一.位:
计算机存储信息的最小单位,称之为位(bit),音译比特,二进制的一个“0”或一个“1”叫一位。
二.字节
字节(Byte)是一种计量单位,表示数据量多少,它是计算机信息技术用于计量存储容量的一种计量单位,8个二进制位组成1个字节。在ASCII码中,一个标准英文字母(不分大小写)占一个字节位置,一个标准汉字占二个字节位置。
三.字符
字符是指计算机中使用的文字和符号,比如“1、2、3、A、B、C、~!·#¥%…*()+”等等。
四.ASCII码
先从最简单的ASCII说起吧,这个大家也熟悉:全名是American Standard Code for Information Interchange, 叫做“美国信息交换标准码”。ASCII码中,一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。ASCII码是目前最普及的一种字符编码,它扎根于我们的互联网,操作系统,键盘,打印机,文件字体和打印机等。ASCII表如下:
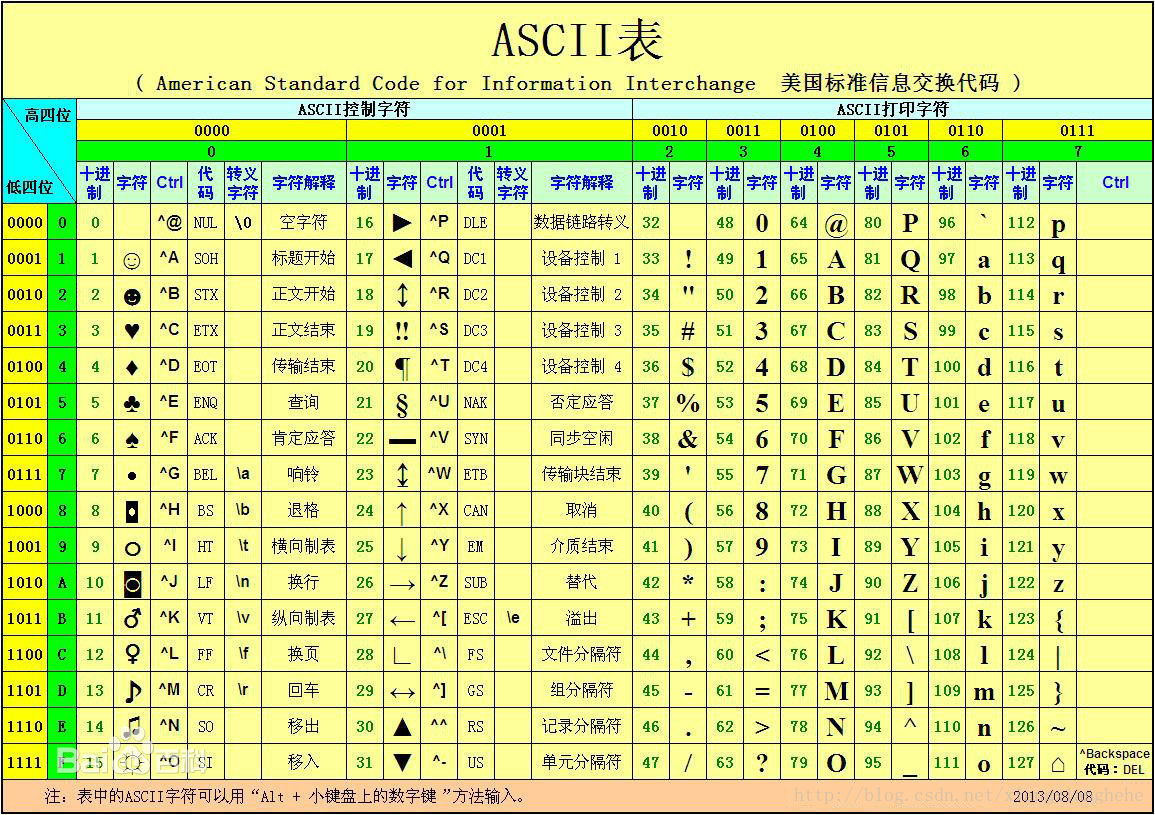
当然,从这个名字美国信息交换标准码来看,ASCII码只适用于美帝,要是用在美帝之外的国家,就不能满足需求了。
ANSI码
ANSI编码是一种对ASCII码的拓展:ANSI编码用0x00~0x7f (即十进制下的0到127)范围的1 个字节来表示 1 个英文字符,超出一个字节的 0x80~0xFFFF 范围来表示其他语言的其他字符。也就是说,ANSI码仅在前128(0-127)个与ASCII码相同,之后的字符全是某个国家语言的所有字符。值得注意的是,两个字节最多可以存储的字符数目是2的16次方,即65536个字符,这对于一个语言的字符来说,绝对够了。还有ANSI编码其实包括很多编码:中国制定了GB2312编码,用来把中文编进去另外,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准。受制于当时的条件,不同语言之间的ANSI码之间不能互相转换,这就会导致在多语言混合的文本中会有乱码。
Unicode编码
为了解决不同国家ANSI编码的冲突问题,Unicode应运而生:如果全世界每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
但是问题在于,原本可以用一个字节存储的英文字母在Unicode里面必须存两个字节(规则就是在原来英文字母对应ASCII码前面补0),这就产生了浪费。那么有没有一种既能消除乱码,又能避免浪费的编码方式呢?答案就是UTF-8!
