1.容器及其三要素
1.1.容器是什么
容器的本质是一种特殊的进程。
在linux容器中有三个重要的概念:Namespace、Cgroups、rootfs。
Namespace做隔离,让进程只能看到Namespace中的世界;
Cgroups 做限制,让这个“世界”围着一个看不见的墙。
rootfs 做文件系统,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。
这样就实现了进程在我们所看到的一个与世隔绝的房间,这个房间就是Pass项目赖以生存的"沙盒"。

1.2.Namespace
进入容器后,ps命令看到的容器的应用进程都是1号进程,这个其实是pid namespace导致,他其实就是个障眼法,
让你看到的是类似于一个新的虚拟机新环境,其实是不一样的,容器就是一个运行的进程,而容器中的其他进程则是pid为1的子进程。
除了刚刚pid namespace,还有其它的namespace如下:

容器是怎么新建namespace的?
docker创建容器,其实就是linux系统的一次fork的调用,
在进行fork调用时,会传入一些flag参数,这个参数可以控制对linux内核调用新的namespace。
1.3.rootfs
挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
容器的rootfs由三部分组成,1:只读层、2:可读写层、3:init层
1.只读层:都以增量的方式分别包含了 操作系统的一部分。
2.可读写:就是专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用 docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub 上,供其他人使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量 rootfs 的好处。
3.Init 层:是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
5.kubernetes Service:让客户端发现pod并与之通信
5.1.Service介绍
5.1.1.Serice简介
5.1.1.1什么是Service
service是k8s中的一个重要概念,主要是提供负载均衡和服务自动发现。
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。
5.1.1.2.Service的创建
创建Service的方法有两种:
1.通过kubectl expose创建
#kubectl expose deployment nginx --port=88 --type=NodePort --target-port=80 --name=nginx-service 这一步说是将服务暴露出去,实际上是在服务前面加一个负载均衡,因为pod可能分布在不同的结点上。 –port:暴露出去的端口 –type=NodePort:使用结点+端口方式访问服务 –target-port:容器的端口 –name:创建service指定的名称
2.通过yaml文件创建
创建一个名为hostnames-yaohong的服务,将在端口80接收请求并将链接路由到具有标签选择器是app=hostnames的pod的9376端口上。
使用kubectl creat来创建serivice
apiVersion: v1
kind: Service
metadata:
name: hostnames-yaohong
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80 //该服务的可用端口
targetPort: 9376 //具有app=hostnames标签的pod都属于该服务
5.1.1.3.检测服务
使用如下命令来检查服务:
$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.187.0.1 <none> 443/TCP 18d
5.1.1.4.在运行的容器中远程执行命令
使用kubectl exec 命令来远程执行容器中命令
$ kubectl -n kube-system exec coredns-7b8dbb87dd-pb9hk -- ls / bin coredns dev etc home lib media mnt proc root run sbin srv sys tmp usr var双横杠(--)代表kubectl命令项的结束,在双横杠后面的内容是指pod内部需要执行的命令。
5.2.连接集群外部的服务
5.2.1.介绍服务endpoint
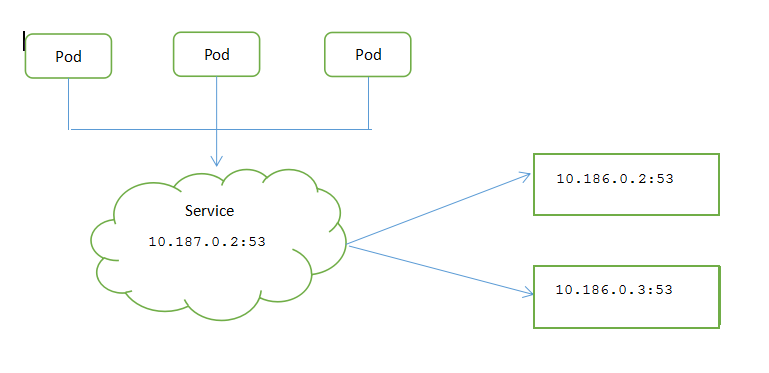
服务并不是和pod直接相连的,介于他们之间的就是Endpoint资源。
Endpoint资源就是暴露一个服务的IP地址和端口列表。
通过service查看endpoint方法如下:
$ kubectl -n kube-system get svc kube-dns
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterI
P 10.187.0.2 <none> 53/UDP,53/TCP 19d
$ kubectl -n kube-system describe svc kube-dns
Name: kube-dns
Namespace: kube-system
Labels: addonmanager.kubernetes.io/mode=Reconcile
k8s-app=kube-dns
kubernetes.io/cluster-service=true
kubernetes.io/name=CoreDNS
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{"prometheus.io/scrape":"true"},"labels":{"addonmanager.kubernetes.io/mode":...
prometheus.io/scrape: true
Selector: k8s-app=kube-dns
Type: ClusterIP
IP: 10.187.0.2
Port: dns 53/UDP
TargetPort: 53/UDP
Endpoints: 10.186.0.2:53,10.186.0.3:53 //代表服务endpoint的pod的ip和端口列表
Port: dns-tcp 53/TCP
TargetPort: 53/TCP
Endpoints: 10.186.0.2:53,10.186.0.3:53
Session Affinity: None
Events: <none>
直接查看endpoint信息方法如下:
#kubectl -n kube-system get endpoints kube-dns
NAME ENDPOINTS AGE
kube-dns 10.186.0.2:53,10.186.0.3:53,10.186.0.2:53 + 1 more... 19d
#kubectl -n kube-system describe endpoints kube-dns
Name: kube-dns
Namespace: kube-system
Labels: addonmanager.kubernetes.io/mode=Reconcile
k8s-app=kube-dns
kubernetes.io/cluster-service=true
kubernetes.io/name=CoreDNS
Annotations: <none>
Subsets:
Addresses: 10.186.0.2,10.186.0.3
NotReadyAddresses: <none>
Ports:
Name Port Protocol
---- ---- --------
dns 53 UDP
dns-tcp 53 TCP
Events: <none>
5.2.2.手动配置服务的endpoint
如果创建pod时不包含选择器,则k8s将不会创建endpoint资源。这样就需要创建endpoint来指的服务的对应的endpoint列表。
service中创建endpoint资源,其中一个作用就是用于service知道包含哪些pod。
5.2.3.为外部服务创建别名
除了手动配置来访问外部服务外,还可以使用完全限定域名(FQDN)访问外部服务。
apiVersion: v1 kind: Service metadata: name: Service-yaohong spec: type: ExternalName //代码的type被设置成了ExternalName
externalName: someapi.somecompany.com // 实际服务的完全限定域名(FQDN)port: - port: 80
服务创建完成后,pod可以通过external-service.default.svc.cluster.local域名(甚至是external-service)连接外部服务。
5.3.将服务暴露给外部客户端
有3种方式在外部访问服务:
1.将服务的类型设置成NodePort;
2.将服务的类型设置成LoadBalance;
3.创建一个Ingress资源。
5.3.1.使用nodeport类型的服务
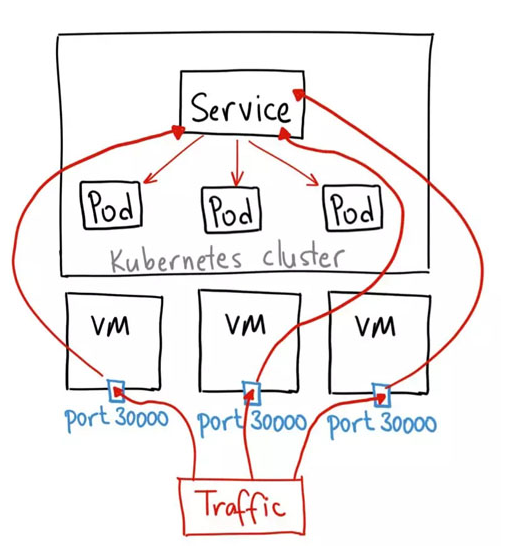
NodePort 服务是引导外部流量到你的服务的最原始方式。NodePort,正如这个名字所示,在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务。
YAML 文件类似如下:
apiVersion: v1
kind: Service
metadata:
name: Service-yaohong
spec:
type: NodePort //为NodePort设置服务类型
ports:
- port: 80
targetPort: 8080
nodeport: 30123 //通过集群节点的30123端口可以访问服务
selector:
app: yh
这种方法有许多缺点:
1.每个端口只能是一种服务
2.端口范围只能是 30000-32767
如果节点/VM 的 IP 地址发生变化,你需要能处理这种情况
基于以上原因,我不建议在生产环境上用这种方式暴露服务。如果你运行的服务不要求一直可用,或者对成本比较敏感,你可以使用这种方法。这样的应用的最佳例子是 demo 应用,或者某些临时应用。
5.3.2.通过Loadbalance将服务暴露出来
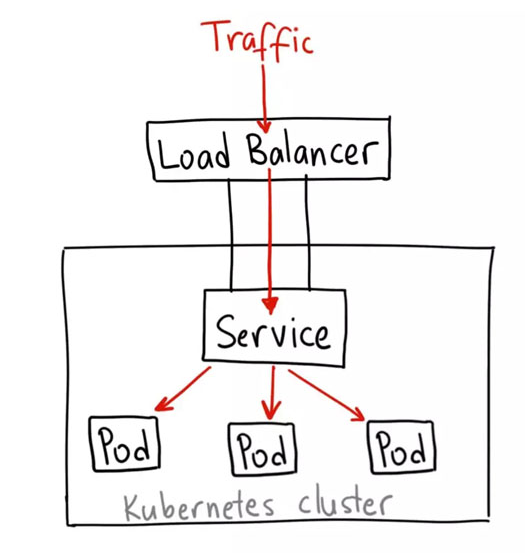
LoadBalancer 服务是暴露服务到 internet 的标准方式。在 GKE 上,这种方式会启动一个 Network Load Balancer[2],它将给你一个单独的 IP 地址,转发所有流量到你的服务。
通过如下方法来定义服务使用负载均衡
apiVersion: v1
kind: Service
metadata:
name: loadBalancer-yaohong
spec:
type: LoadBalancer //该服务从k8s集群的基础架构获取负载均衡器
ports:
- port: 80
targetPort: 8080
selector:
app: yh
何时使用这种方式?
如果你想要直接暴露服务,这就是默认方式。所有通往你指定的端口的流量都会被转发到对应的服务。它没有过滤条件,没有路由等。这意味着你几乎可以发送任何种类的流量到该服务,像 HTTP,TCP,UDP,Websocket,gRPC 或其它任意种类。
这个方式的最大缺点是每一个用 LoadBalancer 暴露的服务都会有它自己的 IP 地址,每个用到的 LoadBalancer 都需要付费,这将是非常昂贵的。
5.4.通过Ingress暴露服务
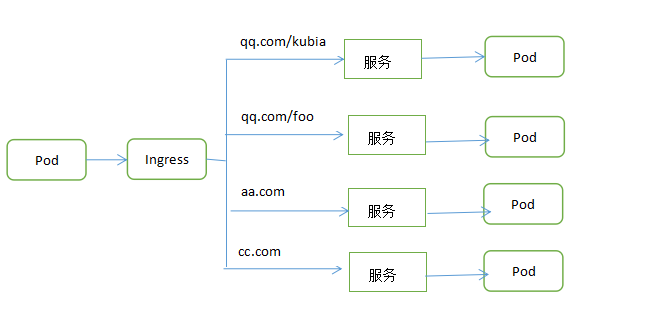
为什么使用Ingress,一个重要的原因是LoadBalancer服务都需要创建自己的负载均衡器,以及独有的公有Ip地址,而Ingress只需要一个公网Ip就能为许多服务提供访问。
5.4.1.创建Ingress资源
Ingress 事实上不是一种服务类型。相反,它处于多个服务的前端,扮演着“智能路由”或者集群入口的角色。
你可以用 Ingress 来做许多不同的事情,各种不同类型的 Ingress 控制器也有不同的能力。

