问题大致含义:给出两个字符串s1、s2,判断s2是否为s1的子串。
普通匹配算法:
- 用两个下标i,j来记录s1和s2当前元素的下标,初始值都为0; 还需要一个index记录s1匹配的起始坐标。
- 结束条件:i=len(s1) or j=len(s2) ; 如果j=len(s2),那么匹配成功; 否则,匹配失败。
- 迭代过程: s1[i]=s2[j],则i++ , j++; 如果不相等,那么j=0;index++; i=index;
时间复杂度:O(mn),m,n是两个串的长度。
1 /* 字符串下标始于 0 */
2 int NaiveStringSearch(string S, string P)
3 {
4 int i = 0; // S 的下标
5 int j = 0; // P 的下标
6 int s_len = S.size();
7 int p_len = P.size();
8
9 while (i < s_len && j < p_len)
10 {
11 if (S[i] == P[j]) // 若相等,都前进一步
12 {
13 i++;
14 j++;
15 }
16 else // 不相等
17 {
18 i = i - j + 1;
19 j = 0;
20 }
21 }
22
23 if (j == p_len) // 匹配成功
24 return i - j;
25
26 return -1;
27 }
KMP算法:
算法核心:当算法匹配成功的时候与普通的字符串匹配算法并没有太大的不同,都是比较下一个元素;但是在匹配失败的时候,利用某些信息来减少一些不必要的匹配。
next数组:
- next数组是KMP的核心数据结构,通过next的特性能够减少不必要的匹配。
- next数组的含义:对于一个字符串S,其长度为len(S),那么next的下标范围为:0~len(S)-1,对于i∈[0,len(S)],next[i]:使子串S[0:i]中形成前缀S[0:k]和后缀S[i-k:i]相同的最大k值(k一定小于i,当不能匹配,取-1)。
用一个例子来解释next[i]: S="ababaab" len(S)=7 (下面所用的符号与上面说明对应)
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| next[i] | -1 | -1 | 0 | 1 | 2 | 3 | -1 |
- i=0时,默认为-1;(只有一个元素,S[0])
- i=1时,S[0:1]="ab",next[i]=-1,因为k=0时,S[0:0]="a",S[1:1]="b",不匹配,k必须小于i。
- i=2时,S[0:2]="aba",next[i]=0,因为k=0时,S[0:0]="a",S[2:2]=“a”,匹配; k=1时,S[0:1]="ab",S[1:2]="ba",不匹配。
- i=3时,S[0:3]="abab",next[i]=1。
- i=4,5,6::略
- next数组的意义:对于S,给出了所有S[0:i]的子串最长的前缀与后缀相同的位置。(字符串匹配的目的是实现所有的相同,所有相同必定是部分相同的子集,因此能够跳入到下一个可能进行匹配的位置)
KMP算法:
- 注意:在匹配失败的时候如何利用next数组,以及i,j如何变化。
S1="abababaabc" S2="ababaab",判断S2是否为S1的子串。
- 建立S2的next数组 (为什么要建立S2(匹配串)的next数组? 因为它需要主动匹配,涉及到前缀和后缀的等价转换,不同串之间的等价转换)
- 用i指向S1欲匹配的字符,用j指向S2已匹配的字符;i=0,j=-1;
- 用S1[i]与S2[j+1]进行匹配:
- i∈[0,4],是匹配成功的,这时候只需要i++,j++; 最后到达i=5,j=4;(匹配成功情况)
- 因为S1[i]="b",S2[j+1]="a",因此不匹配; 关键点来了,那么用什么元素进行再次比较呢? (图1) (匹配失败情况) S1[0:4]=S2[0:4], 根据next数组,next[j]=2(说明S2[0:2]=S2[2:4] ) S2[2:4]=S1[2:4], 经过等价代换, 同时令j=next[j] ,可以发现:S2[0:2]=S1[2:4]; 在此时再比较S1[i]与S2[j+1],看是否相等(i=5,j=2);这时候发现相等了,因此按照成功时候进行匹配。
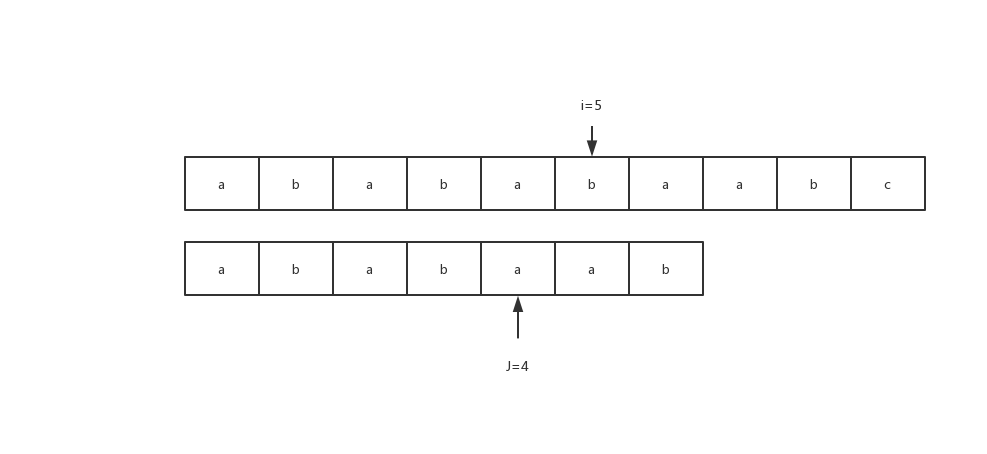 图1
图1

图2
算法步骤综述:(用数学关系完整地阐述一遍) S1:被匹配串, S2:匹配串
- 用i指向S1欲匹配的字符,用j指向S2已匹配的字符;i=0,j=-1; 建立S2的next数组。
- 循环结束条件:当j=len(S2)-1 or i=len(S1) ; 如果j=len(S2)-1,那么匹配成功; 否则,匹配失败
- 循环过程:
- 如果S1[i]=S2[j+1],那么匹配成功,i++,j++;
- 如果S1[i]!=S2[j+1],那么匹配失败,j=next[j],再次判断S1[i]与S2[j+1]的关系;(继续循环) 如果j=-1,并且匹配失败,那么i++;