个人认为PySpider是一个十分容易上手而且功能强大的Python爬虫框架。支持多线程爬取、JS动态解析、出错重试、定时爬取等等的功能。最重要的是,它通过web提供了可操作界面,使用非常人性化。
最近由于工作的原因,秉承这服务广大高考考生和家长的态度ヾ(≧O≦)〃嗷~,我搜集了2017年2000多所高校的高校招生章程。
安装PySpider
首先先要安装pip跟phantomjs:
| 1 |
|
phantomjs是一个基于webkit内核的无界面浏览器,提供JavaScript API接口。在PySpider中用于JS动态解析。
之后可以用pip直接安装PySpider:
| 1 |
|
通过以下指令就可以启动PySpider啦:
| 1 |
|
打开浏览器访问http://localhost:5000可以看到web界面:

之后点击Create可以新建一个爬虫项目:
之后就可以看到一个爬虫操作的页面:
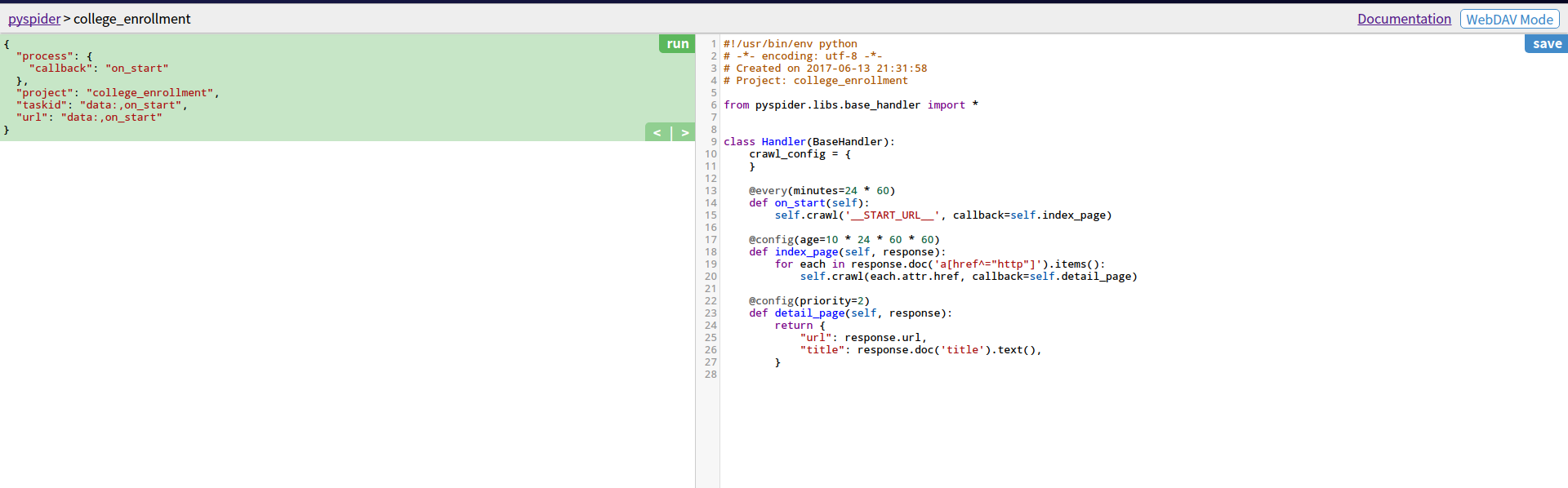
页面分开为两半。左半边是爬虫结果预览,右半边是爬虫代码编写区域。
