概述:
flink kafka实时流计算时都是用默认的序列化和分区器,这篇文章主要介绍如何向Kafka发送消息,并自定义消息的key,value,自定义消息分区类,这里选择最新的Flink1.9.1进行讲解。
自定义序列化类KeyedSerializationSchema:
通常我们都是用默认的序列化类来发送一条消息,有时候我们需要执行发送消息的key,value值,或者解析消息体后,在消息的key或者value加一个固定的前缀,这时候我们就需要自定义他的序列化类,Flink提供了可自定的的序列化基类KeyedSerializationSchema,这里先看下他的源码,:
package org.apache.flink.streaming.util.serialization;import java.io.Serializable;import org.apache.flink.annotation.PublicEvolving;/** @deprecated */@Deprecated@PublicEvolvingpublic interface KeyedSerializationSchema<T> extends Serializable {byte[] serializeKey(T var1);byte[] serializeValue(T var1);String getTargetTopic(T var1);}
是不是很简单 ,子类只需要自定义以上三个函数即可,这里我自定义序列化类CustomKeyedSerializationSchema,这里实现比较简单,只是将消息体进行拆分,分别在消息的键值加了前缀,代码如下:
package com.hadoop.ljs.flink.utils;import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema;import java.util.Map;/** * @author: Created By lujisen* @company ChinaUnicom Software JiNan* @date: 2020-02-24 20:57* @version: v1.0* @description: com.hadoop.ljs.flink.utils*/public class CustomKeyedSerializationSchema implements KeyedSerializationSchema<String> {public byte[] serializeKey(String s) {/*根据传过来的消息,自定义key*/String[] line=s.split(",");System.out.println("key::::"+line[0]);return ("key--"+line[0]).getBytes();}public byte[] serializeValue(String s) {/*根据传过来的消息,自定义value*/String[] line=s.split(",");System.out.println("value::::"+line[1]);return ("value--"+line[1]).getBytes();}public String getTargetTopic(String topic) {/*这里是目标topic,一般不需要操作*/System.out.println("topic::::"+topic);return null;}}
自定义分区类FlinkKafkaPartitioner
自定义分区类需要继承他的基类,只需要实现他的抽象函数partition()即可,源码如下:
package org.apache.flink.streaming.connectors.kafka.partitioner;import java.io.Serializable;import org.apache.flink.annotation.PublicEvolving;public abstract class FlinkKafkaPartitioner<T> implements Serializable {private static final long serialVersionUID = -9086719227828020494L;public FlinkKafkaPartitioner() {}public void open(int parallelInstanceId, int parallelInstances) {}public abstract int partition(T var1, byte[] var2, byte[] var3, String var4, int[] var5);}
自定义分区类CustomFlinkKafkaPartitioner,我这里只是简单的实现,你可根据自己的业务需求,自定义:
package com.hadoop.ljs.flink.utils;import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner;/*** @author: Created By lujisen* @company ChinaUnicom Software JiNan* @date: 2020-02-24 21:00* @version: v1.0* @description: com.hadoop.ljs.flink.utils*/public class CustomFlinkKafkaPartitioner extends FlinkKafkaPartitioner {/*** @param record 正常的记录* @param key KeyedSerializationSchema中配置的key* @param value KeyedSerializationSchema中配置的value* @param targetTopic targetTopic* @param partitions partition列表[0, 1, 2, 3, 4]* @return partition*/public int partition(Object record, byte[] key, byte[] value, String targetTopic, int[] partitions) {//这里接收到的key是上面CustomKeyedSerializationSchema()中序列化后的key,需要转成string,然后取key的hash值`%`上kafka分区数量System.out.println("分区的数据量:"+partitions.length);int partion=Math.abs(new String(key).hashCode() % partitions.length);/*System.out.println("发送分区:"+partion);*/return partion;}}
主函数:
我的主函数是从Socket端接收消息,写入Kafka集群,这里只是个例子实现比较简单,代码如下:
package com.hadoop.ljs.flink.streaming;import com.hadoop.ljs.flink.utils.CustomFlinkKafkaPartitioner;import com.hadoop.ljs.flink.utils.CustomKeyedSerializationSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;import java.util.Properties;/*** @author: Created By lujisen* @company ChinaUnicom Software JiNan* @date: 2020-02-24 21:27* @version: v1.0* @description: com.hadoop.ljs.flink.utils*/public class FlinkKafkaProducer {public static final String topic="topic2402";public static final String bootstrap_server="10.124.165.31:6667,10.124.165.32:6667";public static void main(String[] args) throws Exception {final String hostname="localhost";final int port=9000;/*获取flink流式计算执行环境*/final StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();/*从Socket端接收数据*/DataStream<String> dataSource = senv.socketTextStream(hostname, port, "\n");/*下面可以根据自己的需求进行自动的转换*//* SingleOutputStreamOperator<Map<String, String>> messageStream = dataSource.map(new MapFunction<String, Map<String, String>>() {@Overridepublic Map<String, String> map(String value) throws Exception {System.out.println("接收到的数据:"+value);Map<String, String> message = new HashMap<>();String[] line = value.split(",");message.put(line[0], line[1]);return message;}});*//*接收的数据,中间可经过复杂的处理,最后发送到kafka端*/dataSource.addSink(new FlinkKafkaProducer010<String>(topic, new CustomKeyedSerializationSchema(), getProducerProperties(),new CustomFlinkKafkaPartitioner()));/*启动*/senv.execute("FlinkKafkaProducer");}/*获取Kafka配置*/public static Properties getProducerProperties(){Properties props = new Properties();props.put("bootstrap.servers",bootstrap_server);//kafka的节点的IP或者hostName,多个使用逗号分隔props.put("acks", "1");props.put("retries", 3);props.put("batch.size", 16384);props.put("linger.ms", 1);props.put("buffer.memory", 33554432);props.put("key.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer");return props;}}
测试验证:
从window命令行,通过socket端9000端口发送数据,主函数接收消息进行处理,然后发送kafka:
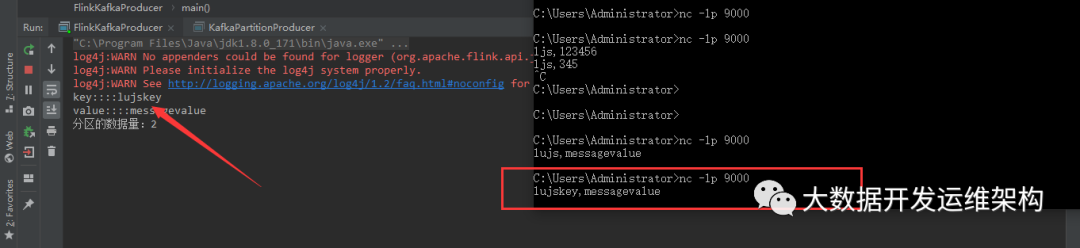
kafka接收消息,持久化到log中,如图:

 这里FLink的默认序列化和分区的知识我之后会写一篇文章详细讲解,在一个kafka没有经过SSL加密认证,加密后的Kafka集群如何与Flink进行集成,后面我都会统一进行讲解,敬请关注!!!!
这里FLink的默认序列化和分区的知识我之后会写一篇文章详细讲解,在一个kafka没有经过SSL加密认证,加密后的Kafka集群如何与Flink进行集成,后面我都会统一进行讲解,敬请关注!!!!

本文分享自微信公众号 - 大数据开发运维架构(JasonLu1986)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/2380815/blog/4453916