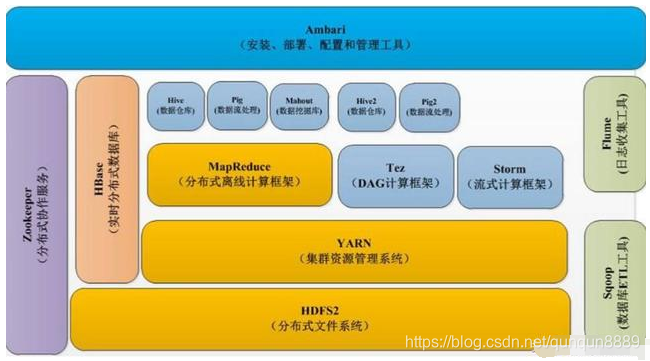
除非你过去几年一直隐居,远离这个计算机的世界,否则你不可能没有听过Hadoop,全名Apache Hadoop,是一个在通用低成本的硬件上处理存储和大规模并行计算的一个开源框架,Hadoop本质的12点介绍,具体如下:
1.hadoop是由多个产品组成的。
人们在谈论Hadoop的时候,常常把它当做单一产品来看待,但事实上它由多个不同的产品共同组成。
Russom说:“Hadoop是一系列开源产品的组合,这些产品都是Apache软件基金会的项目。”
一提到Hadoop,人们往往将其与MapReduce放在一起,但其实HDFS和MapReduce一样,也是Hadoop的基础。
2.Apache Hadoop是开源技术,但专有厂商也提供Hadoop产品。
由于Hadoop属于开源技术,可免费下载,所以IBM、Cloudera和EMC Greenplum等厂商都可以推出他们各自的Hadoop特别发行版本。
这些特别发行版本一般都会有一些附加特性,比如高级管理工具及相关的支持维护服务。有人可能对此嗤之以鼻:既然开源社区是免费的,那么我们为什么还要为它的服务付费?Russom解释道,这些版本的HDFS对一些IT部门更合适,特别是企业IT系统已经相对成熟的用户。
3.Hadoop是一个生态系统,而非一个产品。
Hadoop是由开源社区和各个厂商共同开发和推动的。具体说来,厂商的Hadoop的产品其结构化和关系性更强一些。
Russom说:“一直以来报表平台、数据集成平台在为更新的平台提供各种各样的接口,Hadoop当然也不例外。”
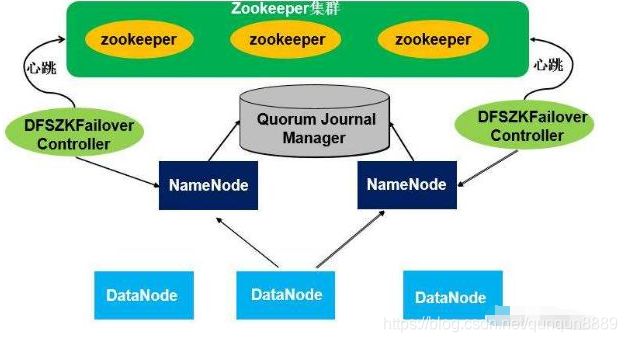
4.HDFS是文件系统,而不是数据库管理系统。
Russom最无法忍受的,就是人们常常把二者混为一谈。能够对数据集进行管理是数据管理系统很重要的特性之一,这一点HDFS是不具备的。
数据库管理系统中,我们通过查询索引可以实现对数据的随机访问,它往往处理的是结构化的数据,而在Hadoop中不会处理这样的数据类型。
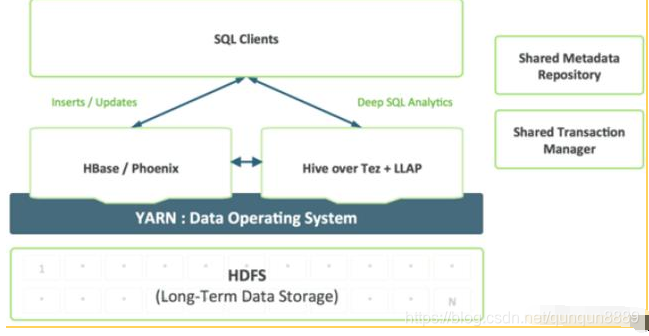
5.Hive与SQL类似,却非标准SQL。
传统获取数据的业务工具大多都是基于SQL的,这比较让人头疼,因为Hadoop使用的是一种类似SQL但不是SQL的语言——Apache Hive和HiveQL。
Russom说:“我常听到别人说,‘Hive学起来非常简单,直接学Hive就行。’但这并不能解决与SQL工具兼容的根本问题。”
Russom认为兼容性只是一个短时间问题,但却阻碍了Hadoop的普及。
6.Hadoop与MapReduce相互关联,但不相互依赖。
MapReduce早在HDFS出现以前就由Google开发推出。除此之外,诸如MapR一类的厂商一直在宣传MapReduce功能的多样性,无需HDFS支持。
尽管如此,Russom却认为它们具有很好的互补性。HDFS的大部分价值都体现在可层叠到分布式文件系统的工具上。
