本论文要解决的问题是使用条件生成对抗网络(cGAN)生成合成图像。具体来说,本文要完成的具体任务是使用一个分割掩码控制所生成的图像的布局,该分割掩码的每个语义区域都具有标签,而网络可以根据这些标签为每个区域「添加」具有真实感的风格。
尽管之前已经有一些针对该任务的框架了,但当前最佳的架构是 SPADE(也称为 GauGAN)。因此,本论文的研究也是以 SPADE 为起点的。
具体来说,本文针对原始 SPADE 的两个缺陷提出了新的改进方案。
第一,SPADE 仅使用一种风格代码来控制一张图像的整体风格,这不足以实现高质量的合成或对细节的控制。此外,SPADE 不允许在分割掩码的不同区域使用不同风格的输入图像。因此,第一个改进方案是实现对每个区域的单独控制,即新提出的架构每个区域(即每个区域实例)都能使用一种风格图像作为输入。
第二,研究者认为仅在网络的开始处注入风格信息不是个很好的选择。针对这一问题,本文提出了一种新的归一化构建模块 SEAN(semantic region-adaptive normalization),其可以使用风格输入图像为每个语义区域创建空间上不同的归一化参数。本研究有一个很重要的方面,即空间上不同的归一化参数取决于分割掩码本身以及风格输入图像。
本文在几个高难度的数据集(CelebAMaskHQ、CityScapes、ADE20K 和研究者新建的 Facades 数据集)上对新提出的方法进行了广泛的实验评估。定量实验方面,研究者基于 FID、PSNR、RMSE 和分割性能等多种指标对新方法进行了评估;定性实验方面,研究者展示了可通过视觉观察进行评估的样本。
SEAN 的优势
首先,SEAN 能提升条件 GAN 合成的图像的质量;
其次,SEAN 能改善每个区域的风格编码,使得重建的图像可以在 PSNR 和视觉观察指标上与输入的风格图像更相似;
最后,SEAN 允许用户为每个语义区域选择一种不同风格的输入图像。这能使图像编辑得到质量更高的结果,并提供比当前最佳方法更好的控制力。
给定一张输入风格图像及其对应的分割掩码,下面将介绍:1)如何根据掩码注入每个区域的风格;2)如何使用注入后的每区域风格代码合成具有照片一样的真实感的图像。
如何对风格进行编码?
每个区域风格编码器(Per-Region Style Encoder)。为了提取每个区域的风格,本文提出了一种全新的风格编码器网络,其可以同时从输入图像的每个语义区域注入对应的风格代码(见下图 (A) 中的子网络风格编码器)。风格编码器的输出是一个 512×s 维的风格矩阵 ST,其中 s 是输入图像中语义区域的数量。该矩阵的每一列都对应于一个语义区域的风格代码。
新提出的每个区域风格编码器使用了一种「瓶颈」结构来移除输入图像中与风格无关的信息。结合「风格应当独立于语义区域的形状」的先验知识,网络可将网络模块 TConv-Layers 生成的中间特征图(512 个通道)传递通过一个区域上的平均池化层并将它们约减成 512 维向量的集合。
如何控制风格?
