
监控系统是运维体系乃至整个软件产品生命周期中最重要的一环,完善的监控可以帮助我们事前及时发现故障,事后快速追查定位问题。而在以微服务为代表的云原生架构体系中,系统分为多个层次,服务之间调用链路复杂,系统中需要监控的目标非常多,如果没有一个完善的监控系统就难以保证整体服务的持续稳定。
监控对象及分层

在实际场景中监控系统按照监控的对象及系统层次结构,从底向上可以依次划分为基础层、中间层、应用层、业务层等多个层面的监控。具体可如图所示:

基础层监控就是对主机服务器(包括宿主机、容器)及其底层资源进行监控,以保证应用程序运行所依赖的基础环境的稳定运行。基础层监控主要有两个方向:
资源利用:是对像I/O利用率、CPU利用率、内存使用率、磁盘使用率、网络负载等这样的硬件资源进行监控。避免因应用程序本身或其它特殊情况引起的硬件资源耗尽而出现的服务故障。
网络通信:是对服务器之间的网络状态进行监控。网络通信是互联网的重要基石,如果主机之间的网络出现如延迟过大、丢包率高这样的网络问题,将会严重影响业务。
需要说明的是,在基于Kubernetes容器化技术的新型云原生基础设施中,基础层的监控不仅要对宿主机本身进行监控,也要对Kubernetes集群状态及其容器资源使用情况进行监控。这在后面我们构建基于Kubernetes的基础层监控体系时将会具体介绍。
中间层监控主要是指对诸如Nginx、Redis、MySQL、RocketMQ、Kafka等应用服务所依赖的中间件软件的监控,它们的稳定也是保证应用程序持续可用的关键。一般来说特定的中间件软件都会根据自身特点构建针对性的监控体系。
应用层监控这里就是指对业务性服务程序的监控,一般来说我们对应用程序监控的关注点主要体现在以下几个方面:
HTTP接口请求访问。包括接口响应时间、吞吐量等;
JVM监控指标。对于Java服务,还会重点关注GC时间、线程数、FGC/YGC耗时等JVM性能相关的指标;
资源消耗。应用程序部署后会消耗一定的资源,例如应用程序对内存、CPU的消耗情况;
服务的健康状态。例如当前服务是否存活,运行是否稳定等;
调用链路。在微服务架构中,由于调用链路变长,还需要重点监控服务之间的调用关系和调用情况,避免局部上下游服务之间的链路故障引发系统全局性雪崩;
业务层监控也是监控系统所关注的一个重要内容,在实际场景中如果你只是让应用程序稳定运行那肯定是远远不够的。因此,我们常常会对具体业务产生的数据进行监控,例如网站系统所关注的PV、UV等参数;后端如交易之类的系统我们则会关注订单量、成功率等。
业务指标也是体现系统稳定性的核心要素。任何系统,如果出现了问题,最先受到影响的肯定是业务指标。对于核心业务指标的设定因具体的业务和场景而异,所以对于业务层的监控需要构建具备业务特点的业务监控系统。
常见的监控指标类型
在指标类监控系统中,通过统计指标可以感性地认识到整个系统的运行情况。出现问题后,各个指标会首先出现波动,这些波动会反映出系统是那些方面出了问题,从而可以据此排查出现问题的原因。下面我们分别来看下统计指标到底有哪些类型,以及常见的统计指标都有哪些,它是我们进一步理解指标类监控系统的基础。
从整体上看,常见的Metrics指标类型主要有:计数器(Counter)、测量仪(Gauge)、直方图(Histogram)、摘要(Summary)这四类。它们的特点分别如下:
1. 计数器(Counter)
计数器是一种具有累加特性的指标类型,一般这个值为Double或者Long类型。例如常见的统计指标QPS、TPS等的值就是通过计数器的形式,然后配合一些统计函数计算得出的。
2. 测量仪(Gauge)
表示某个时间点,对某个数值的测量。测量仪和计数器都可以用来查询某个时间点的固定内容的数值,但和计数器不同,测量仪的值可以随意变化,可以增加也可以减少。比如获取Java线程池中活跃的线程数,使用的是ThreadPoolExecutor中的getActiveCount方法;此外,还有比较常见的CPU使用率、内存占用量等具体指标都是通过测量仪获取的。
