这是EMNLP2016的一片关于用reinforcement learning(RL)做dialogue generation的文章,paper链接https://arxiv.org/abs/1606.01541,一作是仍然是李纪为大神(据说是stanford CS方向第一个3年毕业的PHD),现在是香侬科技的创始人,作者homepage http://stanford.edu/~jiweil/index.html,code还没有被released出来(github上面有很多实现的版本),但是作者released很多其他的dialogue generation的code https://github.com/jiweil/Neural-Dialogue-Generation。
个人瞎扯: 看这篇文章的原因。
- 1.这篇文章是比较早利用RL来做sequence生成的文章。
- 2.文章发表于NLP方向的顶会EMNLP2016,并且google citation很高。
文章要做的事情(dialogue generation):
输入:sentence(question) 输出:sentence(answer)
章show的可视化的实验结果如下所示。 
与state-of-the-art方法对比结果如下所示。 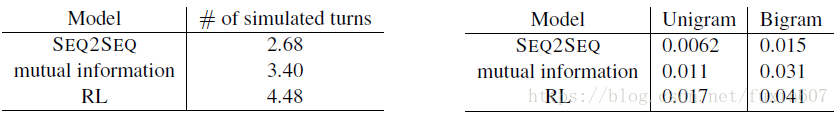
method
文章给出了Dialogue simulation between the two agents的示意图,如下所示。 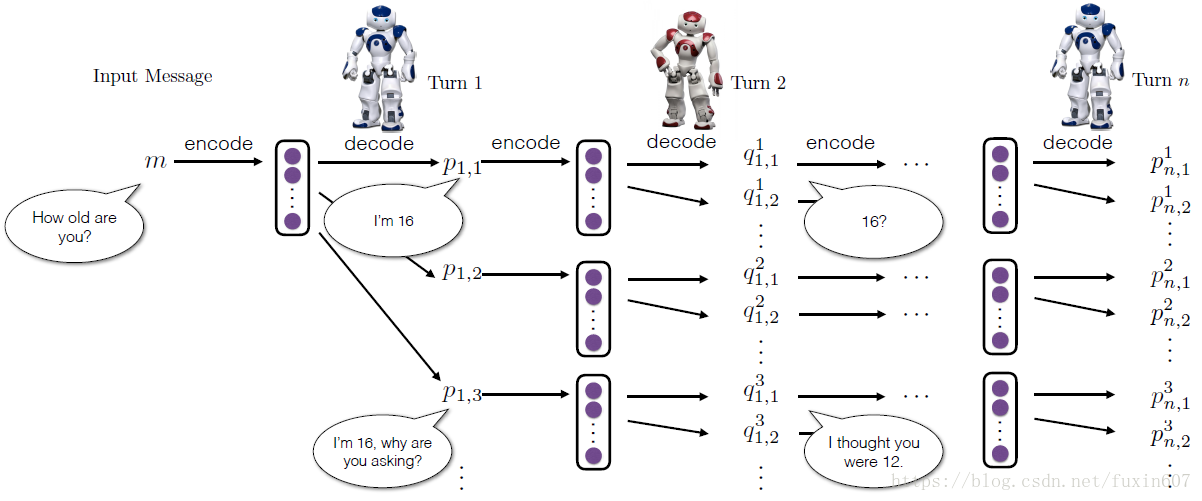
来源:CSDN
作者:fuxin607
链接:https://blog.csdn.net/fuxin607/article/details/80014164