7.MapReduce提供的是对分析的控制,而不是分析本身。
MapReduce是一种通用执行驱动引擎,可协助分析。它能读取手写代码数据,对其进行并行自动处理,并将结果映射到单一集合中。然而我们需要明确一点,MapReduce自身并不进行分析工作。
Russom说:“MapReduce可以看作是升级版的MPP架构。你无论怎样编写代码,它都可以把它们并行化,非常强大。”
8.Hadoop的意义不仅仅在于数据量,更在于数据的多样化。
有人把Hadoop归类为海量数据处理技术,但是Hadoop真正的价值却是对多样化数据处理的能力。
Russom说:“Hadoop的处理范围为大多数数据仓库所不及,比如针对半结构化与完全非结构化的数据。”
9.Hadoop是数据仓库的补充,不是数据仓库的替代品。
Hadoop对多样化数据类型进行管理的能力使得“数据仓库将死”的言论四起,然而Russom却进行了反驳。
他反问道:“在IT领域,人们多久替换一项技术?几乎从来没有过。”
数据仓库在其领域中的性能仍然出色,已经为大家精心准备了大数据的系统学习资料,从Linux-Hadoop-spark-......,需要的小伙伴可以点击Hadoop可起到对数据仓库技术进行补充的作用。数据仓库和其他系统的架构越来越多地开始向分布式靠拢,Hadoop在这里将发挥其作用。
10.Hadoop不仅仅是Web分析。
Hadoop在互联网中的运用非常普遍,Russom认为Hadoop普及趋势的部分原因是因为它可以处理更多类型的分析。
Russom举了铁路公司、机器人和零售业的例子。铁路公司可使用传感器对异常高温的轨道车辆进行探测,以阻止事故的发生。
Russom尽管十分看好Hadoop的前景,但同时认为它的普及还需要数年时间。
11.大数据不一定非Hadoop不可。
别看现在大数据和Hadoop已经密不可分,Russom却认为Hadoop并不是大数据的“唯一”。他提到了许多其他厂商的产品,如Teradata、Sybase IQ(被SAP收购)和Vertica(被HP收购)等。
除此之外,在Hadoop没有诞生之时,一些企业就已经开始研究大数据了。例如,电信行业多年以前就有呼叫明细记录。
12.Hadoop不是“免费午餐”。
虽然Hadoop属于开源技术,但是软件的安装部署是需要花钱的。Russom称,由于Hadoop在管理工具与支持服务方面的不足,企业在使用过程中很容易产生额外费用。另外,由于它没有优化程序,我们只能请专业人士在运行环境中手写输入代码,而这些专业人士的薪酬价码都不菲。
更不用提部署Hadoop集群的硬件和相关配置的成本。
他说:“千万别以为Hadoop是免费的或者很便宜,它背后的隐性开销你是一下子看不到的。”
数据时代的未来,一定离不开Hadoop,对人工智能和大数据感兴趣的朋友,可以关注多智时代,及时查阅相关的基础知识,如有疑问,请在留言区,加以斧正。
来源:CSDN
作者:qunqun8889
链接:https://blog.csdn.net/qunqun8889/article/details/103643932