【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>> 
这次我以爬新浪微博为例,这个过程太纠结了,参考了好多大神的帖子,不过还是遗留了很多问题,我们慢慢来看,希望大神帮于指正,我的方法暂时来说还是比较挫的
登陆问题
爬新浪微博首先要登陆,之前爬的妹纸网站,由于不用登陆,所以没这一步,但是爬新浪微博我们必须要先登录,但是要涉及到一个问题,那就是验证码,验证码从我现在百度到的,和自己的理解,感觉暂时还是不能解决的,除非手工输入,因为本身验证码就是防止恶意登陆,防爬虫的,所以建议想试试的朋友用暂时用不输入验证码的账号试试(关于验证码,期盼大神可以给些提示)
下面是demo代码
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage("http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)");
HtmlInput username = (HtmlInput) htmlPage.getElementsByName("username").get(0);
HtmlInput password = (HtmlInput) htmlPage.getElementsByName("password").get(0);
HtmlInput btn = htmlPage.getFirstByXPath(".//*[@id='vForm']/div[3]/ul/li[6]/div[2]/input");
username.setValueAttribute("****");
password.setValueAttribute("****");
btn.click();
} catch (IOException e) {
e.printStackTrace();
}代码和之前的差不多太多,多了一些参数设置,通过方法命名就应该可以大体知道啥含义了,我就不过多解释了,但是可能有人会问为什么webClient.getPage的url不是www.weibo.com 呢?因为若直接get那个www.weibo.com,得到的html,debug看,全是一些js代码,没有任何登陆模块而言,可见新浪的登陆模块多半是脚本画出来的,所以不好,而这个网站,我开始是参考以前一个大神写的 http://blog.csdn.net/bob007/article/details/29589059
这个网站打开其实是新浪通行证的登陆页面
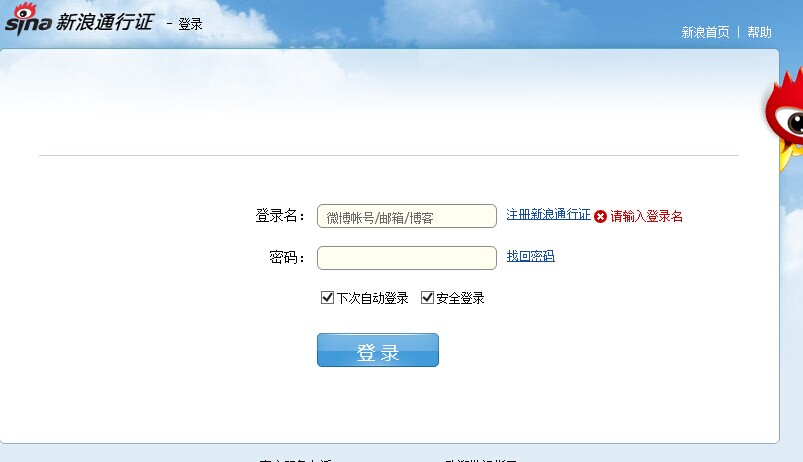
开始我想为啥是这个界面,所以后面用httpwatch看了一下通过www.weibo.com登陆的时候整个请求过程
可以看到,在输入完密码和账号之后,我们post的地址正是这个地址,也就是说,新浪微博的登陆内部应该是这样的
1. 请求www.weibo.com 得到登陆页面,输入完用户密码
2. 提交请求到新浪通行证,然后点击登陆,完成登陆操作
我们平常用的微博账号,对于新浪而言,其实是新浪通行证的一种,这样也就好理解了

我们再回到htmlunit上,我们获取了新浪通行证的登陆页面后(htmlpage对象),如何获取到具体的用户名和密码的控件呢,这个大家可以自己debug一下就很清楚了,然后用htmlpage.asXml()这个方法解读一下这个页面的各个元素,看一下就知道了
而获取登陆按钮的方式也是直接参考之前那个大神里的做法,用到了api是getFirstByXPath这个方法,这个里的XPath语法就是w3c标准语法,可以参考http://www.w3school.com.cn/xpath/学习一下,有了这个语法对于页面的任何节点,只要稍加分析,基本都可以拿到的
之后就简单啦,获取到了用户名,密码输入框,还有提交按钮,我们最后三行代码就是把用户名和密码set进去,然后点击提交按钮,这就完成了登陆操作,是不是感觉到这个代码逻辑就是和页面操作一样嘛,这也体现了模拟浏览器的描述了
因为你现在已经登陆了,所以现在你就可以浏览你的主页和看你关注的人的微博啦
但是大家这里要注意一个很重要的问题,就是微博的展示方式,大家实际操作也可以感觉的到,展示微博时是这么一个过程
1. 展示一部分微博
2. 滚动条向下滚动,刷出一部分新的微博
3. 滚动几次后,最后页面底部出现分页控件
4. 点击下一页,又展示一部分微博,重复2-4的过程了
所以我开始就遇到这样的问题,我开始用下面的代码请求我的主页,并且打印出了我的微博,可惜只有15条,因为我的滚动条没有下拉,所以没有请求到更多的微博
page3 = webClient.getPage("http://weibo.com/5622296819/profile?topnav=1&wvr=6");
List<HtmlDivision> htmlDivisions = (List<HtmlDivision>) page4.getByXPath("//div[@class='WB_text W_f14']");