编写如下ingress.yml文件
kind: Ingress
metadata:
name: ingressyaohong
spec:
rules:
- host: kubia.example.com
http:
paths:
- path: /
backend:
serviceName: kubia-nodeport
servicePort: 80
通过如下命令进行查看ingress
# kubectl create -f ingress.yml
5.4.2.通过Ingress访问服务
通过kubectl get ing命令进行查看ingress
# kubectl get ing NAME HOSTS ADDRESS PORTS AGE ingressyaohong kubia.example.com 80 2m
了解Ingress的工作原理
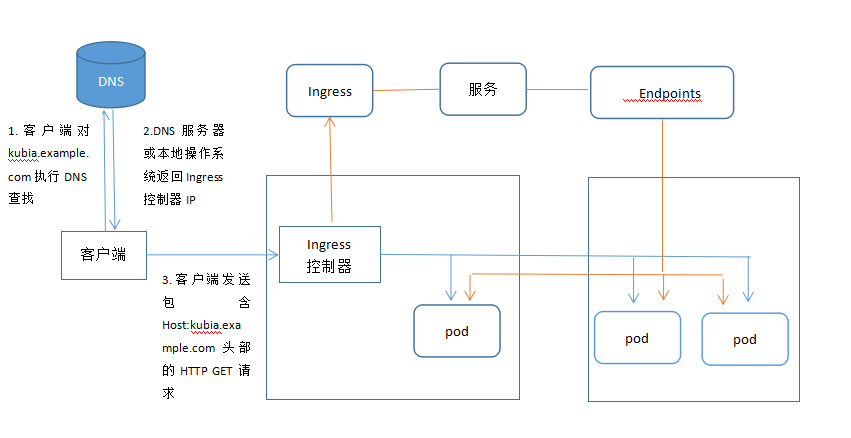
何时使用这种方式?
Ingress 可能是暴露服务的最强大方式,但同时也是最复杂的。Ingress 控制器有各种类型,包括 Google Cloud Load Balancer, Nginx,Contour,Istio,等等。它还有各种插件,比如 cert-manager[5],它可以为你的服务自动提供 SSL 证书。
如果你想要使用同一个 IP 暴露多个服务,这些服务都是使用相同的七层协议(典型如 HTTP),那么Ingress 就是最有用的。如果你使用本地的 GCP 集成,你只需要为一个负载均衡器付费,且由于 Ingress是“智能”的,你还可以获取各种开箱即用的特性(比如 SSL、认证、路由等等)。
5.4.3.通过相同的Ingress暴露多少服务
1.将不同的服务映射到相同的主机不同的路径
apiVersion: v1
kind: Ingress
metadata:
name: Ingress-yaohong
spec:
rules:
- host: kubia.example.com
http:
paths:
- path: /yh //对kubia.example.com/yh请求转发至kubai服务
backend:
serviceName: kubia
servicePort:80
- path: /foo //对kubia.example.com/foo请求转发至bar服务
backend:
serviceName: bar
servicePort:80
2.将不同的服务映射到不同的主机上
apiVersion: v1
kind: Ingress
metadata:
name: Ingress-yaohong
spec:
rules:
- host: yh.example.com
http:
paths:
- path: / //对yh.example.com请求转发至kubai服务
backend:
serviceName: kubia
servicePort:80
- host: bar.example.com
http:
paths:
- path: / //对bar.example.com请求转发至bar服务
backend:
serviceName: bar
servicePort:80
5.4.4.配置Ingress处理TLS传输
客户端和控制器之间的通信是加密的,而控制器和后端pod之间的通信则不是。
apiVersion: v1
kind: Ingress
metadata:
name: Ingress-yaohong
spec:
tls: //在这个属性中包含所有的TLS配置
- hosts:
- yh.example.com //将接收来自yh.example.com的TLS连接
serviceName: tls-secret //从tls-secret中获得之前创立的私钥和证书
rules:
- host: yh.example.com
http:
paths:
- path: / //对yh.example.com请求转发至kubai服务
backend:
serviceName: kubia
servicePort:80
5.5.pod就绪后发出信号
5.5.1.介绍就绪探针
就绪探针有三种类型:
1.Exec探针,执行进程的地方。容器的状态由进程的退出状态代码确定。
2.HTTP GET探针,向容器发送HTTP GET请求,通过响应http状态码判断容器是否准备好。
3.TCP socket探针,它打开一个TCP连接到容器的指定端口,如果连接建立,则认为容器已经准备就绪。
启动容器时,k8s设置了一个等待时间,等待时间后才会执行一次准备就绪检查。之后就会周期性的进行调用探针,并根据就绪探针的结果采取行动。
如果某个pod未就绪成功,则会从该服务中删除该pod,如果pod再次就绪成功,则从新添加pod。
与存活探针区别:
就绪探针如果容器未准备就绪,则不会终止或者重启启动。
存活探针通过杀死异常容器,并用新的正常的容器来替代他保证pod正常工作。
就绪探针只有准备好处理请求pod才会接收他的请求。
重要性;
确保客户端只与正常的pod进行交互,并且永远不会知道系统存在问题。
5.5.2.向pod添加就绪探针
添加的yml文件如下
apiVersion: v1
kind: deployment
...
spec:
...
port:
containers:
- name: kubia-yh
imgress: luksa/kubia
readinessProbe:
failureThreshold: 2
httpGet:
path: /ping
port: 80
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
相关参数解释如下:
- initialDelaySeconds:容器启动和探针启动之间的秒数。
- periodSeconds:检查的频率(以秒为单位)。默认为10秒。最小值为1。
- timeoutSeconds:检查超时的秒数。默认为1秒。最小值为1。
- successThreshold:失败后检查成功的最小连续成功次数。默认为1.活跃度必须为1。最小值为1。
- failureThreshold:当Pod成功启动且检查失败时,Kubernetes将在放弃之前尝试failureThreshold次。放弃生存检查意味着重新启动Pod。而放弃就绪检查,Pod将被标记为未就绪。默认为3.最小值为1。
HTTP探针在httpGet上的配置项:
- host:主机名,默认为pod的IP。
- scheme:用于连接主机的方案(HTTP或HTTPS)。默认为HTTP。
- path:探针的路径。
- httpHeaders:在HTTP请求中设置的自定义标头。 HTTP允许重复的请求头。
- port:端口的名称或编号。数字必须在1到65535的范围内
模拟就绪探针
# kubectl exec <pod_name> -- curl http://10.187.0.139:80/ping
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
5.6.使用headless服务发现独立的pod
5.6.1.创建headless服务
Headless Service也是一种Service,但不同的是会定义spec:clusterIP: None,也就是不需要Cluster IP的Service。
顾名思义,Headless Service就是没头的Service。有什么使用场景呢?
-
第一种:自主选择权,有时候
client想自己来决定使用哪个Real Server,可以通过查询DNS来获取Real Server的信息。 -
第二种:
Headless Services还有一个用处(PS:也就是我们需要的那个特性)。Headless Service的对应的每一个Endpoints,即每一个Pod,都会有对应的DNS域名;这样Pod之间就可以互相访问。
6.kubernetes 磁盘、PV、PVC
6.1.介绍卷
6.1.1.卷的类型
emptyDir-用于存储临时数据的简单空目录
hostPath-用于将目录从工作节点的文件系统挂载到pod
nfs-挂载到pod中的NFS共享卷。
还有其他的如gitRepo、gcepersistenDisk
6.2.通过卷在容器间共享数据
6.2.1.使用emptyDir卷
卷的生命周期与pod的生命周期项关联,所以当删除pod时,卷的内容就会丢失。
使用empty示例代码如下:
apiVersion: v1
kind: Pod
metadata:
name: fortune
spec:
containers:
- image: luksa/fortune
name: html-gener
volumeMounts:
- name: html
mountPath: /usr/share/nginx
readOnly: true
- image: nginx/aplin
name: web-service
volumeMounts:
- name: html
mountPath: /usr/share
readOnly: true
volumes:
- name: html //一个名为html的单独emptyDir卷,挂载在上面的两个容器中
emptyDir: {}
6.3.访问工作节点文件系统上的文件
6.3.1.hostPath卷
hostPath是持久性存储,emptyDir卷的内容随着pod的删除而删除。
使用hostPath会发现当删除一个pod,并且下一个pod使用了指向主机上相同路径的hostPath卷,则新pod将会发现上一个pod留下的数据,但前提是必须将其调度到与第一个pod相同的节点上。
所以当你使用hostPath时请务必考虑清楚,当重新起一个pod时候,必须要保证pod的节点与之前相同。
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory
6.4.使用持久化存储
怎样保证pod重新启动后调度到任意一个节点都有相同的数据可用,这就需要做到持久化存储。
因此必须要将数据存储在某种类型的网络存储(NAS)中。
各种支持的方式不尽相同,例如 GlusterFS 需要创建 Endpoint,Ceph/NFS 之流就没这么麻烦了。
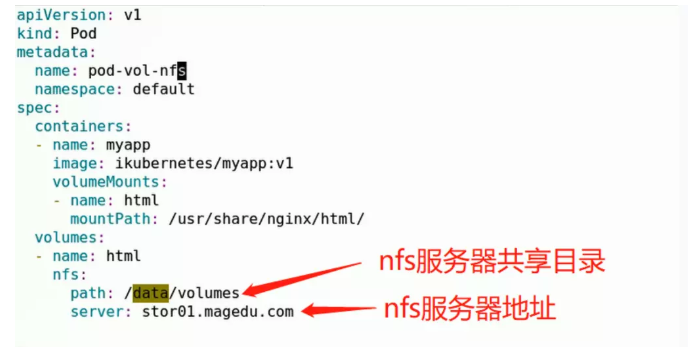
6.4.1.使用NFS存储
以NFS为例,yml代码如下:
6.4.2.configmap和secert
secret和configmap可以理解为特殊的存储卷,但是它们不是给Pod提供存储功能的,而是提供了从集群外部向集群内部的应用注入配置信息的功能。ConfigMap扮演了K8S集群中配置中心的角色。ConfigMap定义了Pod的配置信息,可以以存储卷的形式挂载至Pod中的应用程序配置文件目录,从configmap中读取配置信息;也可以基于环境变量的形式,从ConfigMap中获取变量注入到Pod容器中使用。但是ConfigMap是明文保存的,如果用来保存数据库账号密码这样敏感信息,就非常不安全。一般这样的敏感信息配置是通过secret来保存。secret的功能和ConfigMap一样,不过secret是通过Base64的编码机制保存配置信息。
从ConfigMap中获取配置信息的方法有两种:
- 一种是利用环境变量将配置信息注入Pod容器中的方式,这种方式只在Pod创建的时候生效,这就意味着在ConfigMap中的修改配置信息后,更新的配置不能被已经创建Pod容器所应用。
- 另一种是将ConfigMap做为存储卷挂载至Pod容器内,这样在修改ConfigMap配置信息后,Pod容器中的配置也会随之更新,不过这个过程会有稍微的延迟。
ConfigMap当作存储卷挂载至Pod中的用法:
apiVersion: v1
kind: Pod
metadata:
name: pod-configmap-vol-2
labels:
name: pod-configmap-vol-2
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
volumeMounts:
- name: my-cm-www
mountPath: /etc/nginx/conf.d/ # 将名为my-www的configmap挂载至Pod容器的这个目录下。
volumes:
- name: my-cm-www
configMap: # 存储卷类型选configMap
secert的方法类似,只是secert对数据进行了加密
6.5.从底层存储技术解耦pod
6.5.1.介绍持久卷和持久卷声明
当集群用户需要在其pod中使用持久化存储时,他们首先创建持久化声明(PVC)清单,指定所需要的最低容量要求,和访问模式,然后用户将持久卷声明清单提交给kubernetes API服务器,kubernetes将找到可以匹配的持久卷并将其绑定到持久卷声明。
持久卷声明可以当做pod中的一个卷来使用,其他用户不能使用相同的持久卷,除非先通过删除持久卷声明绑定来释放。
6.5.2.创建持久卷
下面创建一个 PV mypv1,配置文件pv1.yml 如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: yh_pv1
spec:
capacity:
storage: 1Gi //capacity 指定 PV 的容量为 1G
accessModes: //accessModes 指定访问模式为 ReadWriteOnce
- ReadWriteOnce
persistentVolumeReclaimpolicy: Recycle //persistentVolumeReclaimPolicy 指定当 PV 的回收策略为 Recycle
storageClassName: nfs //storageClassName 指定 PV 的 class 为 nfs。相当于为 PV 设置了一个分类,PVC 可以指定 class 申请相应 class 的 PV。
nfs:
path: /nfs/data //指定 PV 在 NFS 服务器上对应的目录
server: 10.10.0.11
1.accessModes 指定访问模式为 ReadWriteOnce,支持的访问模式有:
ReadWriteOnce – PV 能以 read-write 模式 mount 到单个节点。
ReadOnlyMany – PV 能以 read-only 模式 mount 到多个节点。
ReadWriteMany – PV 能以 read-write 模式 mount 到多个节点。
2.persistentVolumeReclaimPolicy 指定当 PV 的回收策略为 Recycle,支持的策略有:
Retain – 需要管理员手工回收。
Recycle – 清除 PV 中的数据,效果相当于执行 rm -rf /thevolume/*。
Delete – 删除 Storage Provider 上的对应存储资源,例如 AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume 等。
创建 pv:
# kubectl apply -f pv1.yml persistentvolume/yh-pv1 created
查看pv:
# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE yh-pv1 1Gi RWO Recycle Available nfs 17m
STATUS 为 Available,表示 yh-pv1就绪,可以被 PVC 申请。
6.5.3.通过持久卷声明来获取持久卷
接下来创建 PVC mypvc1,配置文件 pvc1.yml 如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: yh-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: nfs
PVC 就很简单了,只需要指定 PV 的容量,访问模式和 class。
执行命令创建 mypvc1:
# kubectl apply -f pvc1.yml persistentvolumeclaim/yh-pvc created
查看pvc
# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE yh-pvc Bound yh-pv1 1Gi RWO nfs 64s
从 kubectl get pvc 和 kubectl get pv 的输出可以看到 yh-pvc1 已经 Bound 到yh- pv1,申请成功。
# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE yh-pv1 1Gi RWO Recycle Bound default/yh-pvc nfs 47m
6.5.4.在pod中使用持久卷声明
上面已经创建好了pv和pvc,pod中直接使用这个pvc即可

