可视化随机森林的特征重要性
# 查看随机森林的特征重要性
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 创建分类器对象
randomforest = RandomForestClassifier(random_state=0)
# 训练模型
model = randomforest.fit(features, target)
# 计算特征重要性
importances = model.feature_importances_
print("model.feature_importances_: {}".format(importances))
# print(importances)
# 对特征重要性进行排序
indices = np.argsort(importances)[::-1]
print(indices)
# 获取特征名字
names = [iris.feature_names[i] for i in indices]
# 创建图
plt.figure()
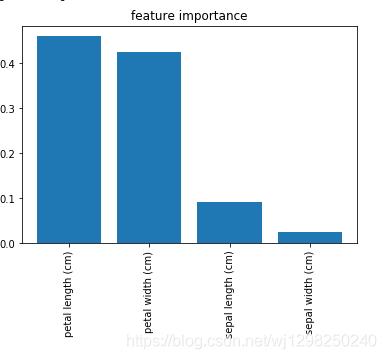
plt.title("feature importance")
# features.shape[1] 数组的长度
plt.bar(range(features.shape[1]), importances[indices])
plt.xticks(range(features.shape[1]), names, rotation=90)
plt.show()
model.feature_importances_: [0.09090795 0.02453104 0.46044474 0.42411627]
[2 3 0 1]
来源:CSDN
作者:御剑归一
链接:https://blog.csdn.net/wj1298250240/article/details/103654664