UTF-8编码
这是一种变长的编码方式:它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,如此一来UTF-8编码也可以是为视为一种对ASCII码的拓展。值得注意的是unicode编码中一个中文字符占2个字节,而UTF-8一个中文字符占3个字节。从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
在内存中存储字符时还是使用unicode编码,因为unicode编码的长度固定,处理起来很方便。而在文件的存储中,则使用utf-8编码,可以压缩内存,节省空间
转自https://blog.csdn.net/xiangxianghehe/article/details/77574965
很多开发者进行数据库设计的时候往往并没有太多的考虑char, varchar类型,有的是根本就没注意,因为存储价格变得越来越便宜了,忘记了最开始的一些基本设计理论和原则,这点让我想到了现在的年轻人,大手一挥 一把人民币就从他手里溜走了,其实我想不管是做人也好,做开发也好,细节的把握直接决定很多东西。当然还有一部分人是根本就没弄清楚他们的区别,也就随便 选一个。在这里我想对他们做个简单的分析,当然如果有不对的地方希望大家指教。
1、CHAR。CHAR存储定长数据很方便,CHAR字段上的索引效率级高,比如定义char(10),那么不论你存储的数据是否达到了10个字节,都要占去10个字节的空间,不足的自动用空格填充,所以在读取的时候可能要多次用到trim()。
2、 VARCHAR。存储变长数据,但存储效率没有CHAR高。如果一个字段可能的值是不固定长度的,我们只知道它不可能超过10个字符,把它定义为 VARCHAR(10)是最合算的。VARCHAR类型的实际长度是它的值的实际长度+1。为什么“+1”呢?这一个字节用于保存实际使用了多大的长度。 从空间上考虑,用varchar合适;从效率上考虑,用char合适,关键是根据实际情况找到权衡点。
3、TEXT。text存储可变长度的非Unicode数据,最大长度为2^31-1(2,147,483,647)个字符。
4、 NCHAR、NVARCHAR、NTEXT。这三种从名字上看比前面三种多了个“N”。它表示存储的是Unicode数据类型的字符。我们知道字符中,英 文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱,Unicode字符集就是为了解决字符集这种不兼 容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示。nchar、nvarchar的长度是在1到4000之间。和 char、varchar比较起来,nchar、nvarchar则最多存储4000个字符,不论是英文还是汉字;而char、varchar最多能存储 8000个英文,4000个汉字。可以看出使用nchar、nvarchar数据类型时不用担心输入的字符是英文还是汉字,较为方便,但在存储英文时数量 上有些损失。
所以一般来说,如果含有中文字符,用nchar/nvarchar,如果纯英文和数字,用char/varchar
我把他们的区别概括成:
CHAR,NCHAR 定长,速度快,占空间大,需处理
VARCHAR,NVARCHAR,TEXT 不定长,空间小,速度慢,无需处理
NCHAR、NVARCHAR、NTEXT处理Unicode码
第二篇:
以前只知道text和image是可能被SQL Server淘汰的数据类型,但具体原因不太清楚,今天读书的时候发现了text与varchar(max)和nvarchar(max)的区别,主要是对操作符的限制,text只能被下列函数作用:
| 函数 | 语句 |
|---|---|
|
DATALENGTH |
READTEXT |
|
PATINDEX |
SET TEXTSIZE |
|
SUBSTRING |
UPDATETEXT |
|
TEXTPTR |
WRITETEXT |
|
TEXTVALID |
举个列子,如果“文本”这一列的数据类型为text,那么它将不能用于“=”“left()”等操作,比如下面的例子:
建立表,填充数据:
if exists (select * from sysobjects where id = OBJECT_ID('[asdf]') and OBJECTPROPERTY(id, 'IsUserTable') = 1)
DROP TABLE [asdf]
CREATE TABLE [asdf] (
[inttest] [int] IDENTITY (1, 1) NOT NULL ,
[text] [text] NULL ,