for(i = 0; i < htmlDivisions.size(); i++) {
System.out.println("第" + (counter++) + "条微博: "
+ htmlDivisions.get(i).getTextContent().trim());
}所以我就开始了到处百度如何用htmlunit模拟滚动条滚动,找了好多,模拟这个下拉这个动作基本看没法搞(大家可可以看看这个可怜的兄弟,14年就遇到这个问题了,他最后两段说出了我的心声 http://stackoverflow.com/questions/23491638/is-there-a-way-to-trigger-scroll-event-with-htmlunit-or-is-it-not-possible-at-al )
不过有人提出可以模拟滚动条下拉这个请求,而不是模拟这个动作,比如这个大神http://blog.csdn.net/zhoujianfeng3/article/details/21395223 但是代码还是不全,我试着尝试,而且他模拟的url是14年的,不报希望的试了一下,果然是不行的,但是他的想法还是给我很大的启发,我参照他的方式,通过httpwatch看了一下,现在的滚动下拉请求基本是这个样子(这是我关注的一个账号的微博,因为微博比较多,可以用来练习抓)
经过几次分析,注意其中的这两个参数,page=1和pagebar=0,这个page就是当前这个分页,而这个pagebar是滚动的那个序列,也就是继续滚下去的话,page=1不变,pagebar要变为1,若分页的时候,page要变为2(变为相应页数),而pagebar又要从0开始,按照之前说的那个微博展示的过程理解一下就不难了
但是注意上面这个url是滚动的url,而点击分页又是另一个,大家可以自己用httpwatch看一下就知道了,这里就不赘述
说完分析思路,再说说做法
这里滚动下拉的请求,返回的是json数据,不是一个html页面,所以就不能再用webClient.getPage了,大家要注意一下,而当前从我百度的来看,htmlunit还不能很好的解析json,所以这里参考我之前说的大神的思路,用到了另一个爬虫工具JSoup,来解析,demo代码如下
WebRequest requestOne = new WebRequest(new URL(url), HttpMethod.GET);
WebResponse jsonOne = webClient.loadWebResponse(requestOne);
JSONObject jsonObj = JSONObject.fromObject(jsonOne.getContentAsString());
String data = (String) jsonObj.get("data");
Document doc = Jsoup.parse(data);
Elements elementsTwo = doc.select("div[class=WB_text W_f14]");
for (int i = 0; i < elementsTwo.size(); i++) {
Element element = elementsTwo.get(i);
System.out.println("第" + (counter++) + "条微博: "
+ elementsTwo.get(i).text());
}url就是分页的url,这样用HtmlUnit来构建一个Web的请求,然后获取到json返回的结果,转换为JSONObject对象,再用JSoup来解析json的字符转,这里的doc.select后面参数的语法是CSSQuery语法,和Xpath差不太多,大家随便可以百度一下,也是比较好理解的,最后打印一下所有的微博就可以了
差点忘了,这里还需要增加新的依赖
<!-- json begin -->
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<classifier>jdk15</classifier>
<version>2.2</version>
</dependency>
<!-- json end -->
<!-- jsoup begin -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.6.3</version>
</dependency>
<!-- jsoup end --> 最后我是把这个微博账号里的微博5000多条微博,直接写到一个文件里了,算是完成了最基本的了,当然我知道这也只是爬虫最基本的小demo,后面老大没有给我分配其他任务的时候,我会再继续专研哈,希望大神们多指正
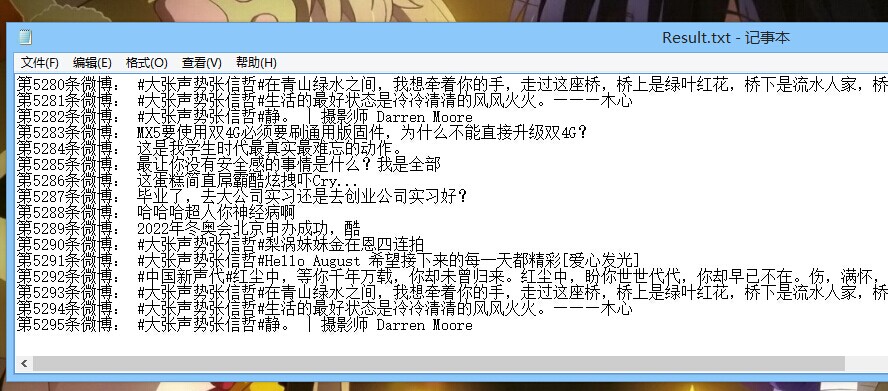
其实这里也只是给大家提供思路了,多多debug分析一下就好了,当然我这个办法还是属于比较笨的,若有大神有更吊的方法,欢迎告诉我o(^▽^)o
来源:oschina
链接:https://my.oschina.net/u/259421/blog/500070