sqlite分两种源码结构,一种是比较常见的sqlite3.c 一个文件十几万行代码。另一种是,将各个模块分离出的源码结构。
一、主要分为三部分:
虚拟机(Virtual Machine)
Back-end(后端)
compiler(编译器)
1、虚拟机(Virtual Machine)
2、B-tree和Pager
B-Tree使得VDBE可以在O(logN)下查询,插入和删除数据,以及O(1)下双向遍历结果集。B-Tree不会直接读写磁盘,它仅仅维护着页面(pager)之间的关系。当B-Tree需要页面或者修改页面时,它就会调用Pager。当修改页面时,pager保证原始页面首先写入日志文件,当它完成写操作时,pager根据事务状态决定如何做。B-tree不直接读写文件,而是通过page cache这个缓冲模块读写文件,对于性能是有重要意义的(这和操作系统读写文件类似,在Linux中,操作系统的上层模块并不直接调用设备驱动读写设备,而是通过一个高速缓冲模块调用设备驱动读写文件,并将结果存到高速缓冲区)。
3、编译器(Compiler)
3.1、分词器(Tokenizer)
Tokenizer.c
3.2、分析器(Parser)
SQLite的语法分析器是用Lemon(一个开源的LALR(1)语法分析器的生成器)生成的,生成的文件为parser.c。
3.3、代码生成器(Code Generator)
代码生成器是SQLite中最庞大,最复杂的部分。它与Parser关系紧密,根据语法分析树生成VDBE程序执行SQL语句的功能。
由诸多文件构成:select.c,update.c,insert.c,delete.c,trigger.c,where.c等文件。
这些文件生成相应的VDBE程序指令,比如SELECT语句就由select.c生成。
3.4、查询优化
代码生成器不仅负责生成代码,也负责进行查询优化。
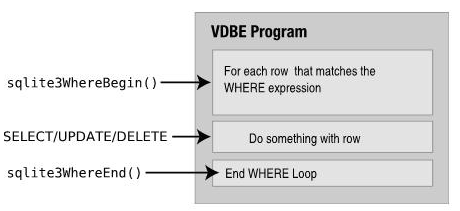
主要的实现位于where.c中,生成的WHERE语句块通常被其它模块共享,比如select.c,update.c以及delete.c。
这些模块调用sqlite3WhereBegin()开始WHERE语句块的指令生成,然后加入它们自己的VDBE代码返回,最后调用sqlite3WhereEnd()结束指令生成。
B树:https://www.cnblogs.com/dongguacai/p/7239599.html
相同数量的key在B树中生成的节点要远远少于二叉树中的节点,相差的节点数量就等同于磁盘IO的次数。这样到达一定数量后,性能的差异就显现出来了。
插入或者删除元素都会导致节点发生裂变反应,有时候会非常麻烦,但正因为如此才让B树能够始终保持多路平衡,这也是B树自身的一个优势:自平衡;
B树主要应用于文件系统以及部分数据库索引,如MongoDB,大部分关系型数据库索引则是使用B+树实现。
sqlite中的锁
就数据库而言,处理的并发实际上分为读并发,写并发,读写并发,我们广义上说的并发实际上指的是读写并发,要了解这些,我们还需要先了解一下sqlite中的锁.