3. 直方图(Histogram)
直方图是一种将多个数值聚合在一起的数据结构,可以表示数据的分布情况。比如以常见的响应耗时举例,可以把响应耗时数据分为多个桶(Bucket),每个桶代表一个耗时区间,例如0~100毫秒、100~500毫秒,以此类推。通过这样的形式,可以直观地看到一个时间段内的请求耗时分布,这将有助于我们理解耗时情况分布。
4. 摘要(Summary)
摘要与直方图类似,表示的也是一段时间内的数据结果,但是摘要反应的数据内容不太一样。摘要一般用于标识分位值,分位值其实就是我们常说的TP90、TP99等。例如有100个耗时数值,将所有的数值从低到高排列,取第90%的位置,这个位置的值就是TP90的值,如果这个桶对应的值假设是80ms,那么就代表小于等于90%位置的请求都≤80ms。
Kubernetes微服务监控体系
前面我们从整体上描述了监控系统分层以及理解指标类监控系统所需要掌握的几类常见的指标类型。接下来我们重点探讨基于Kubernetes的微服务监控体系。
从监控对象及系统分层的角度看,监控系统需要监控的范围是非常广泛的,但从微服务监控的角度来说,如果你的微服务部署完全是基于Kubernetes云原生环境的,那么我们需要关注的监控对象主要就是Kubernetes集群本身以及运行其中的微服务应用容器。例如对容器资源使用情况,如CPU使用率、内存使用率、网络、I/O等指标的监控。
当然,这并不是说像基础层的物理机、虚拟机设备或者中间层软件的监控我们不需要关注,只是这部分工作一般会有专门的人员去维护。而如果使用的是云服务,那么云服务厂商大都已经为我们提供了监控支持。此外,对于基础物理层及大部分中间软件的监控并不是本文所要表达的重点,所以也就不再做过多的实践,大家对此有个全局的认识即可。
而回到以Kubernetes为载体的微服务监控体系,虽然曾经Kubernetes项目的监控体系非常复杂,社区中也有很多方案。但是这套体系发展到今天,已经完全演变成了以Prometheus项目为核心的一套统一方案。在本节的内容中我们就将演示如何围绕Prometheus来构建针对Kubernetes的微服务监控系统。
1. Prometheus简介
经过行业多年的实践和沉淀,目前监控系统按实现方式主要可以分为四类:1)、基于时间序列的Metrics(度量指标)监控;2)、基于调用链的Tracing(链路)监控;3)、基于Logging(日志)的监控;4)、健康性检查(Healthcheck)。而在上述几种监控方式中Metrics监控是其中最主要的一种监控方式。
简单理解Metrics的表现形式,就是在离散的时间点上产生的数值点[Time,Value],由某个指标组成的一组[Time,Value]数值点序列也被称为时间序列,所以Metrics监控也常常被称为时间序列监控。
如上所述,我们简单阐述了指标系统的基本特点,而接下来要介绍的Prometheus就是一款基于时间序列的开源Metrics类型的监控系统,它可以很方便地进行统计指标的存储、查询和告警。从整体上看Prometheus的系统结构,如下图所示:
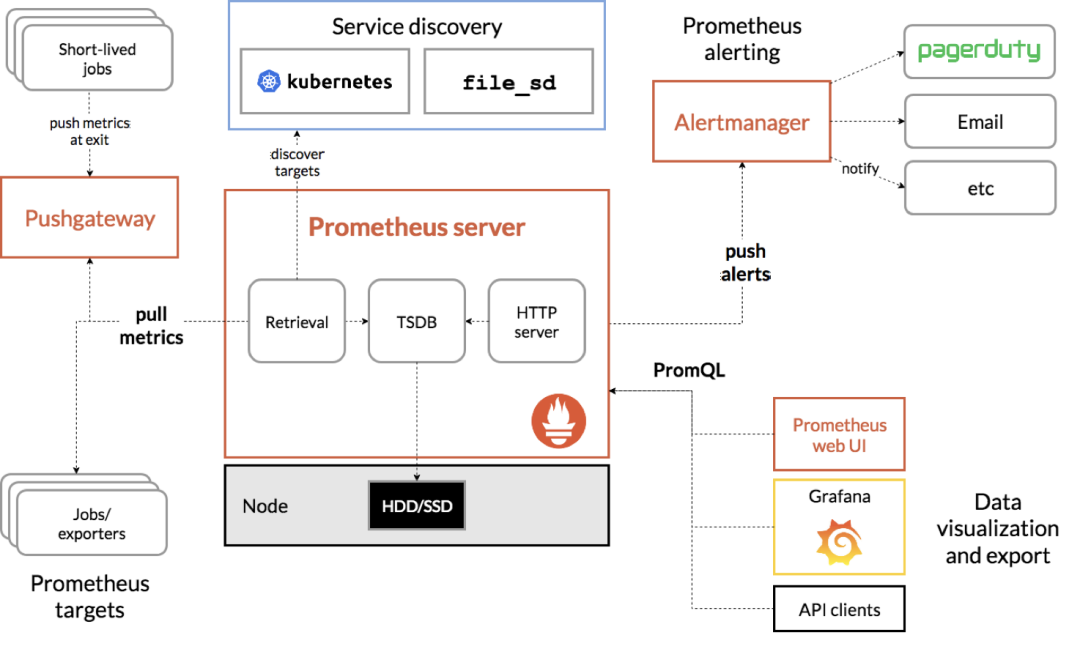
从上图中可以看出,Prometheus工作的核心,主要是使用Pull(拉取)的模式去收集被监控对象的Metrics数据(监控指标数据),然后由Prometheus服务器将收到的指标数据进行聚合后存储到TSDB(时间序列数据库,例如OpenTSDB、InfluxDB)中,以便后续根据时间自由检索。
有了这套核心机制,Prometheus剩下的组件就主要是用来配合这套机制运行的了。比如PushGateway,它可以允许被监控对象以Push的方式向Prometheus推送Metrics数据。而Alertmanager,则可以根据Metrics信息灵活地设置报警。
此外,Prometheus还提供了一套完整的PromQL查询语言,通过其提供的HTTP查询接口,使用者可以很方便地将指标数据与Grafana(可视化监控指标展示工具)结合起来,从而灵活地定制属于系统自身的关键指标监控Dashboard(看板)。
