一、什么是Zookeeper
Zookeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以单机模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。
1、zookeeper是为别的分布式程序服务的
2、Zookeeper本身就是一个分布式程序(只要有半数以上节点存活,zk就能正常服务)
3、Zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统> 一名称服务等
4、虽然说可以提供各种服务,但是zookeeper在底层其实只提供了两个功能:
管理(存储,读取)用户程序提交的数据(类似namenode中存放的metadata);
并为用户程序提供数据节点监听服务;
1.1 Zookeeper集群机制
Zookeeper集群的角色: Leader 和 follower
只要集群中有半数以上节点存活,集群就能提供服务
1.2 Zookeeper特性
1、Zookeeper:一个leader,多个follower组成的集群
2、全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的
3、分布式读写,更新请求转发,由leader实施
4、更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
5、数据更新原子性,一次数据更新要么成功,要么失败
6、实时性,在一定时间范围内,client能读到最新数据
1.3 Zookeeper数据结构
1、层次化的目录结构,命名符合常规文件系统规范(类似文件系统)
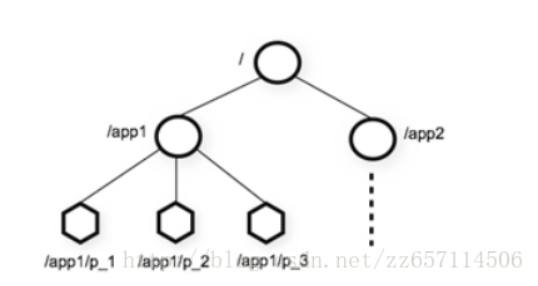
2、每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
3、节点Znode可以包含数据和子节点(但是EPHEMERAL类型的节点不能有子节点)
节点类型
a、Znode有两种类型:
短暂(ephemeral)(create -e /app1/test1 “test1” 客户端断开连接zk删除ephemeral类型节点)
持久(persistent) (create -s /app1/test2 “test2” 客户端断开连接zk不删除persistent类型节点)
b、Znode有四种形式的目录节点(默认是persistent )
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列/test0000000019 )
EPHEMERAL
EPHEMERAL_SEQUENTIAL
c、创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
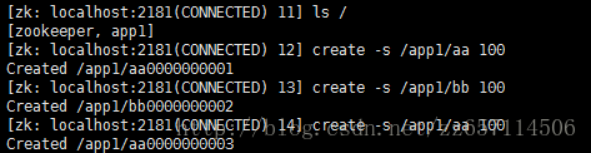
d、在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
二、Zookeeper应用场景
统一命名服务
分布式环境下,经常需要对应用/服务进行统一命名,便于识别不同服务。类似于域名与ip之间对应关系,域名容易记住。通过名称来获取资源或服务的地址,提供者等信息按照层次结构组织服务/应用名称可将服务名称以及地址信息写到Zookeeper上,客户端通过Zookeeper获取可用服务列表类。
配置管理
分布式环境下,配置文件管理和同步是一个常见问题。一个集群中,所有节点的配置信息是一致的,比如Hadoop。对配置文件修改后,希望能够快速同步到各个节点上配置管理可交由Zookeeper实现。可将配置信息写入Zookeeper的一个znode上。各个节点监听这个znode。一旦znode中的数据被修改,zookeeper将通知各个节点。
集群管理
分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态作出一些调整。Zookeeper可将节点信息写入Zookeeper的一个znode上。监听这个znode可获取它的实时状态变化。典型应用比如Hbase中Master状态监控与选举。
分布式通知/协调
分布式环境中,经常存在一个服务需要知道它所管理的子服务的状态。例如,NameNode须知道各DataNode的状态,JobTracker须知道各TaskTracker的状态。心跳检测机制和信息推送也是可通过Zookeeper实现。
分布式锁
Zookeeper是强一致的。多个客户端同时在Zookeeper上创建相同znode,只有一个创建成功。Zookeeper实现锁的独占性。多个客户端同时在Zookeeper上创建相同znode ,创建成功的那个客户端得到锁,其他客户端等待。Zookeeper 控制锁的时序。各个客户端在某个znode下创建临时znode (类型为CreateMode. EPHEMERAL _SEQUENTIAL),这样,该znode可掌握全局访问时序。
分布式队列
两种队列。当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。(可通过分布式锁实现)
同步队列。一个job由多个task组成,只有所有任务完成后,job才运行完成。可为job创建一个/job目录,然后在该目录下,为每个完成的task创建一个临时znode,一旦临时节点数目达到task总数,则job运行完成。
三、Zookeeper环境搭建
环境要求:必须要有jdk环境,本次讲课使用jdk1.8
3.1结构
一共三个节点
(zk服务器集群规模不小于3个节点),要求服务器之间系统时间保持一致。
3.2上传zk并且解压
进行解压: tar -zxvf zookeeper-3.4.6.tar.gz
重命名: mv zookeeper-3.4.6 zookeeper
3.3 修改zookeeper环境变量
vi /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_71
export ZOOKEEPER_HOME=/usr/local/zookeeper
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
source /etc/profile
3.4 修改zoo_sample.cfg文件
cd /usr/local/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
修改conf: vi zoo.cfg 修改两处
(1) dataDir=/usr/local/zookeeper/data(注意同时在zookeeper创建data目录)
(2)最后面添加
server.0=bhz:2888:3888
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
3.5 创建服务器标识
服务器标识配置:
创建文件夹: mkdir data
创建文件myid并填写内容为0: vi
myid (内容为服务器标识 : 0)
3.6 复制zookeeper
进行复制zookeeper目录到hadoop01和hadoop02
还有/etc/profile文件
把hadoop01、 hadoop02中的myid文件里的值修改为1和2
路径(vi /usr/local/zookeeper/data/myid)
3.7 启动zookeeper
启动zookeeper:
路径: /usr/local/zookeeper/bin
执行: zkServer.sh start
(注意这里3台机器都要进行启动)
状态: zkServer.sh
status(在三个节点上检验zk的mode,一个leader和俩个follower)
3.8常用命令
zkServer.sh status 查询状态
四、Zookeeper配置文件介绍
|