使用每区域风格代码和分割掩码作为输入,本文提出了一种新的条件归一化技术 SEAN,即语义区域自适应归一化(Semantic Region-Adaptive Normalization)。SEAN 可为照片级真实感的图像合成提供深入细节的控制。类似于已有的归一化技术,SEAN 的工作方式也是调节生成器激活的尺度和偏置量。
但不同于所有的已有方法,SEAN 学习到的调节参数同时取决于风格代码和分割掩码。在 SEAN 模块(下图 3)中,首先会根据输入分割掩码,通过向对应的语义区域广播风格代码来生成一个风格映射图(style map)。
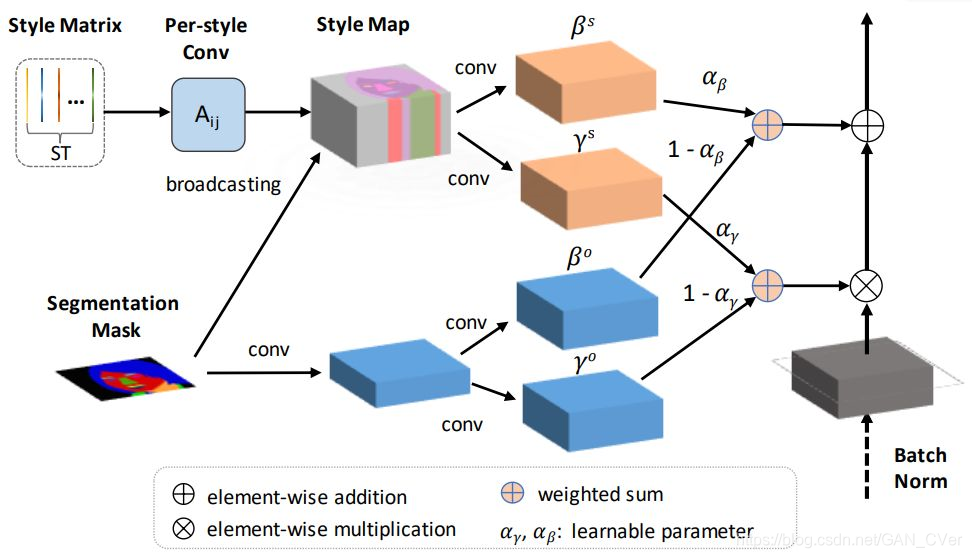
图 3:SEAN 归一化。输入是风格矩阵 ST 和分割掩码 M。在上部分,ST 中的风格代码会进行每风格卷积,然后根据 M 将其广播至它们对应的区域,从而得到风格映射图。下部分(浅蓝色层)以与 SPADE 类似的方式仅使用区域信息创建每像素的归一化。
实验设置
网络架构
下图 4(A) 展示了生成器网络的概况,这是基于 SPADE 构建的。类似于 SPADE,这个生成器由多个 SEAN ResNet 模块(SEAN ResBlk)与上采样层构成。图 4(B) 展示了 SEAN ResBlk 的结构,其由三个卷积层构成,而这三个卷积层的尺度和偏置量分别由三个 SEAN 模块调节。每个 SEAN 模块有两个输入:一个每区域风格代码集合 ST 和一个语义掩码 M。
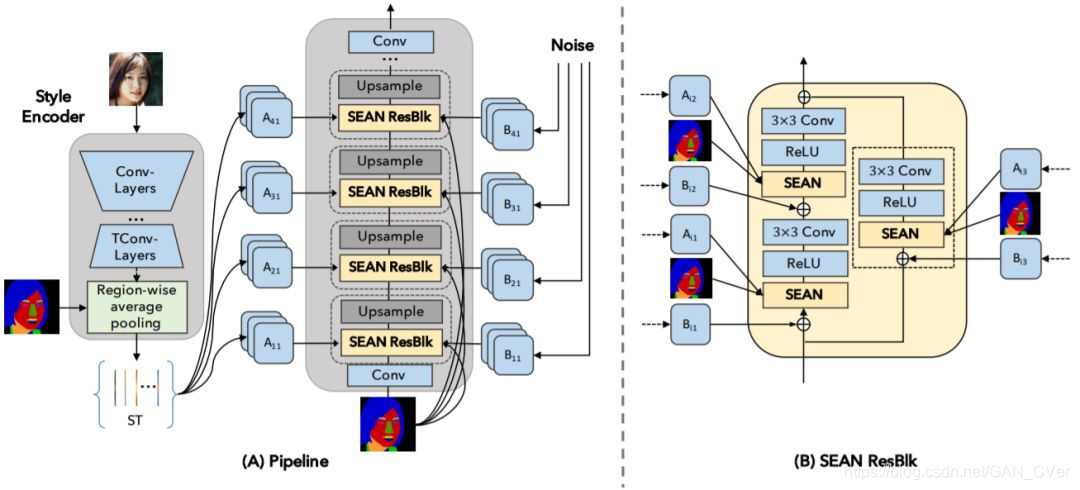
图 4:SEAN 生成器。(A)在左图中,风格编码器以一张图像为输入,输出一个风格矩阵 ST。右图的生成器由交错的 SEAN ResBlock 和 Upsample 层构成。(B)SEAN ResBlock 的详细情况。
注意,这两个输入在一开始就会得到调整:输入分割掩码会被下采样到层中特征映射图同样的高度和宽度;来自 ST 的输入风格代码会被使用一个 1×1 的卷积层 A_ij 按每个区域进行变换。研究者观察到,初始的变换是该架构中不可分割的组分,因为它们可根据每个神经网络层的不同用途对风格代码进行变换。
训练和推理