与使用普通 Volume 的格式类似,在 volumes 中通过 persistentVolumeClaim 指定使用 mypvc1 申请的 Volume。
通过命令创建mypod1:

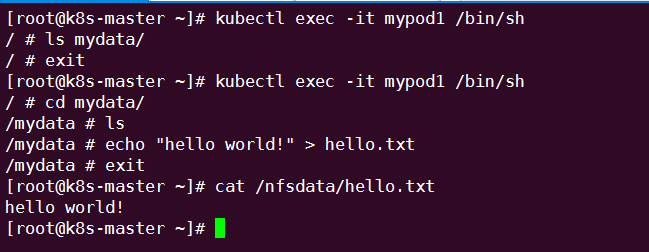
可见,在 Pod 中创建的文件 /mydata/hello 确实已经保存到了 NFS 服务器目录 /nfsdata中。
如果不再需要使用 PV,可用删除 PVC 回收 PV。
6.5.5.回收持久卷
当 PV 不再需要时,可通过删除 PVC 回收。

未删除pvc之前 pv的状态是Bound


删除pvc之后pv的状态变为Available,,此时解除绑定后则可以被新的 PVC 申请。
/nfsdata文件中的文件被删除了


因为 PV 的回收策略设置为 Recycle,所以数据会被清除,但这可能不是我们想要的结果。如果我们希望保留数据,可以将策略设置为 Retain。
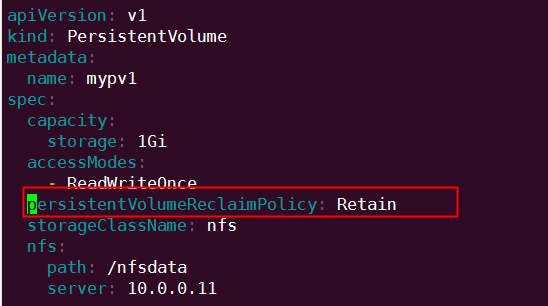
通过 kubectl apply 更新 PV:

回收策略已经变为 Retain,通过下面步骤验证其效果:
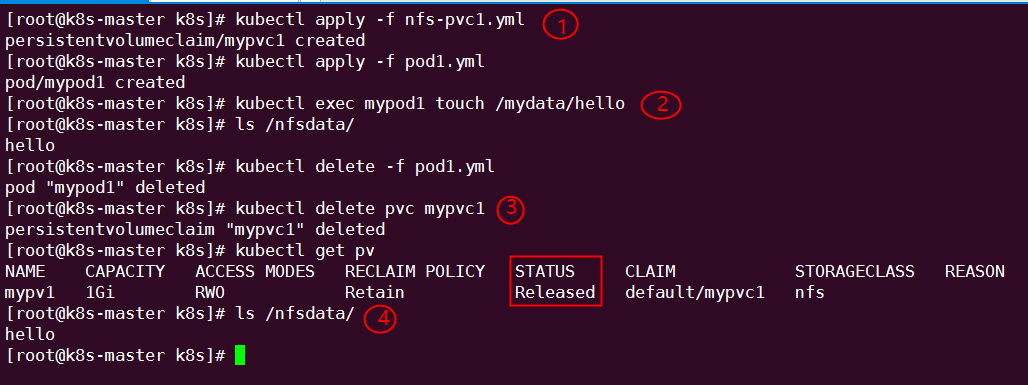
① 重新创建 mypvc1。
② 在 mypv1 中创建文件 hello。
③ mypv1 状态变为 Released。
④ PV 中的数据被完整保留。
虽然 mypv1 中的数据得到了保留,但其 PV 状态会一直处于 Released,不能被其他 PVC 申请。为了重新使用存储资源,可以删除并重新创建 mypv1。删除操作只是删除了 PV 对象,存储空间中的数据并不会被删除。

新建的 mypv1 状态为 Available,已经可以被 PVC 申请。
PV 还支持 Delete 的回收策略,会删除 PV 在 Storage Provider 上对应存储空间。NFS 的 PV 不支持 Delete,支持 Delete 的 Provider 有 AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume 等。
6.6.持久卷的动态配置
6.6.1.通过StorageClass资源定义可用存储类型
前面的例子中,我们提前创建了 PV,然后通过 PVC 申请 PV 并在 Pod 中使用,这种方式叫做静态供给(Static Provision)。
与之对应的是动态供给(Dynamical Provision),即如果没有满足 PVC 条件的 PV,会动态创建 PV。相比静态供给,动态供给有明显的优势:不需要提前创建 PV,减少了管理员的工作量,效率高。
动态供给是通过 StorageClass 实现的,StorageClass 定义了如何创建 PV,下面是两个例子。
StorageClass standard:

StorageClass slow:
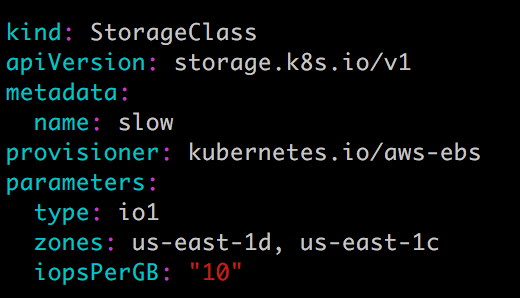
这两个 StorageClass 都会动态创建 AWS EBS,不同在于 standard 创建的是 gp2 类型的 EBS,而 slow 创建的是 io1 类型的 EBS。不同类型的 EBS 支持的参数可参考 AWS 官方文档。
StorageClass 支持 Delete 和 Retain 两种 reclaimPolicy,默认是 Delete。
与之前一样,PVC 在申请 PV 时,只需要指定 StorageClass 和容量以及访问模式,比如:

除了 AWS EBS,Kubernetes 支持其他多种动态供给 PV 的 Provisioner,完整列表请参考 https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner
6.6.2.PV&&PVC在应用在mysql的持久化存储
下面演示如何为 MySQL 数据库提供持久化存储,步骤为:
-
创建 PV 和 PVC。
-
部署 MySQL。
-
向 MySQL 添加数据。
-
模拟节点宕机故障,Kubernetes 将 MySQL 自动迁移到其他节点。
-
验证数据一致性。
首先创建 PV 和 PVC,配置如下:
mysql-pv.yml

mysql-pvc.yml
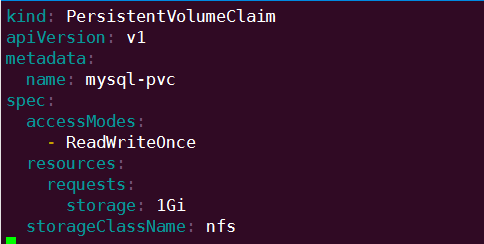
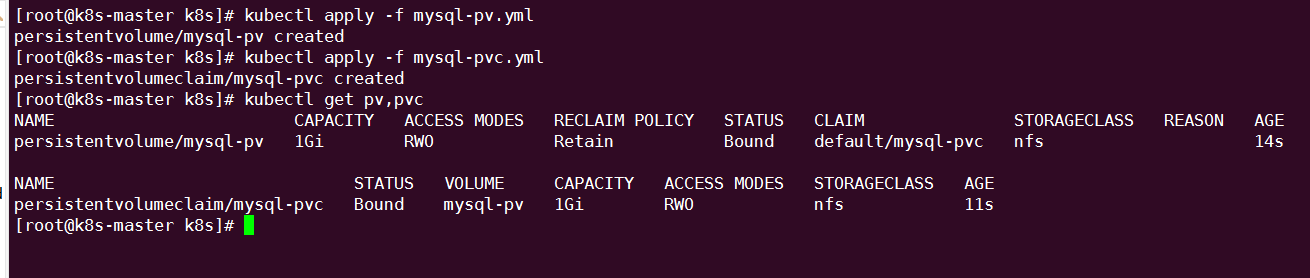
创建 mysql-pv 和 mysql-pvc:
接下来部署 MySQL,配置文件如下:
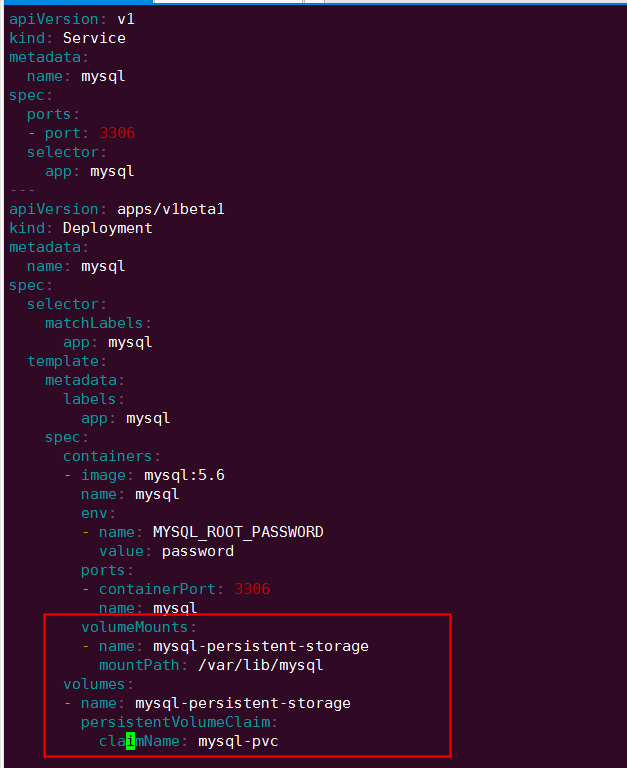
PVC mysql-pvc Bound 的 PV mysql-pv 将被 mount 到 MySQL 的数据目录 var/lib/mysql。

MySQL 被部署到 k8s-node2,下面通过客户端访问 Service mysql:
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword

更新数据库:

① 切换到数据库 mysql。
② 创建数据库表 my_id。
③ 插入一条数据。
④ 确认数据已经写入。
关闭 k8s-node2,模拟节点宕机故障。

验证数据的一致性:
由于node2节点已经宕机,node1节点接管了这个任务。

通过kubectl run 命令 进入node1的这个pod里,查看数据是否依旧存在

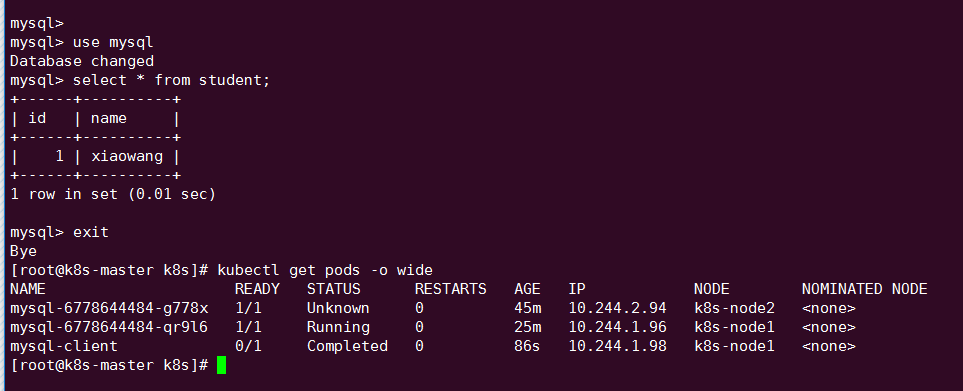
MySQL 服务恢复,数据也完好无损。
7.kubernetes ConfigMap和Secret:配置应用程序
7.1.配置容器化应用程序
7.2.向容器传递命令行参数
7.2.1.待Docker中定义命令与参数
1.了解ENTRYPOINT与CMD
ENTRYPOINT定义容器启动时被调用的可以执行程序
CMD指定传递给ENTRYP的参数
dockerfile 内容如下
FROM daocloud.io/centos:latest ADD aaa /usr/local/aaa CMD ["-f","/var/log/aa.log"] ENTRYPOINT ["tail"]
当启动镜像时,容器启动时执行如下命令:tail -f /var/log/aa.log
或者在docker run <images> <arguments> 中指定,arguments会覆盖CMD中内容
7.2.2.在kubernetes中覆盖命令行和参数
在k8s中定义容器时,镜像的ENTRYPOINT和CMD都可以被覆盖,仅需在容器定义中设置熟悉command和args的值
对应参数如下:
| Docker | kubernetes | 描述 |
| ENTRYPOINT | command | 容器中运行的可执行文件 |
| CMD | args | 传给可执行文件的参数 |
相关yml代码如下:
kind: pod
spec:
containers:
- image: some/image
command: ["/bin/command"]
args: ["args1","args2","args3"]
7.3.为容器设置环境变量
7.3.1.在容器定义中指定环境变量
与容器的命令和参数设置相同,环境变量列表无法在pod创建后被修改。
在pod的yml文件中设置容器环境变量代码如下:
kind: pod
spec:
containers:
- image: luksa/fortune:env
env:
- name: INTERVAL
value: "30"
name: value-test-yh
7.3.2.在环境变量值中引用其他环境变量
使用$( VAR )引用环境变量,
相关ym代码如下:
env: - name: FIRST_VAR value: "foo" - name: SECOND_VAR value: "$(FIRST_VAR)bar" //最终变量值为foobar
7.4.利用ConfigMap解耦配置
7.4.1.ConfigMap介绍
kubernetes允许将配置选项分离到独立的资源对象ConfigMap中,本质上就是一个键/值对映射,值可以是短字面变量,也可以是完整的配置文件。
应用无须直接读取ConfigMap,甚至根本不需要知道其是否存在。
映射的内容通过环境变量或者卷文件的形式传递给容器,而并非直接传递给容器,命令行参数的定义中也是通过$(ENV_VAR)语法变量
7.4.2.创建ConfigMap
使用kubectl creat configmap创建ConfigMap中间不用加-f。
1.使用指令创建ConfigMap
#kubectl creat configmap configmap-yaohong --from-literal=foo=bar --from-literal=sleep-interval=25
2.从文件内容创建ConfigMap条目
#kubectl create configmap my-conf-yh --from-file=config-file.conf
使用如下命令,会将文件内容存储在自定义的条目下。与字面量使用相同
#kubectl create configmap my-conf-yh --from-file=customkey=config-file.conf
3.从文件夹创建ConfigMap
#kubectl create configmap my-conf-yh --from-file=/path/to/dir
4.合并不同选项
#kubectl create configmap my-conf-yh --from-file=/path/to/dir/ --from-file=bar=foobar.conf --from-literal=some=thing
5.获取ConfigMap
#kubectl -n <namespace> get configmap
7.4.3.给容器传递ConfigMap条目作为环境变量
引用环境变量中的参数值给当前变量
apiVersion: v1
kind: pod
metadata:
name: fortune-env-from-configmap
spec:
containers:
- image: luksa/fortune:env
env:
- name: INTERVAL //设置环境变量
valueFrom:
configMapkeyRef:
name: fortune-configmap
key: sleep-interval //变量的值取自fortune-configmap的slee-interval对应的值
7.4.4.一次性传递ConfigMap的所有条目作为环境变量
apiVersion: v1
kind: pod
metadata:
name: fortune-env-from-configmap
spec:
containers:
- image: luksa/fortune:env
envFrom:
- prefix: CONFIG_
confgMapRef:
name: my-confg-map //引用my-config-map的ConfigMap并在变量前面都加上CONFIG_
7.4.5.使用ConfigMap卷将条目暴露为文件
apiVersion: v1
kind: pod
metadata:
name: configmap-volume-yh
spec:
containers:
- image: nginx:aplin
name: web-server
volumeMounts:
...
- name: config defaultMode: "6600" //设置文件的权限为rw-rw
mountPath: /etc/nginx/con.conf subPath: my.conf //subPath字段可以用于挂载卷中某个独立的文件或者文件夹,而且不覆盖该卷下其他文件
...
volume:
...
- name: config
configMap:
name: fortune-config //引用fortune-config configMap的卷,然后挂载在/etc/nginx/conf.d
可以使用如下命令查看到/etc/nginx/conf.d文件下面包含fortune-config
#kubectl exec config-volume-yh -c web-server ls /etc/nginx/conf.d
7.5.使用Secert给容器传递敏感数据
7.5.1.介绍Secert
Secret结构和ConfigMap类似,均是键/值对的映射。
使用方法也和ConfigMap一样,可以:
1.将Secret条目作为环境变量传递给容器,
2.将Secret条目暴露为卷中文件
ConfigMap存储非敏感的文本配置数据,采用Secret存储天生敏感的数据
7.5.2.默认令牌Secret
1.查看secret
# kubectl get secrets NAME TYPE DATA AGE default-token-x9cjb kubernetes.io/service-account-token 3 78d
2.描述secret
# kubectl describe secrets default-token-x9cjb
Name: default-token-x9cjb
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: default
kubernetes.io/service-account.uid: 64a41a09-98ce-11e9-9fa5-fa163e6fdb6b
Type: kubernetes.io/service-account-token
Data
====
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5lduaW8vc2VydmljZTxCv6HdtP-ZW3ZC2IKKR5YBhaokFIl35mix79pU4Ia2pJ_fuPTBGNyrCHyNQYH4ex5DhND3_b2puQmn8RSErQ
ca.crt: 1298 bytes
namespace: 7 bytes
7.5.3.创建Secret
1.创建一个名为https-yh的generic secret
#kubectl create secret generic https-yh --from-file=https.key --from-file=https.cert --from-file=foo
2.创建一个secret.yaml文件,内容用base64编码
$ echo -n 'admin' | base64 YWRtaW4= $ echo -n '1f2d1e2e67df' | base64 MWYyZDFlMmU2N2Rm
yaml文件内容:

apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: username: YWRtaW4= password: MWYyZDFlMmU2N2Rm
创建:
$ kubectl create -f ./secret.yaml secret "mysecret" created
解析Secret中内容
$ kubectl get secret mysecret -o yaml apiVersion: v1 data: username: YWRtaW4= password: MWYyZDFlMmU2N2Rm kind: Secret metadata: creationTimestamp: 2016-01-22T18:41:56Z name: mysecret namespace: default resourceVersion: "164619" selfLink: /api/v1/namespaces/default/secrets/mysecret uid: cfee02d6-c137-11e5-8d73-42010af00002 type: Opaque
base64解码:
$ echo 'MWYyZDFlMmU2N2Rm' | base64 --decode 1f2d1e2e67df
7.5.4.对比ConfigMap与Secret
Secret的条目内容会进行Base64格式编码,而ConfigMap直接以纯文本展示。
1.为二进制数据创建Secret
Base64可以将二进制数据转换为纯文本,并以YAML或Json格式进行展示
但要注意Secret的大小限制是1MB
2.stringDate字段介绍
Secret可以通过StringDate字段设置条目的纯文本
kind: Secret apiVersion: v1 stringDate: foo: plain txt date: https.cert: HGIOPUPSDF63456BJ3BBJL34563456BLKJBK634563456BLBKJBLKJ63456BLK3456LK http.key: OHOPGPIU42342345OIVBGOI3456345OVB6O3456BIPO435B6IPU345UI
7.5.5.在pod中使用Secret
secret可以作为数据卷挂载或者作为环境变量暴露给Pod中的容器使用,也可以被系统中的其他资源使用。比如可以用secret导入与外部系统交互需要的证书文件等。
在Pod中以文件的形式使用secret
- 创建一个Secret,多个Pod可以引用同一个Secret
- 修改Pod的定义,在
spec.volumes[]加一个volume,给这个volume起个名字,spec.volumes[].secret.secretName记录的是要引用的Secret名字 - 在每个需要使用Secret的容器中添加一项
spec.containers[].volumeMounts[],指定spec.containers[].volumeMounts[].readOnly = true,spec.containers[].volumeMounts[].mountPath要指向一个未被使用的系统路径。 - 修改镜像或者命令行使系统可以找到上一步指定的路径。此时Secret中
data字段的每一个key都是指定路径下面的一个文件名
下面是一个Pod中引用Secret的列子:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
每一个被引用的Secret都要在spec.volumes中定义
如果Pod中的多个容器都要引用这个Secret那么每一个容器定义中都要指定自己的volumeMounts,但是Pod定义中声明一次spec.volumes就好了。
映射secret key到指定的路径
可以控制secret key被映射到容器内的路径,利用spec.volumes[].secret.items来修改被映射的具体路径
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
发生了什么呢?
- username被映射到了文件
/etc/foo/my-group/my-username而不是/etc/foo/username - password没有变
Secret文件权限
可以指定secret文件的权限,类似linux系统文件权限,如果不指定默认权限是0644,等同于linux文件的-rw-r--r--权限
设置默认权限位
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
defaultMode: 256
上述文件表示将secret挂载到容器的/etc/foo路径,每一个key衍生出的文件,权限位都将是0400
由于JSON不支持八进制数字,因此用十进制数256表示0400,如果用yaml格式的文件那么就很自然的使用八进制了
同理可以单独指定某个key的权限
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
mode: 511
从volume中读取secret的值
值得注意的一点是,以文件的形式挂载到容器中的secret,他们的值已经是经过base64解码的了,可以直接读出来使用。
$ ls /etc/foo/ username password $ cat /etc/foo/username admin $ cat /etc/foo/password 1f2d1e2e67df
被挂载的secret内容自动更新
也就是如果修改一个Secret的内容,那么挂载了该Secret的容器中也将会取到更新后的值,但是这个时间间隔是由kubelet的同步时间决定的。最长的时间将是一个同步周期加上缓存生命周期(period+ttl)
特例:以subPath形式挂载到容器中的secret将不会自动更新
以环境变量的形式使用Secret
- 创建一个Secret,多个Pod可以引用同一个Secret
- 修改pod的定义,定义环境变量并使用
env[].valueFrom.secretKeyRef指定secret和相应的key - 修改镜像或命令行,让它们可以读到环境变量
apiVersion: v1
kind: Pod
metadata:
name: secret-env-pod
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
restartPolicy: Never
容器中读取环境变量,已经是base64解码后的值了:
$ echo $SECRET_USERNAME admin $ echo $SECRET_PASSWORD 1f2d1e2e67df
使用imagePullSecrets
创建一个专门用来访问镜像仓库的secret,当创建Pod的时候由kubelet访问镜像仓库并拉取镜像,具体描述文档在 这里
设置自动导入的imagePullSecrets
可以手动创建一个,然后在serviceAccount中引用它。所有经过这个serviceAccount创建的Pod都会默认使用关联的imagePullSecrets来拉取镜像,
9.deployment:声明式的升级应用
Deployment 的控制器,实际上控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。
而一个应用的版本,对应的正是一个 ReplicaSet;这个版本应用的 Pod 数量,则由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。
通过这样的多个 ReplicaSet 对象,Kubernetes 项目就实现了对多个“应用版本”的描述。