左侧上半部分是爬虫的每个网络请求的解析。下半部分是爬虫页面浏览。
最下面有5个按钮:
enable css selector helper按钮:点击它启动css selector helper。用鼠标点击页面的元素可以很方便地生成该元素的css选择器表达式;
web: 点击可以查看抓取的页面的实时预览图;
html: 点击可以查看抓取页面的 HTML 代码。
follows: 如果这一层抓取方法中又新建了网页请求,那么接下来的请求就会出现在 follows 里。
messages: 一个控制台,用于显示爬虫输出的信息。
分析下网站吧
我们要爬的是教育部阳光高考信息公开平台:http://gaokao.chsi.com.cn/zsgs/zhangcheng/listVerifedZszc--method-index,lb-1,start-0.dhtml
一共有28页'start-'后边接的是页数的编号。
所以我打算这样写on_start方法来开始这条爬虫:
| 1 2 3 4 5 6 |
|
先定义页码前的地址,之后定义页码。crawl方法新建了请求之后把返回的结果传给callback参数里的方法。
按下save保存,再按run试着运行一下吧: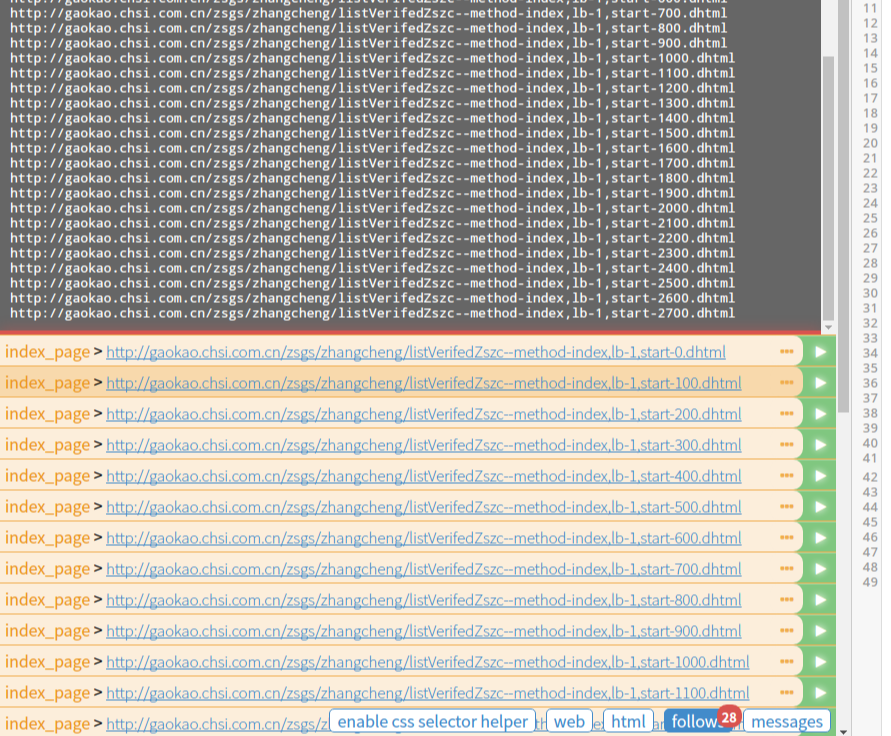
可以看到follow按钮上面出现了28的数字,这就是我们新建的28个页面请求啦。然后我们点击左侧第一个绿色箭头,可以继续爬取第一页这个页面。

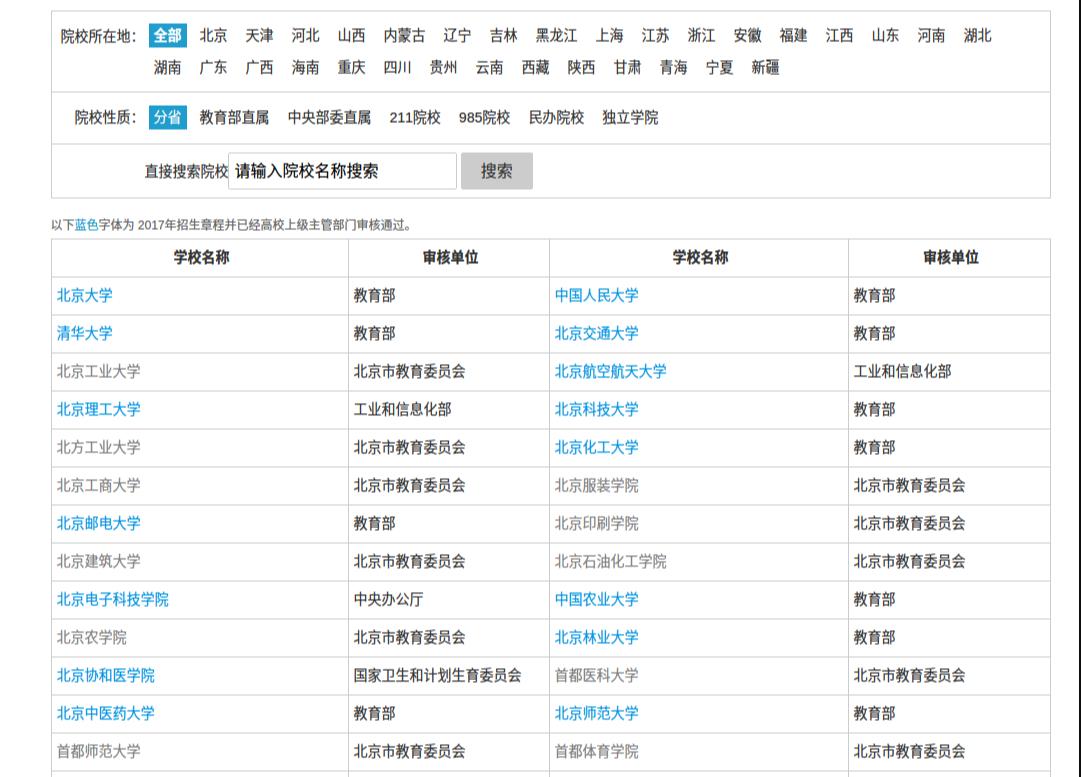
里边灰色字体的是暂时没有公布2017年招生章程的学校,而我们需要选定蓝色字体的学校以及其链接。点击html查看其网页源码:

可以看到我们要选择td下面的没有style="color:gray"这个属性的a标签。
那么css表达式可以这么写:td a:not([style="color:gray"])[target="_blank"]
补充index_page方法:
| 1 2 3 |
|
pyspider爬取的内容通过回调的参数response返回,response有多种解析方式。
1、response.json用于解析json数据
2、response.doc返回的是PyQuery对象
3、response.etree返回的是lxml对象