[varcharmax] varchar(max) NULL )
ALTER TABLE [asdf] WITH NOCHECK ADD CONSTRAINT [PK_asdf] PRIMARY KEY NONCLUSTERED ( [inttest] )
SET IDENTITY_INSERT [asdf] ON
INSERT [asdf] ( [inttest] , [text] , [varcharmax] ) VALUES ( 1 , '1111111' , '1111111' )
SET IDENTITY_INSERT [asdf] OFF
运行查询:
查询一:
SELECT [text]
,[varcharmax]
FROM [testDB].[dbo].[asdf]
where
[text] ='11111' AND
[varcharmax] = '1111111'
会出现以下错误提示:
消息402,级别16,状态1,第1 行
数据类型text 和varchar 在equal to 运算符中不兼容。
查询二:
SELECT [text]
,[varcharmax]
FROM [testDB].[dbo].[asdf]
where
[varcharmax] = '1111111'
可以成功运行
在MS SQL2005及以上的版本中,加入大值数据类型(varchar(max)、nvarchar(max)、varbinary(max) )。大值数据类型最多可以存储2^30-1个字节的数据。
这几个数据类型在行为上和较小的数据类型 varchar、nvarchar 和 varbinary 相同。
微软的说法是用这个数据类型来代替之前的text、ntext 和 image 数据类型,它们之间的对应关系为:
varchar(max)-------text;
nvarchar(max)-----ntext;
varbinary(max)----image.
有了大值数据类型之后,在对大值数据操作的时候要比以前灵活的多了。比如:之前text是不能用‘like’的,有了varchar(max)之后 就没有这些问题了,因为varchar(max)在行为上和varchar(n)上相同,所以,可以用在varcahr的都可以用在 varchar(max)上。
另外,这个还支持对插入的和删除的表中的大值数据类型列引用上使用 AFTER 触发器。text就不行,总之,用了大值数据类型之后,我是“腰也不疼了,腿也不酸了,一口气也能上六楼了”。还等什么呢,快用大值类型吧。
2014年10月16日11:34:19
对SQL Server数据库的数据类型存储的学习掌握的确实不太好,我觉得我以前就是作者说的现在的年轻人,看了一点资料,对作者说的进行一下总结:
1.数据类型的对应关系:
varchar(max)-------text;
nvarchar(max)-----ntext;
varbinary(max)----image.
2.现在尽量不用text,ntext,image类型来存储数据了
3.从空间上考虑,用varchar合适(其实还是尽量使用varchar,毕竟现在是大数据时代);从效率上考虑,用char合适,关键是根据实际情况找到权衡点。
4.使用nchar、nvarchar数据类型时不用担心输入的字符是英文还是汉字,较为方便,但在存储英文时数量上有些损失。所以一般来说,如果含有中文字符,用nchar/nvarchar,如果纯英文和数字,用char/varchar
5.
支持多语言的站点应考虑使用 Unicode nchar 或 nvarchar 数据类型以尽量减少字符转换问题。
如果希望列中的数据值大小接近一致,请使用 char。
如果希望列中的数据值大小显著不同,请使用 varchar。
如果希望列中所有数据项的大小接近一致,则使用 nchar。
如果希望列中数据项的大小差异很大,则使用 nvarchar。
如果执行 CREATE TABLE 或 ALTER TABLE 时 SET ANSI_PADDING 为 OFF,则一个定义为 NULL 的 char 列将被作为 varchar 处理。
6.
1)如果数据量非常大,又能100%确定长度且保存只是ansi字符,那么char
2)能确定长度又不一定是ansi字符或者,那么用nchar;
3)不确定长度,要查询且希望利用索引的话,用nvarchar类型吧,将它们设到400;
4)不查询的话没什么好说的,用nvarchar(4000)
7.
CHAR,NCHAR 定长,速度快,占空间大,需处理
VARCHAR,NVARCHAR,TEXT 不定长,空间小,速度慢,无需处理
NCHAR、NVARCHAR、NTEXT处理Unicode码