9.1.使用RC实现滚动升级
#kubectl rolling-update kubia-v1 kubia-v2 --image=luksa/kubia:v2
使用kubia-v2版本应用来替换运行着kubia-v1的RC,将新的复制控制器命名为kubia-v2,并使用luksa/kubia:v2最为镜像。
9.2.使用Deployment声明式的升级应用
#kubectl create -f kubectl.depl-v1.yaml --record //--record可以记录历史版本 #查看Deployment的相关信息 #kubectl get deployment #kubectl describe deployment #查看部署状态: #kubectl rollout status deployment kubia
9.3.触发deployment升级
#kubectl edit deployment kubia //修改完后资源对象会被更新
#kubectl patch deployment kubia -p '{...}' //只能包含想要更新的字段
#kubectl apply -f kubia-deploy-v2.yml //如果yml中定义的资源不存在,会自动被创建
#kubectl replace -f kubia-deploy-v2.yml //如果yml中定义的资源不存在,则会报错
9.4.回滚deployment
#kubectl rollout status deployment kubia
#kubectl rollout undo deployment kubia
#kubectl rollout history deployment kubia
#kubectl rollout undo deployment kubia --to-revision=1
9.5.控制滚动升级的速率
9.6.金丝雀发布和蓝绿发布
蓝绿部署:2组机器,蓝代表当前的V1版本,绿代表已经升级完成的V2版本。通过LB将流量全部导入V2完成升级部署。优点是切换快速,缺点是影响全部用户。
10.Statefulset:部署有状态的多副本应用
10.1.什么是Statefulset
10.2.statefulset的创建
statefulset的创建顺序从0到N-1,终止顺序则相反,如果需要对satateful扩容,则之前的n个pod必须存在,如果要终止一个pod,则他的后续pod必须全部终止。
创建statefulset
#kubectl create -f ss-nginx.yml
查看statefulset
#kubectl get statefulset
statefulset会使用一个完全一致的pod来替换被删除的pod。
statefulset扩容和缩容时,都会删除最高索引的pod,当这个pod完全被删除后,才回删除拥有次高索引的pod。
10.3.statefulset中发现伙伴的节点
通过DNS中SRV互相发现。
10.4.更新statefulset
#kuebctl edit statefulset kubia
但修改后pod不会自动 被更新,需要手动delete pod后会重新调度更新。
10.5.statefulset如何处理节点失效
11.Kubernetes架构及相关服务详解
11.1.了解架构
11.2.k8s组件分布式特性
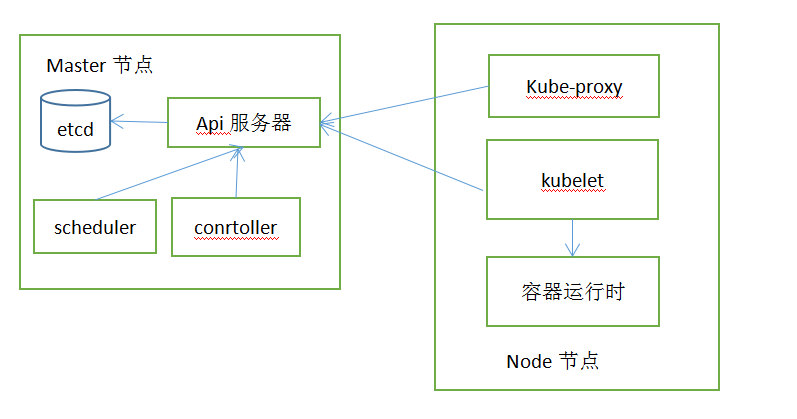
k8s系统组件之间通信只能通过API服务器通信,他们之间不会之间进行通信。
//获取Master节点服务健康状况 #kubectl get componentstatuses
11.3.k8s如何使用etcd
关于乐观锁并发控制
乐观锁并发控制(有时候指乐观锁),是指一段数据包含一个版本数字,而不是锁住该段数据并阻止读写操作。每当更新数据,版本数就会增加。当更新数据时,版本就会增加。当更新数据时,就会检查版本值是否在客户端读取数据时间和提交时间之间被增加过。如果增加过,那么更新会被拒绝,客户端必须重新读取新数据,重新尝试更新。
两个客户端尝试更新同一个数据条目,只有一个会被更新成功。
资源如何存储在etcd中
flannel操作etcd使用的是v2的API,而kubernetes操作etcd使用的v3的API,所以在下面我们执行etcdctl的时候需要设置ETCDCTL_API环境变量,该变量默认值为2。
一致性算法要求大部分节点参与,才能进行到下一个状态,需要有过半的节点参与状态的更新,所以导致etcd的节点必须为奇数个。
11.4.API服务器
Kubernetes API服务器为API对象验证和配置数据,这些对象包含Pod,Service,ReplicationController等等。API Server提供REST操作以及前端到集群的共享状态,所有其它组件可以通过这些共享状态交互。
1.API提供RESTful API的形式,进行CRUD(增删查改)集群状态
2.进行校验
3.处理乐观锁,用于处理并发问题,
4.认证客户端
(1)通过认证插件认证客户端
(2)通过授权插件认证客户端
(3)通过准入插件验证AND/OR修改资源请求
API服务器如何通知客户端资源变更
API服务器不会去创建pod,同时他不会去管理服务的端点,
它做的是,启动控制器,以及一些其他的组件来监控一键部署的资源变更,是得组件可以再集群元数据变化时候执行任何需要做的任务,
11.5.了解调度器
调度器指定pod运行在哪个集群节点上。
调度器不会命令选中节点取运行pod,调度器做的就是通过api服务器更新pod的定义。然后api服务器再去通知kubelet该pod已经被调用。当目标节点的kubelet发现该pod被调度到本节点,就会创建并运行pod容器。
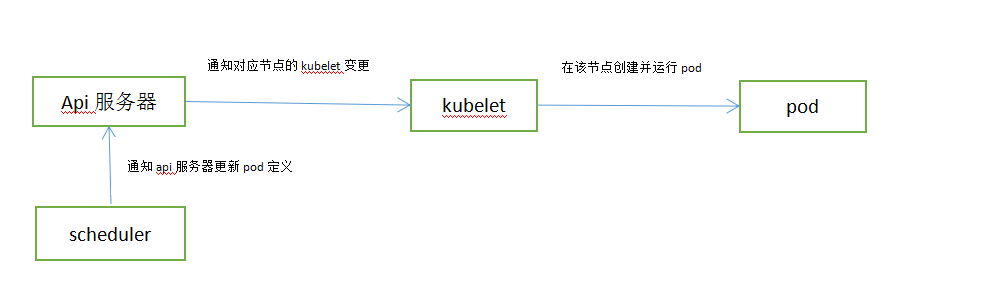
调度方法:
1.通过算法过滤所有节点,找到最优节点
2.查找可用节点
(1)是否满足对硬件的资源要求
(2)节点是否资源耗尽
(3)pod是否要求被调度到指定的节点、
(4)是否和要求的lable一致
(5)需求端口是否被占用
(6)是否有符合要求的存储卷
(7)是否容忍节点的污染
11.6.介绍控制器管理器中运行的控制器
(1)RC控制器
启动RC资源的控制器叫做Replication管理器。
RC的操作可以理解为一个无限的循环,每次循环,控制器都会查找符合其pod选择器的pod数量,并且将该数值和期望的复制集数量做比较。
(2)RS控制器
与RC类似
(3)DaemonSet以及job控制器
从他们各自资源集中定义pod模板创建pod资源,
(4)Deployment控制器
Deployment控制器负责使deployment的实际状态与对应的Deployment API对象期望状态同步。
每次Deployment对象修改后,Deployment控制器会滚动升级到新的版本。通过创建ReplicaSet,然后按照Deployment中定义的策略同时伸缩新、旧RelicaSet,直到旧pod被新的替代。
(5)StatefulSet控制器
StatefulSet控制器会初始化并管理每个pod实例的持久声明字段。
(6)Node控制器
Node控制器管理Node资源,描述了集群的工作节点。
(7)Service控制器
Service控制器就是用来在loadBalancer类型服务被创建或删除,从基础设施服务请求,释放负载均衡器的。
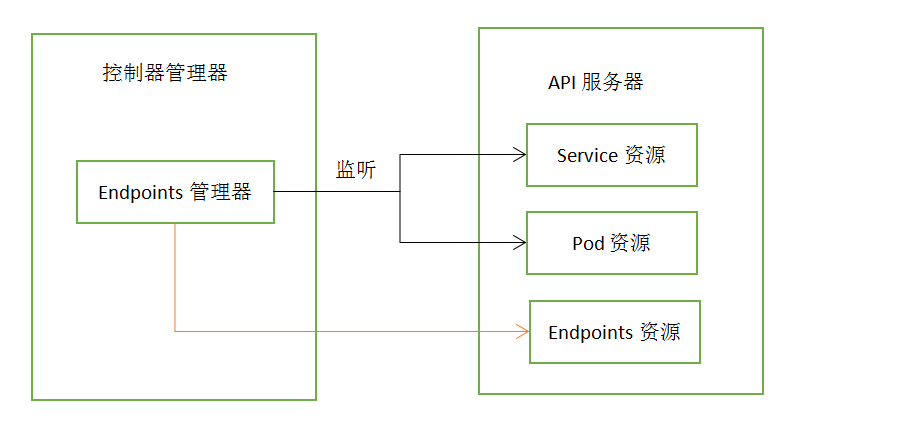
当Endpoints监听到API服务器中Aervice资源和pod资源发生变化时,会对应修改、创建、删除Endpoints资源。
(8)Endpoint资源控制器
Service不会直接连接到pod,而是通过一个ip和端口的列表,EedPoint管理器就是监听service和pod的变化,将ip和端口更新endpoint资源。
(9)Namespace控制器
当收到删除namespace对象的通知时,控制器通过API服务群删除后所有属于该命名空间的资源。
(10)PV控制器
创建一个持久卷声明时,就找到一个合适的持久卷进行绑定到声明。
11.7.kubelet做了什么
了解kubelet的工作内容
简单来说,就是负责所有运行在工作节点上的全部内容。
第一个任务,在api服务器中创建一个node资源来注册该节点;第二任务,持续监控api服务器是否把该节点分配给pod;第三任务,启动pod;第四任务,持续监控运行的容器,向api服务器报告他们的状态,事件和资源消耗。
第五任务,kubelet也是运行容器的存活探针的组件,当探针报错时,他会重启容器;第六任务,当pod从api服务器删除时,kubelet终止容器,并通知服务器pod已经终止。
11.1.7.kube-proxy的作用
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP。
kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
kube-proxy有两种代理模式,userspace和iptables,目前都是使用iptables。
12.kubernetes API服务器的安全防护
12.1.了解认证机制
启动API服务器时,通过命令行选项可以开启认证插件。
12.1.1.用户和组
了解用户:
分为两种连接到api服务器的客户端:
1.真实的人
2.pod,使用一种称为ServiceAccount的机制
了解组:
认证插件会连同用户名,和用户id返回组,组可以一次性给用户服务多个权限,不用单次赋予,
system:unauthenticated组:用于所有认证插件都不会认证客户端身份的请求。
system:authenticated组:会自动分配给一个成功通过认证的用户。
system:serviceaccount组:包含 所有在系统中的serviceaccount。
system:serviceaccount:<namespace>组:包含了所有在特定命名空间中的serviceAccount。
12.1.2 ServiceAccount介绍
每个pod中都包含/var/run/secrets/kubernetes.io/serviceaccount/token文件,如下图所示,文件内容用于对身份进行验证,token文件持有serviceaccount的认证token。