2. Prometheus Operator安装部署
前面我们简单介绍了Prometheus监控系统的基本原理,接下来的内容将以实操的方式演示如何使用Prometheus构建一套针对Kubernetes集群的微服务监控体系。
在实际的应用场景中,针对不同的监控对象Prometheus的部署方式也会有所不同。例如要监控的对象是底层的物理机,或者以物理机方式部署的数据库等中间件系统,那么这种情况下一般也会将Prometheus监控系统的部署环境放置在物理机下。
而如果针对的是Kubernetes集群的监控,那么现在主流的方式是采用Promethues-Operator将Promethues部署到Kubernetes集群之中,这样能以更原生的方式实施对Kubernetes集群及容器的监控。这里所说的Promethues-Operator 是指专门针对Kubernetes的Promethues封装包,它可以简化Promethues的部署和配置。
接下来我们具体演示如何通过Promethues-Operator在Kubernetes中快速安装部署Promethues(Kubernetes实验环境可参考本专栏相关内容),具体步骤如下:
1)、安装Helm
在本次安装过程中,将使用到Kubernetes的包管理工具Helm。Helm是Kubernetes的一种包管理工具,与Java中的Maven、NodeJs中的Npm以及Ubuntu的apt和CentOS的yum类似。主要用来简化Kubernetes对应用的部署和管理。
首先从Github下载相应的Helm安装包,具体命令参考如下:
#找到Github中Helm相关的发布包,参考链接如下
https://github.com/helm/helm/releases
#确定好相关版本后,将具体安装版本下载至某个安装了kubectl的节点
wget https://get.helm.sh/helm-v3.4.0-rc.1-linux-amd64.tar.gz
解压,并将下载的可执行Helm文件拷贝到文件夹/usr/local/bin下,命令如下:
tar -zxvf helm-v3.4.0-rc.1-linux-amd64.tar.gz
#将下载的可执行helm文件拷贝到文件夹/usr/local/bin下
mv linux-amd64/helm /usr/local/bin/
之后执行helm version,如果能看到Helm版本信息,就说明Helm客户端安装成功了,具体如下:
$helm version
version.BuildInfo{Version:"v3.4.0-rc.1",
GitCommit:"7090a89efc8a18f3d8178bf47d2462450349a004",
GitTreeState:"clean", GoVersion:"go1.14.10"}
安装完Helm客户端后,由于一些公共Kubernetes包是在远程仓库中管理的,所以还需要添加helm charts(Helm中的Kubernetes安装包又叫charts)官方仓库,命令如下:
$helm repo add stable https://charts.helm.sh/stable
查看本地helm仓库是否添加成功,命令如下:
$helm repo list
NAME URL
stable https://charts.helm.sh/stable
此时,查看Helm仓库就能看到各种组件的charts列表了,命令效果如下:
$helm search repo stable
NAME CHART VERSION APP VERSION DESCRIPTION
stable/acs-engine-autoscaler 2.1.3 2.1.1 Scales worker nodes within agent pools
stable/aerospike
...