sqlite中一共有五种锁分别是
未加锁(UNLOCKED)
文件没有持有任何锁,即当前数据库不存在任何读或写的操作。其它的进程可以在该数据库上执行任意的读写操作。此状态为缺省状态。
共享锁(SHARED)
在此状态下,该数据库可以被读取但是不能被写入。在同一时刻可以有任意数量的进程在同一个数据库上持有共享锁,因此读操作是并发的。换句话说,只要有一个或多个共享锁处于活动状态,就不再允许有数据库文件写入的操作存在。
保留锁(RESERVED)
假如某个进程在将来的某一时刻打算在当前的数据库中执行写操作,然而此时只是从数据库中读取数据,那么我们就可以简单的理解为数据库文件此时已经拥有了保留锁。当保留锁处于活动状态时,该数据库只能有一个或多个共享锁存在,即同一数据库的同一时刻只能存在一个保留锁和多个共享锁. 需要说明的是update操作 实际上是一个读操作加一个写操作
未决锁(PENDING)
PENDING锁的意思是说,某个进程正打算在该数据库上执行写操作,然而此时该数据库中却存在很多共享锁(读操作),那么该写操作就必须处于等待状态,即等待所有共享锁消失为止,与此同时,新的读操作将不再被允许,以防止写锁饥饿的现象发生。在此等待期间,该数据库文件的锁状态为PENDING,在等到所有共享锁消失以后,PENDING锁状态的数据库文件将在获取排他锁之后进入EXCLUSIVE状态。
排它锁(EXCLUSIVE)
在执行写操作之前,该进程必须先获取该数据库的排他锁。然而一旦拥有了排他锁,任何其它锁类型都不能与之共存。因此,为了最大化并发效率,SQLite将会最小化排他锁被持有的时间总量。
读操作锁变化
了解了sqlite的锁之后 我们再来看针对读写操作,sqlite内部的锁变化

读操作的目的是获取共享锁shared从而来访问数据 那么 在获得共享锁(SHARED)之前
首先检查是否有排它锁(EXCLUSIVE) 如果有 则说明sqlite正在进行写入操作 为保障数据一致 所以无法获取共享锁(SHARED)
如果没有 再检查是否有未决锁(PENDING)如果有 表示当前有准备进行的写操作并阻止共享锁(SHARED)的获取
如果检测不到上述两个锁 将获得共享锁(SHARED) 读取数据 然后释放共享锁
写操作锁变化
对于写操作,写操作的目的是为了获得 排它锁(EXCLUSIVE) 独占数据库从而一致性,其内部锁变化如下

首先 检查数据库是否有保留锁(RESERVED)与排它锁(EXCLUSIVE) 如果有 则说明在此次写操作之前还准备有或者正在进行一次写操作
此时如法获取排它锁(EXCLUSIVE) 如果没有 则获取未决锁(PENDING) 当未决锁(PENDING)获得时,将无法再获取到共享锁(SHARED),也就是说sqlite此时已经不再处理读请求
在持有未决锁(PENDING)期间 将会不断询问内部是否还有共享锁(SHARED) 当等待所有共享锁(SHARED)消失 当所有共享锁(SHARED)消失时 此时锁状态将由未决锁(PENDING)切换至排它锁(EXCLUSIVE) 并写入数据 当排它锁(EXCLUSIVE)激活时 阻止任何类型的其它锁获取 直至写入完毕并释放排它锁(EXCLUSIVE)
总结
最后我们来总结一下
1.当有写操作时,其他读操作会被驳回 2.当有写操作时,其他写操作会被驳回 3.当开启事务时,在提交事务之前,其他写操作会被驳回 4.当开启事务时,在提交事务之前,其他事务请求会被驳回 5.当有读操作时,其他写操作会被驳回 6.读操作之间能够并发执行
--------------------- 本文来自 https://blog.csdn.net/zhangsheng_1992/article/details/52598396?utm_source=copy
一、内存数据库:
在SQLite中,数据库通常是存储在磁盘文件中的。然而在有些情况下,我们可以让数据库始终驻留在内存中。最常用的一种方式是在调用sqlite3_open()的时候,数据库文件名参数传递":memory:",如:
rc = sqlite3_open(":memory:", &db);
在调用完以上函数后,不会有任何磁盘文件被生成,取而代之的是,一个新的数据库在纯内存中被成功创建了。由于没有持久化,该数据库在当前数据库连接被关闭后就会立刻消失。需要注意的是,尽管多个数据库连接都可以通过上面的方法创建内存数据库,然而它们却是不同的数据库,相互之间没有任何关系。事实上,我们也可以通过Attach命令将内存数据库像其他普通数据库一样,附加到当前的连接中,如:
ATTACH DATABASE ':memory:' AS aux1;
二、临时数据库:
在调用sqlite3_open()函数或执行ATTACH命令时,如果数据库文件参数传的是空字符串,那么一个新的临时文件将被创建作为临时数据库的底层文件,如:
rc = sqlite3_open("", &db);
或
ATTACH DATABASE '' AS aux2;
和内存数据库非常相似,两个数据库连接创建的临时数据库也是各自独立的,在连接关闭后,临时数据库将自动消失,其底层文件也将被自动删除。
尽管磁盘文件被创建用于存储临时数据库中的数据信息,但是实际上临时数据库也会和内存数据库一样通常驻留在内存中,唯一不同的是,当临时数据库中数据量过大时,SQLite为了保证有更多的内存可用于其它操作,因此会将临时数据库中的部分数据写到磁盘文件中,而内存数据库则始终会将数据存放在内存中。
来源:https://www.cnblogs.com/pjl1119/p/9657206.html