应用程序使用token去连接api服务器时,认证插件会对serviceaccount进行身份认证,并将serviceaccount的用户名传回到api服务器内部。
serviceaccount的用户名格式如下:
system:serviceaccount:<namespace>:<service account name>
ServiceAccount是运行在pod中的应用程序,和api服务器身份认证的一中方式。
了解ServiceAccount资源
ServiceAcount作用在单一命名空间,为每个命名空间创建默认的ServiceAccount。

多个pod可以使用相同命名空间下的同一的ServiceAccount,
ServiceAccount如何与授权文件绑定
在pod的manifest文件中,可以指定账户名称的方式,将一个serviceAccount赋值给一个pod,如果不指定,将使用该命名空间下默认的ServiceAccount.
可以 将不同的ServiceAccount赋值给pod,让pod访问不同的资源。
12.1.3创建ServiceAccount
为了集群的安全性,可以手动创建ServiceAccount,可以限制只有允许的pod访问对应的资源。
创建方法如下:
$ kubectl get sa NAME SECRETS AGE default 1 21h $ kubectl create serviceaccount yaohong serviceaccount/yaohong created $ kubectl get sa NAME SECRETS AGE default 1 21h yaohong 1 3s
使用describe来查看ServiceAccount。
$ kubectl describe sa yaohong Name: yaohong Namespace: default Labels: <none> Annotations: <none> Image pull secrets: <none> Mountable secrets: yaohong-token-qhbxn //如果强制使用可挂载秘钥。那么使用这个serviceaccount的pod只能挂载这个秘钥 Tokens: yaohong-token-qhbxn Events: <none>
查看该token,
$ kubectl describe secret yaohong-token-qhbxn
Name: yaohong-token-qhbxn
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: yaohong
kubernetes.io/service-account.uid: a3d0d2fe-bb43-11e9-ac1e-005056870b4d
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1342 bytes
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6Inlhb2hvbmctdG9rZW4tcWhieG4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoieWFvaG9uZyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImEzZDBkMmZlLWJiNDMtMTFlOS1hYzFlLTAwNTA1Njg3MGI0ZCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0Onlhb2hvbmcifQ.BwmbZKoM95hTr39BuZhinRT_vHF-typH4anjkL0HQxdVZEt_eie5TjUECV9UbLRRYIqYamkSxmyYapV150AQh-PvdcLYPmwKQLJDe1-7VC4mO2IuVdMCI_BnZFQBJobRK9EdPdbZ9uxc9l0RL5I5WyWoIjiwbrQvtCUEIkjT_99_NngdrIr7QD9S5SxHurgE3HQbmzC6ItU911LjmxtSvBqS5NApJoJaztDv0cHKvlT67ZZbverJaStQdxr4yiRbpSycRNArHy-UZKbNQXuzaZczSjVouo5A5hzgSHEBBJkQpQ6Tb-Ko5XGjjCgV_b9uQvhmgdPAus8GdFTTFAbCBw
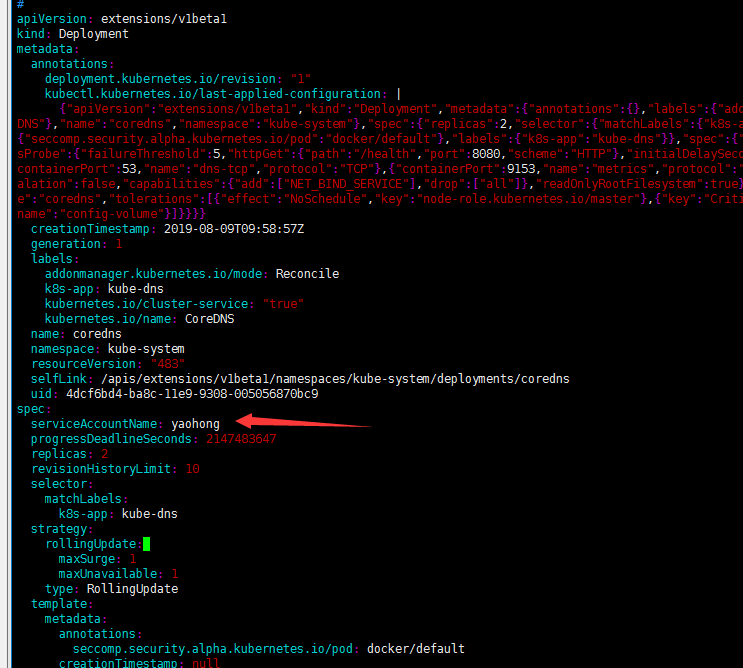
12.1.4将ServiceAccount分配给pod
在pod中定义的spec.serviceAccountName字段上设置,此字段必须在pod创建时设置后续不能被修改。
自定义pod的ServiceAccount的方法如下图
12.2通过基于角色的权限控制加强集群安全
12.2.1.介绍RBAC授权插件
RBAC授权插件将用户角色作为决定用户能否执行操作的关机因素。
12.2.2介绍RBAC授权资源
RBAC授权规则通过四种资源来进行配置的,他们可以分为两组:
Role和ClusterRole,他们决定资源上可执行哪些动词。
RoleBinding和ClusterRoleBinding,他们将上述角色绑定到特定的用户,组或者ServiceAccounts上。
Role和RoleBinding是namespace级别资源
ClusterRole和ClusterRoleBinding是集群级别资源
12.2.3使用Role和RoleBinding
Role资源定义了哪些操作可以在哪些资源上执行,
创建Role
service-reader.yml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: kube-system name: service-reader rules: - apiGroups: [""] verbs: ["get", "list"] resources: ["services"]
在kube-system中创建Role
#kubectl -n kube-system create -f service-reader.yml
查看该namespace下的role
$ kubectl -n kube-system get role NAME AGE extension-apiserver-authentication-reader 41h kube-state-metrics-resizer 41h service-reader 2m17s system::leader-locking-kube-controller-manager 41h system::leader-locking-kube-scheduler 41h system:controller:bootstrap-signer 41h system:controller:cloud-provider 41h system:controller:token-cleaner 41h
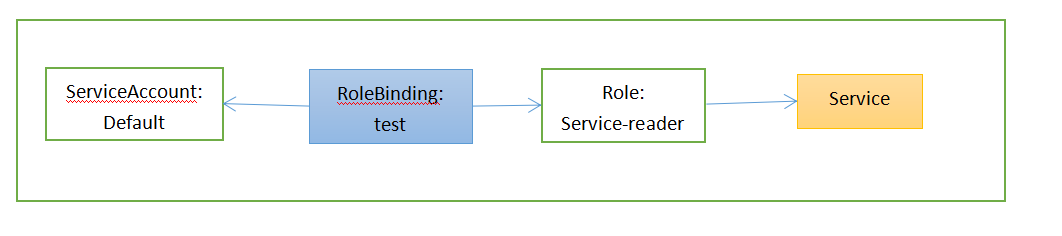
绑定角色到ServiceAccount
将service-reader角色绑定到default ServiceAccount
$ kubectl create rolebinding test --role=service-reader rolebinding.rbac.authorization.k8s.io/test created
$ kubectl get rolebinding test -o yaml apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: creationTimestamp: 2019-08-11T03:40:51Z name: test namespace: default resourceVersion: "239323" selfLink: /apis/rbac.authorization.k8s.io/v1/namespaces/default/rolebindings/test uid: d0aff243-bbe9-11e9-ac1e-005056870b4d roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: service-reader
12.2.4使用ClusterRole和ClusterRoleBinding
查看集群ClusterRole
# kubectl get clusterrole NAME AGE admin 42h cluster-admin 42h edit 42h flannel 42h kube-state-metrics 42h system:aggregate-to-admin 42h ...
创建ClusterRole
kubectl create clusterrole flannel --verb=get,list -n kube-system
查看yaml文件
# kubectl get clusterrole flannel -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"rbac.authorization.k8s.io/v1","kind":"ClusterRole","metadata":{"annotations":{},"name":"flannel"},"rules":[{"apiGroups":[""],"resources":["pods"],"verbs":["get"]},{"apiGroups":[""],"resources":["nodes"],"verbs":["list","watch"]},{"apiGroups":[""],"resources":["nodes/status"],"verbs":["patch"]}]}
creationTimestamp: 2019-08-09T09:58:42Z
name: flannel
resourceVersion: "360"
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/flannel
uid: 45100f6f-ba8c-11e9-8f57-005056870608
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
创建clusterRoleBinding
$ kubectl create clusterrolebinding cluster-tetst --clusterrole=pv-reader --serviceaccount=kuebsystem:yaohong clusterrolebinding.rbac.authorization.k8s.io/cluster-tetst created