如上所示,此时通过“helm search”命令就可以查看到各种stable版本的Kubernetes安装包了!
2)、Helm搜索Prometheus-Operator安装包
在具体安装Prometheus-Operator之前,我们先用“helm”命令搜索Prometheus相关的charts包,命令如下:
$ helm search repo prometheus
具体搜索结果如下图所示:
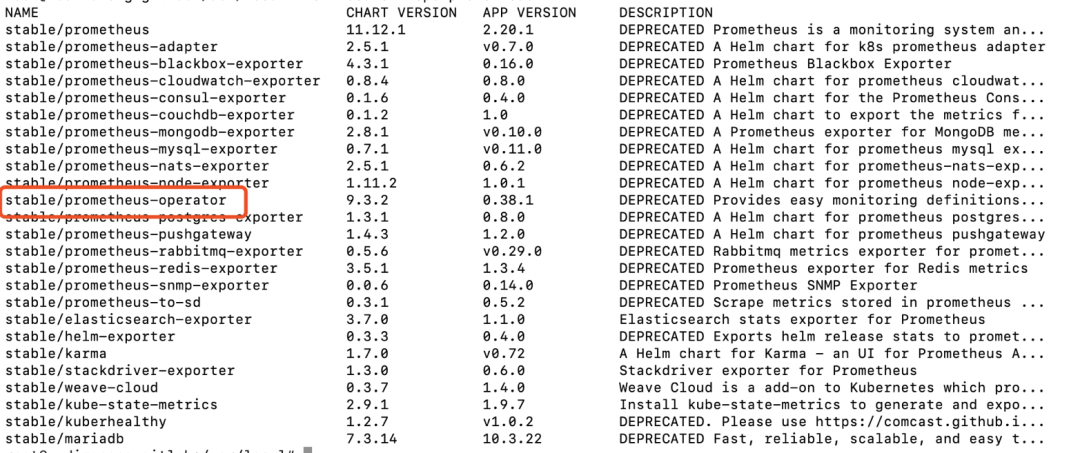
如上图所示,我们可以看到Helm仓库中可以搜索到版本为0.38.1的“stable/prometheus-operator”的安装包。接下来就可以通过helm具体安装了!
3)、Helm安装Prometheus-Operator监控系统
接下来啊,通过Helm具体安装prometheus-operator监控系统,命令如下:
#创建k8s名称空间
kubectl create ns monitoring
#通过helm安装promethues-operator监控系统
helm install promethues-operator stable/prometheus-operator -n monitoring
执行安装命令后,输出结果如下:
WARNING: This chart is deprecated
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
NAME: promethues-operator
LAST DEPLOYED: Mon Oct 26 10:15:45 2020
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
*******************
*** DEPRECATED ****
*******************
* stable/prometheus-operator chart is deprecated.
* Further development has moved to https://github.com/prometheus-community/helm-charts
* The chart has been renamed kube-prometheus-stack to more clearly reflect
* that it installs the `kube-prometheus` project stack, within which Prometheus
* Operator is only one component.
The Prometheus Operator has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=promethues-operator"
Visit https://github.com/coreos/prometheus-operator for instructions on how
to create & configure Alertmanager and Prometheus instances using the Operator.