4、response.text返回的是unicode文本
5、response.content返回的是字节码
response.doc()其实是调用了 PyQuery框架,用 CSS 选择器得到每一个公布了2017年招生章程的链接,然后重新发起新的请求,回调函数就是 detail_page。修改完save之后run,就新建了80个请求了: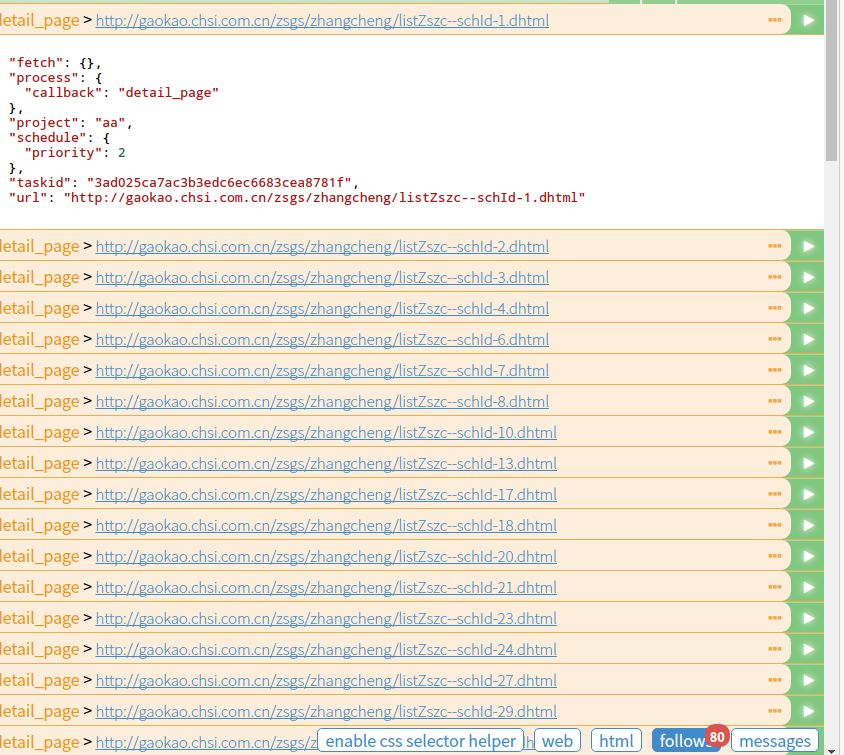
点第一个请求就可以进入北京大学这几年招生章程的页面啦: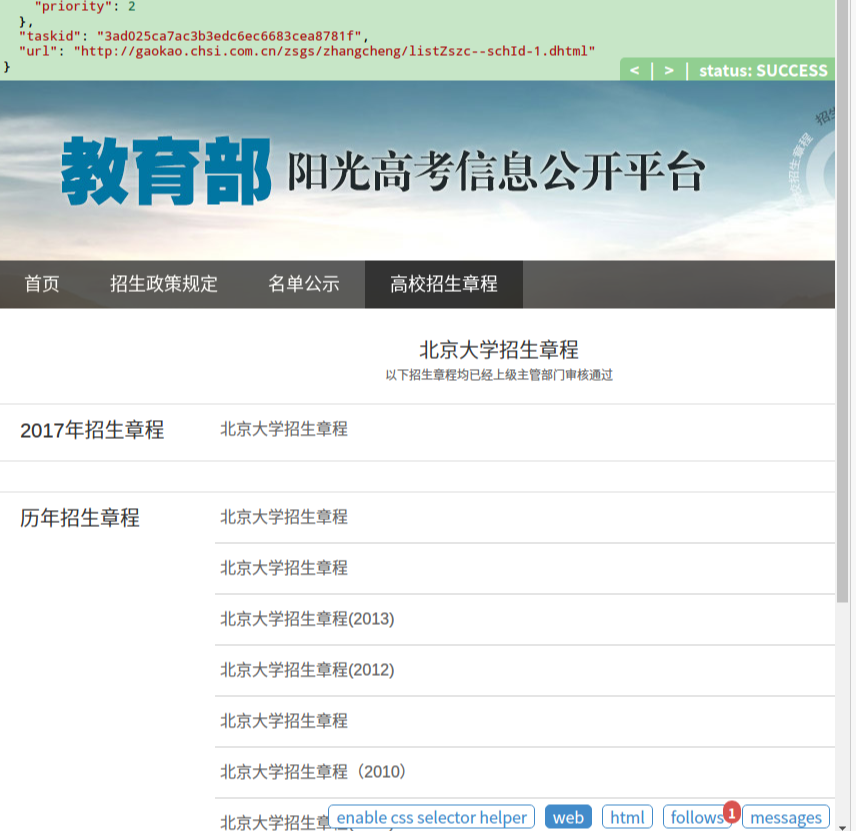
我们想要的是第一个2017年的章程,这时候点击enable css selector helper按钮,之后点一下2017的章程链接,可以看到它给我们的css选择器表达式选定了之前所有的章程: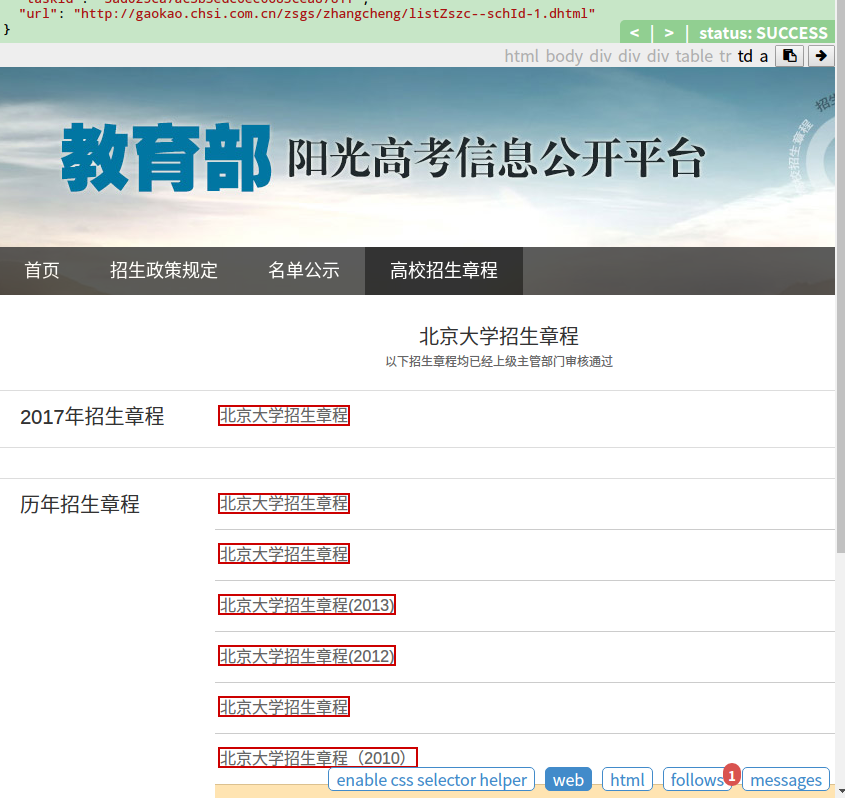
不过不要紧( ̄_, ̄ ),2017年的章程总是在第一个,所以我们可以只选定第一个给回调函数处理。
| 1 2 3 |
|
