链表
单向链表
单链表,通俗讲就是只知道下个节点,不知道上个节点,如下图:
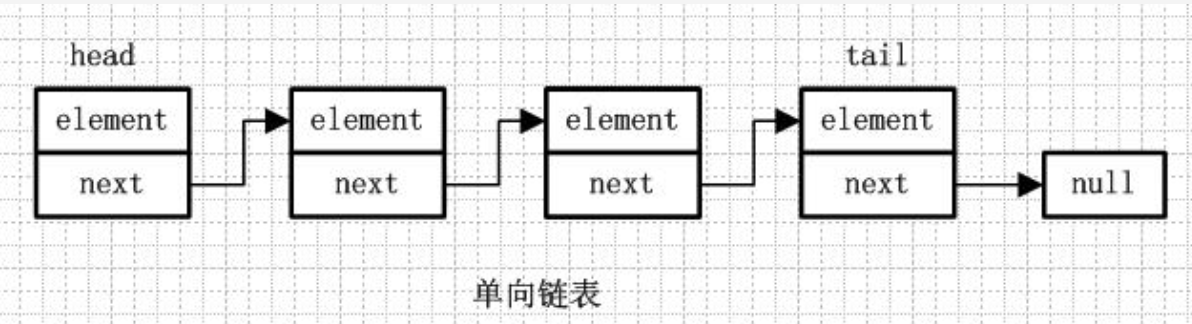
单链表的特点:
- 最后一个节点的next为null(闭环链表指向第一个元素)
- 只可一个方向遍历
双向链表
双链表,通俗讲就是既知道下个节点,也知道上个节点,如下图:
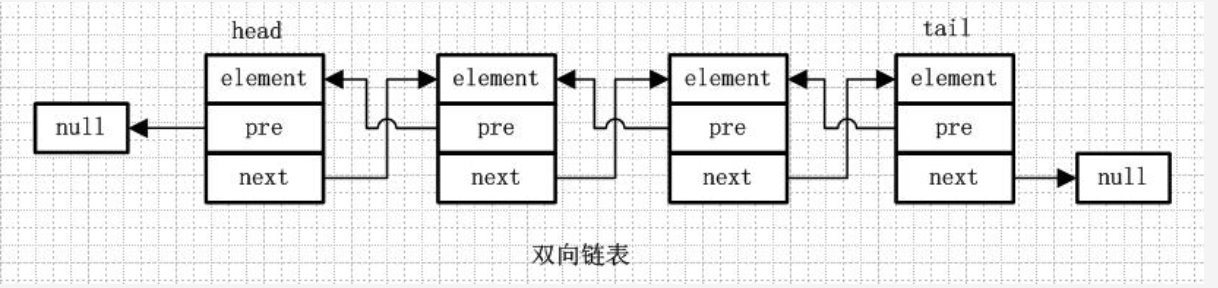
特点:
- 最后一个节点的next为null(闭环链表指向第一个元素)
- 可双向遍历(从头部或者尾部遍历)
LinkedList
以下都是基于jdk1.8
LinkedList是一个双向链表结构
实现了List和Deque接口。 所以也实现了List的操作和双端队列的操作,并允许所有元素(包括null )
迭代操作iterator和listIterator,面对并发修改,迭代器将快速而干净地失败,而不是在未来未确定的时间冒着任意的非确定性行为
父类介绍
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{}
说明:
- 继承AbstractSequentialList,提供了添加add()、随机访问get()、迭代器、移除remove等方法

- 实现List接口,提供了普通集合类的一些标准方法
- 实现Deque,表明可以像操作双端队列一样来操作LinkedList
- 实现Cloneable,提供了克隆方法
- 实现Serializable,支持序列化
属性
//链表中元素个数
transient int size = 0;
//第一个元素
transient Node<E> first;
//最后一个元素
transient Node<E> last;
Node中存放元素,Node的源码:
private static class Node<E> {
E item;//数据
Node<E> next;//下一节点
Node<E> prev;//前一节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
添加元素
尾部添加add(e)
public boolean add(E e) {
linkLast(e);
return true;
}
//在最后节点添加元素
void linkLast(E e) {
final Node<E> l = last;
//新建节点,指向last节点,并赋值e,next指向null
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
指定位置添加 add(index, e)
这种方式需要遍历链表来获取该位置的元素,效率较差
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)//如果是尾部
linkLast(element);
else
linkBefore(element, node(index));//计算index位置并添加
}
/**
* 根据索引计算位置,返回非空元素
* 这里是先计算索引位置在链表的一半之前还是之后,然后选择从前遍历还是从后遍历。这样做能提升查找效率
*/
Node<E> node(int index) {
//如果索引值小于list的size一半,就从头部开始遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//否则从尾部开始遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/**
* 某个节点succ之前添加节点
*/
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
//新建节点,前一节点为索引所在节点的pred,赋值为元素e,下一节点为索引所在节点
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
随机访问 get(index)
public E get(int index) {
checkElementIndex(index);//检查索引值是否合法
return node(index).item;//遍历获取值,效率较差
}
修改元素 set
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);//计算索引位置,效率差
E oldVal = x.item;
x.item = element;
return oldVal;
}
移除元素 remove(index)
移除头元素 remove()
public E remove() {
return removeFirst();
}
// 移除first
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
移除指定索引位置 remove(index)
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));//计算索引位置元素,性能差
}
队列相关操作
从头部获取(不删除元素,队列为空返回null值) peek()
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
从头部获取(不删除元素,队列为空返回抛异常) element()
public E element() {
return getFirst();
}
从头部获取(删除元素,队列为空返回null) poll()
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
从头部添加 offer()
//头部添加
public boolean offer(E e) {
return add(e);
}
//头部添加
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
尾部添加
public boolean offerLast(E e) {
addLast(e);
return true;
}
其他...
关于序列化
因为LinkedList的元素(size、first、last)都用transient修饰,所以定义了自定义序列化,为了防止所有空间都序列化,造成空间浪费,所以自定义实现,只序列化有值的链表数据
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject();
// 序列化大小
s.writeInt(size);
// 只序列化有值的链表数据
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
来源:oschina
链接:https://my.oschina.net/u/4018042/blog/2998526