# The number of milliseconds of each tick tickTime=2000
# The number of ticks that the initial # synchronization phase can take initLimit=10
# The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5
# the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/myuser/zooA/data
# the port at which the clients will connect clientPort=2181
# ZooKeeper server and its port no. # ZooKeeper ensemble should know about every other machine in the ensemble # specify server id by creating 'myid' file in the dataDir # use hostname instead of IP address for convenient maintenance server.1=127.0.0.1:2888:3888 server.2=127.0.0.1:2988:3988 server.3=127.0.0.1:2088:3088
# # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir # autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature <br> #autopurge.purgeInterval=1 dataLogDir=/home/myuser/zooA/log
|
tickTime:心跳时间,为了确保连接存在的,以毫秒为单位,最小超时时间为两个心跳时间
initLimit:多少个心跳时间内,允许其他server连接并初始化数据,如果ZooKeeper管理的数据较大,则应相应增大这个值
clientPort:服务的监听端口
dataDir:用于存放内存数据库快照的文件夹,同时用于集群的myid文件也存在这个文件夹里(注意:一个配置文件只能包含一个dataDir字样,即使它被注释掉了。)
dataLogDir:用于单独设置transaction log的目录,transaction log分离可以避免和普通log还有快照的竞争
syncLimit:多少个tickTime内,允许follower同步,如果follower落后太多,则会被丢弃。
server.A=B:C:D:
A是一个数字,表示这个是第几号服务器,B是这个服务器的ip地址
C第一个端口用来集群成员的信息交换,表示的是这个服务器与集群中的Leader服务器交换信息的端口
D是在leader挂掉时专门用来进行选举leader所用
五、Zookeeper客户端
ZooKeeper命令行工具类似于Linux的shell环境,不过功能肯定不及shell啦,但是使用它我们可以简单的对ZooKeeper进行访问,数据创建,数据修改等操作. 使用 zkCli.sh -server 127.0.0.1:2181 连接到 ZooKeeper 服务,连接成功后,系统会输出 ZooKeeper 的相关环境以及配置信息。
命令行工具的一些简单操作如下:
- 1. 显示根目录下、文件: ls / 使用 ls 命令来查看当前 ZooKeeper 中所包含的内容
- 2. 显示根目录下、文件: ls2 / 查看当前节点数据并能看到更新次数等数据
- 3. 创建文件,并设置初始内容: create /zk "test" 创建一个新的 znode节点“ zk ”以及与它关联的字符串
- 4. 获取文件内容: get /zk 确认 znode 是否包含我们所创建的字符串
- 5. 修改文件内容: set /zk "zkbak" 对 zk 所关联的字符串进行设置
- 6. 删除文件: delete /zk 将刚才创建的 znode 删除
- 7. 退出客户端: quit
- 8. 帮助命令: help
六、Java操作Zookeeper
6.1 Zookeeper说明
创建节点(znode) 方法:
create:
提供了两套创建节点的方法,同步和异步创建节点方式。
口
同步方式:
参数1,节点路径《名称) : InodeName (不允许递归创建节点,也就是说在父节点不存在
的情况下,不允许创建子节点)
参数2,节点内容: 要求类型是字节数组(也就是说,不支持序列化方式,如果需要实现序
列化,可使用java相关序列化框架,如Hessian、Kryo框架)
参數3,节点权限: 使用Ids.OPEN_ACL_UNSAFE开放权限即可。(这个参数一般在权展
没有太高要求的场景下,没必要关注)
参数4,节点类型: 创建节点的类型: CreateMode,提供四种首点象型
PERSISTENT(持久节点)
PERSISTENT SEQUENTIAL(持久顺序节点)
EPHEMERAL(临时节点)
EPHEMERAL SEQUENTAL(临时顺序节点)
6.2 maven引入依赖
|
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.6</version> </dependency> |
6.3 Zookeeper客户端连接
|
public class ZookeeperDemo { /** * 集群连接地址 */ private static final String CONNECT_ADDR = "192.168.110.138:2181,192.168.110.147:2181,192.168.110.148:2181"; /** * session超时时间 */ private static final int SESSION_OUTTIME = 2000; /** * 信号量,阻塞程序执行,用户等待zookeeper连接成功,发送成功信号, */ private static final CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) throws IOException, InterruptedException, KeeperException { ZooKeeper zk = new ZooKeeper(CONNECT_ADDR, SESSION_OUTTIME, new Watcher() {
public void process(WatchedEvent event) { // 获取时间的状态 KeeperState keeperState = event.getState(); EventType tventType = event.getType(); // 如果是建立连接 if (KeeperState.SyncConnected == keeperState) { if (EventType.None == tventType) { // 如果建立连接成功,则发送信号量,让后阻塞程序向下执行 countDownLatch.countDown(); System.out.println("zk 建立连接"); } } }
}); // 进行阻塞 countDownLatch.await(); //创建父节点 //String result = zk.create("/testRott", "12245465".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); //System.out.println("result:" + result); //创建子节点 String result = zk.create("/testRott/children", "children 12245465".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println("result:"+result); zk.close(); }
} |