response.doc()方法返回的实际上是个选择器对象而不是列表。所以不能用列表切片操作,用第一个next可以返回选择器里的第一个元素,那就是2017年的章程啦。之后给constitution_page方法处理。
接下来就到了简章内容的页面啦。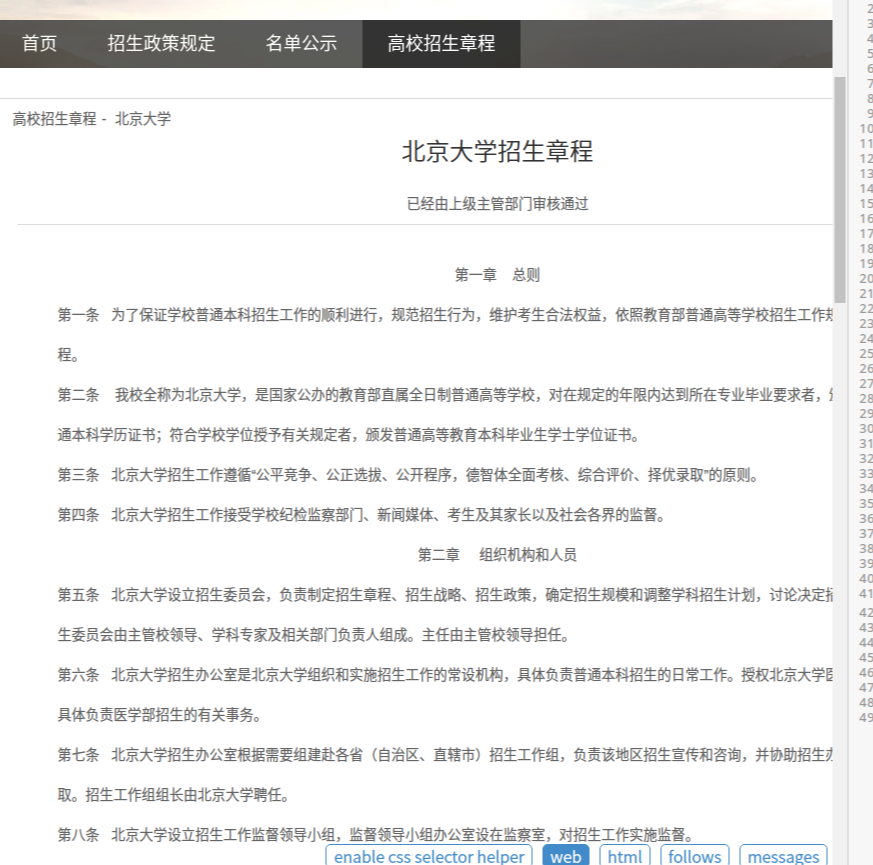
| 1 2 3 4 5 6 7 8 9 |
|
我们选定了所有的p标签,从第四个开始就是章程的正文,然后写入文件完成编写爬虫任务。ヽ(✿゚▽゚)ノ
记得save之后回到Dashboaed主页面。把项目的status改为running,按run就可以开始爬爬爬啦。
是不是感觉速度有点慢?rate/burst选项可以调节速度的。rate是指每秒执行多少个请求,burst是设置并发数,如 rate/burst = 1/3 这个意思是爬虫每1秒执行一个请求,但是前三个任务会同时执行,不会等1秒,第四个任务会等1秒再执行。默认的1/3速度比较慢。可以调到比较高,而burst不能小于rate。
来源:oschina
链接:https://my.oschina.net/u/3797187/blog/1812620