本文将训练过程构造成了一个图像重建问题。也就是说,风格编码器的训练目标是根据对应的分割掩码注入输入图像的每区域风格代码。生成器网络的训练目标是使用提取出的每区域风格代码和对应的分割掩码作为输入,重建输入图像。遵照 SPADE 和 Pix2PixHD 的度量方法,本文也通过一个总体损失函数来衡量输入图像和重建图像之间的差异。这个总体损失函数由三个损失项构成:条件对抗损失、特征匹配损失、感知损失。有关这些损失的详情请参阅原论文。
推理过程则是以任意分割掩码为掩码输入,并通过为每个语义区域选择一个不同的 512 维风格代码为风格输入来实现对每个区域的风格控制。这能实现多种不同的高质量的图像合成应用。
结果
下面讨论对新提出的框架的定量和定性研究结果。
该框架和 SPADE 一样在生成器和判别器中使用了 Spectral Norm。生成器中的 SEAN 还会执行额外的归一化。生成器和判别器的学习率分别设为 0.0001 和 0.0004。优化器则选择了 β_1 = 0, β_2 = 0.999 的 ADAM。所有的实验都是在 4 块 Tesla v100 GPU 上训练的。为了取得更好的表现,研究者在 SEAN 归一化模块中使用了批归一化的一种同步化版本。
实验中使用了这些数据集:1)CelebAMask-HQ,其中包含 CelebAHQ 人脸图像数据集的 30000 个分割掩码,分为 19 种不同的区域类别;2)ADE20K,包含 22210 张标记了 150 种不同区域标签的图像;3)Cityscapes,包含 3500 张标记了 35 种不同区域标签的图像;4)Facades 数据集,使用了从谷歌街景收集的 30000 张建筑物正面图像。
结果比较使用了以下已经确立的指标:1)由平均交并比(mIoU)和像素准确度(accu)衡量的分割准确度;2)FID;3)峰值信噪比(PSNR);4)结构相似度(SSIM);5)均方根误差(RMSE)。
定量比较
为了与 SPADE 进行公平的比较,本文报告了当仅使用一张风格图像时的重建表现。研究者为每个数据集都训练了一个网络,并在下表 1 和表 2 中给出了结果。

表 1:重建质量的定量比较。在所有数据集上,新提出的方法在 SSIM、RMSE、PSNR 这些相似度指标上都优于当前领先的方法。SSIM 和 PSNR 指标是越高越好。RMSE 指标是越低越好。