12.2.5了解默认的ClusterRole和ClusterRoleBinding
如下所示使用kubectl get clusterroles和kubectl get clusterrolesbinding可以获取k8s默认资源。
用edit ClusterRole允许对资源进行修改
用admin ClusterRole赋予一个命名空间全部的权限
$ kubectl get clusterroles NAME AGE admin 44h cluster-admin 44h edit 44h flannel 44h kube-state-metrics 44h system:aggregate-to-admin 44h system:aggregate-to-edit 44h system:aggregate-to-view 44h system:auth-delegator 44h system:aws-cloud-provider 44h system:basic-user 44h system:certificates.k8s.io:certificatesigningrequests:nodeclient 44h system:certificates.k8s.io:certificatesigningrequests:selfnodeclient 44h system:controller:attachdetach-controller 44h system:controller:certificate-controller 44h system:controller:clusterrole-aggregation-controller 44h 。。。
$ kubectl get clusterrolebindings NAME AGE clust-tetst 17m cluster-admin 44h cluster-tetst 13m flannel 44h kube-state-metrics 44h kubelet-bootstrap 44h system:aws-cloud-provider 44h system:basic-user 44h system:controller:attachdetach-controller 44h system:controller:certificate-controller 44h 。。。
13.Kubernetes-保障集群内节点和网络安全
13.1.在pod中使用宿主节点的Linux命名空间
13.1.1.在pod中使用宿主节点的网络命名空间
在pod的yaml文件中就设置spec.hostNetwork: true
这个时候pod使用宿主机的网络,如果设置了端口,则使用宿主机的端口。
apiVersion: v1
kind: pod
metadata:
name: pod-host-yaohong
spec:
hostNetwork: true //使用宿主节点的网络命名空间
containers:
- image: luksa/kubia
command: ["/bin/sleep", "9999"]
13.1.2.绑定宿主节点上的端口而不使用宿主节点的网络命名空间
在pod的yaml文件中就设置spec.containers.ports字段来设置
在ports字段中可以使用
containerPorts设置通过pod 的ip访问的端口
container.hostPort设置通过所在节点的端口访问
apiVersion: v1
kind: pod
metadata:
name: kubia-hostport-yaohong
spec:
containers:
- image: luksa/kubia
- name: kubia
ports:
- containerport: 8080 //该容器通过pod IP访问该端口
hostport: 9000 //该容器可以通过它所在节点9000端口访问
protocol: Tcp
13.1.3.使用宿主节点的PID与IPC
在linux下的多个进程间的通信机制叫做IPC(Inter-Process Communication),它是多个进程之间相互沟通的一种方法。
apiVersion: v1
kind: pod
metadata:
name: pod-with-host-pid-and-ipc-yaohong
spec:
hostPID: true //你希望这个pod使用宿主节点的PID命名空间
hostIPC: true //你希望pod使用宿主节点的IPC命名空间
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
13.2.配置节点的安全上下文
13.2.1.使用指定用户运行容器
查看某个pod运行的用户
$ kubectl -n kube-system exec coredns-7b8dbb87dd-6ll7z id uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel),11(floppy),20(dialout),26(tape),27(video)
容器的运行用户再DockerFile中指定,如果没有指定则为root
指定pod的运行的用户方法如下
apiVersion: v1
kind: pod
metadata:
name: pod-as-user
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
runAsUser: 405 //你需要指定的用户ID,而不是用户名
13.2.2.阻止容器以root用户运行
apiVersion: v1
kind: pod
metadata:
name: pod-as-user
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
runAsNonRoot: true //这个容器只允许以非root用户运行
13.2.3.使用特权模式运行pod
为了获得宿主机内核完整的权限,该pod需要在特权模式下运行。需要添加privileged参数为true。
apiVersion: v1
kind: pod
metadata:
name: pod-as-privileged
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
privileged: true //这个容器将在特权模式下运行
13.2.4.为容器单独添加内核功能
apiVersion: v1
kind: pod
metadata:
name: pod-as-capability
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
capabilities: //该参数用于pod添加或者禁用某项内核功能
add:
- SYS_TIME //添加修改系统时间参数
13.2.5.在容器中禁止使用内核功能
apiVersion: v1
kind: pod
metadata:
name: pod-as-capability
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
capabilities: //该参数用于pod添加或者禁用某项内核功能
drop:
- CHOWN //禁用容器修改文件的所有者
13.2.6.阻止对容器根文件系统的写入
apiVersion: v1
kind: pod
metadata:
name: pod-with-readonly-filesystem
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "99999"]
securityContext:
readyOnlyFilesystem: true //这个容器的根文件系统不允许写入
volumeMounts:
- name: my-volume
mountPath: /volume //volume写入是允许的,因为这个目录挂载一个存储卷
readOnly: false
13.3.限制pod使用安全相关的特性
13.3.1.PodSecurityPolicy资源介绍
PodSecurityPolicy是一种集群级别(无命名空间)的资源,它定义了用户能否在pod中使用各种安全相关的特性。
13.3.2.了解runAsUser、fsGroups和supplementalGroup策略
runAsUser:
runle: MustRunAs
ranges:
- min: 2 //添加一个max=min的range,来指定一个ID为2的user
max: 2
fsGroup:
rule: MustRunAs
ranges:
- min: 2
max: 10 //添加多个区间id的限制,为2-10 或者20-30
- min: 20
max: 30
supplementalGroups:
rule: MustRunAs
ranges:
- min: 2
max: 10
- min: 20
max: 30
13.3.3.配置允许、默认添加、禁止使用的内核功能
三个字段会影响容器的使用
apiVersion: v1 kind: PodSecurityPolicy spec: allowedCapabilities: - SYS_TIME //允许容器添加SYS_time功能 defaultAddCapabilities: - CHOWN //为每个容器自动添加CHOWN功能 requiredDropCapabilities: - SYS_ADMIN //要求容器禁用SYS_ADMIN和SYS_MODULE功能
13.4.隔离pod网络
13.4.1.在一个命名空间中使用网络隔离
podSelector进行对一个命名空间下的pod进行隔离
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector: //这个策略确保了对具有app=databases标签的pod的访问安全性
matchLabels:
app: database
ingress:
- from:
- podSelector: //它只允许来自具有app=webserver标签的pod的访问
matchLabels:
app: webserver
ports:
- port: 5432 //允许对这个端口的访问
13.4.2.在 不同的kubernetes命名空间之间进行网络隔离
namespaceSelector进行对不同命名空间间进行网络隔离
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector: //这个策略确保了对具有app=databases标签的pod的访问安全性
matchLabels:
app: database
ingress:
- from:
- namespaceSelector: //只允许tenant: manning标签的命名空间中运行的pod进行互相访问
matchLabels:
tenant: manning
ports:
- port: 5432 //允许对这个端口的访问
13.4.3.使用CIDR网络隔离
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24 //指明允许访问的ip段
13.4.4.限制pod对外访问流量
使用egress进行限制
spec:
podSelector: //这个策略确保了对具有app=databases标签的pod的访问安全性
matchLabels:
app: database
egress: //限制pod的出网流量
- to:
- podSelector:
matchLables: //database的pod只能与有app: webserver的pod进行通信
app: webserver
来源:https://www.cnblogs.com/yaohong/p/11361784.html