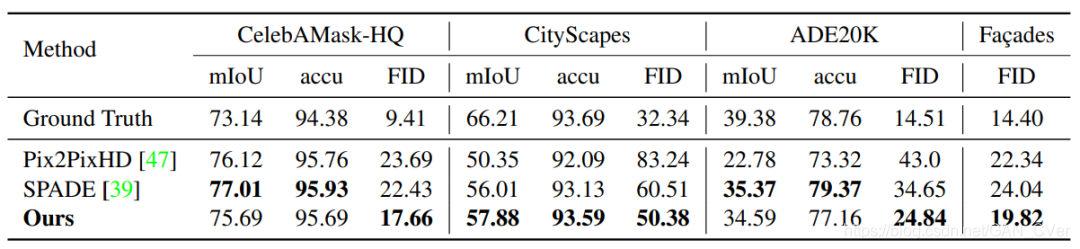
表 2:由 mIoU 和 accu 衡量的语义分割表现以及由 FID 衡量的生成表现的定量比较。在所有数据集上,新提出的方法在 FID 指标上都更优。
定性结果
下图 6 展示了在四个数据集上得到的图像示例。可以明显看到新方法所得结果的质量更好。
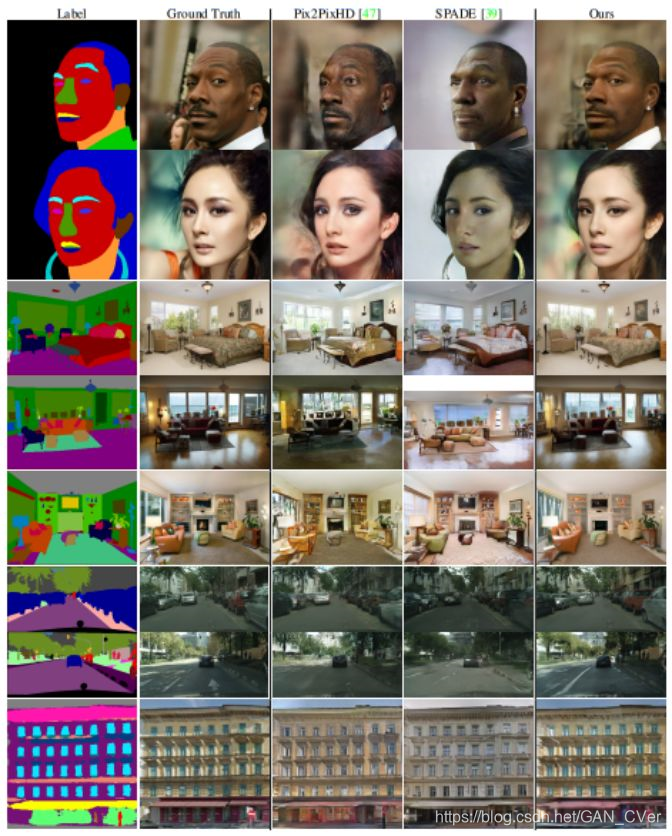
图 6:在 CelebAMask-HQ、ADE20K、CityScapes 和 Fa ç ades 数据集上的语义图像合成结果的比较。比较的方法有 Pix2PixHD、SPADE 和新提出的方法。
研究者也实验了使用新提出的每区域风格编码来编辑图像。下图 1 和图 2 是使用每区域风格控制的迭代式图像编辑结果,图 5 是风格插值的结果,图 7 是风格交叉的结果。

图 1:通过风格图像和分割掩码控制的人脸图像编辑。(a)源图像;(b)源图像的重建结果,其中右下小图是分割掩码。(c-f)四种不同的编辑结果,第一行的图像提供了对应的风格信息,右下小图给出了分割掩码中被编辑的部分。

图 2:在 ADE20K 数据集上的编辑序列。(a)源图像;(b)源图像的重建结果。(c-f)使用上一行图像的风格进行编辑的结果。

图 5:风格插值。使用源图像的掩码,根据两张不同的风格图像(Style1 和 Style2)进行重建。其中给出了对每区域风格代码的插值结果。

图 7:风格交叉。除了风格插值(最下一行),还可以通过为每个 ResBlk 选择不同的风格来执行交叉。图中的上面两行给出了两种不同的过渡。每张图上方的蓝色和橙色色条说明了 6 个 ResBlk 所用的风格。
SEAN 生成器的变体(控制变量实验)
下表 3 给出了新提出架构的不同变体以及之前的研究在 CelebAMask-HQ 数据集上的结果比较。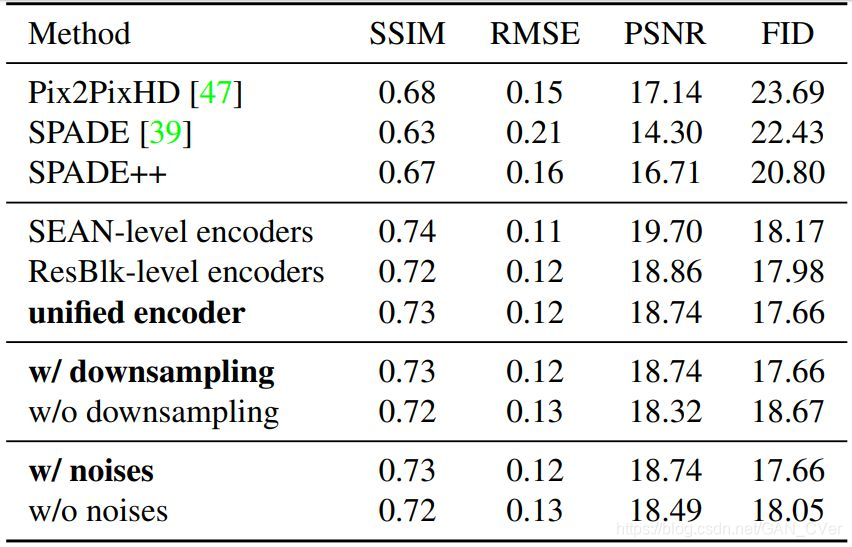
表 3:在 CelebAMask-HQ 数据集上的控制变量实验。
来源:CSDN
作者:Sanven?
链接:https://blog.csdn.net/GAN_CVer/article/details/103574300