执行完安装命令后,查看具体的Kubernetes Pods信息,命令如下:
$ kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-promethues-operator-promet-alertmanager-0 2/2 Running 0 5m42s
prometheus-promethues-operator-promet-prometheus-0 3/3 Running 1 5m31s
promethues-operator-grafana-5df74d9cb4-5d475 2/2 Running 0 6m53s
promethues-operator-kube-state-metrics-89d8c459f-449k4 1/1 Running 0 6m53s
promethues-operator-promet-operator-79f8b5f7ff-pfpbl 2/2 Running 0 6m53s
promethues-operator-prometheus-node-exporter-6ll4z 1/1 Running 0 6m53s
promethues-operator-prometheus-node-exporter-bvdb4 1/1 Running 0 6m53s
如上所示,可以看到Prometheus监控系统相关的组件都以Pod的方式运行在了Kubernetes集群中。
Prometheus监控效果演示
通过前面的实际操作,我们通过Helm的方式已经将Prometheus Operator安装包部署在了Kubernetes集群之中。而此时的Prometheus实际上就已经开始发挥作用,并采集了各类Kubernetes的运行指标信息。可以通过Promethues内置的监控界面对此进行查看,具体步骤如下:
查看Kubernetes中查看内置监控界面所在的Pod节点,命令如下:
kubectl -n monitoring get svc
使用nodeport方式将promethues-operator内置界面服务暴露在集群外,并指定使用30444端口,命令如下:
kubectl patch svc promethues-operator-promet-prometheus -n monitoring -p '{"spec":{"type":"NodePort","ports":[{"port":9090,"targetPort":9090,"nodePort":30444}]}}'
service/promethues-operator-promet-prometheus patched
此时在浏览器中输入Pod节点所在的宿主机IP+端口地址,URL示例如下:
http://10.211.55.11:30444/graph
此时就可以看到Promethues内置的监控可视化界面了,效果如下图所示:
而如果此时以PromeQL的方式查看一个具体指标,以“http_requests_total”为例,展示效果如图所示:
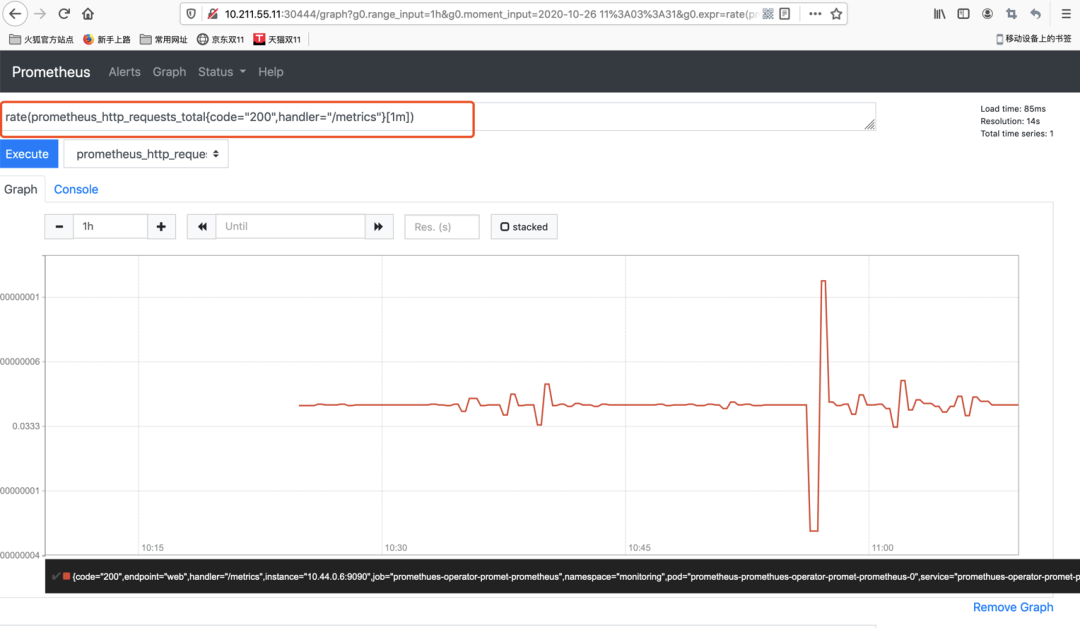
由此说明,此时Promethues监控系统已经开始运行,并采集了相关Metrics指标数据!
Grafana可视化监控系统
Grafana是一个强大的跨平台的开源度量分析和可视化工具,可以将采集的指标数据进行定制化的图形界面展示,经常被用作为时间序列数据和应用程序分析的可视化。Grafana支持多种数据源,如InfluxDB、OpenTSDB、ElasticSearch以及Prometheus。
前面我们在Kubernetes中安装部署Prometheus-Operator时,实际上Grafana就已经被集成并运行了,可以通过Kubernetes的相关命令查询Grafana的实际运行Pod,并将其Web端口对外进行暴露,具体如下:
#查看服务节点信息
kubectl -n monitoring get svc
#使用nodeport方式将promethues-operator-grafana暴露在集群外,指定使用30441端口
kubectl patch svc promethues-operator-grafana -n monitoring -p '{"spec":{"type":"NodePort","ports":[{"port":80,"targetPort":3000,"nodePort":30441}]}}'
需要注意由于Grafana的应用运行的默认端口为80,为避免实验环境冲突,这里映射时将目标容器端口指定为3000,并最终将节点端口映射为30441。完成后,浏览器输入URL:
#IP地址为映射命令执行时所在的节点
http://10.211.55.11:30441
如果映射正常,此时会返回Grafana可视化图形界面的登录界面,如图所示:
这里缺省登录账号密码为:admin/prom-operator。输入后可进入Grafana主界面如下图所示:
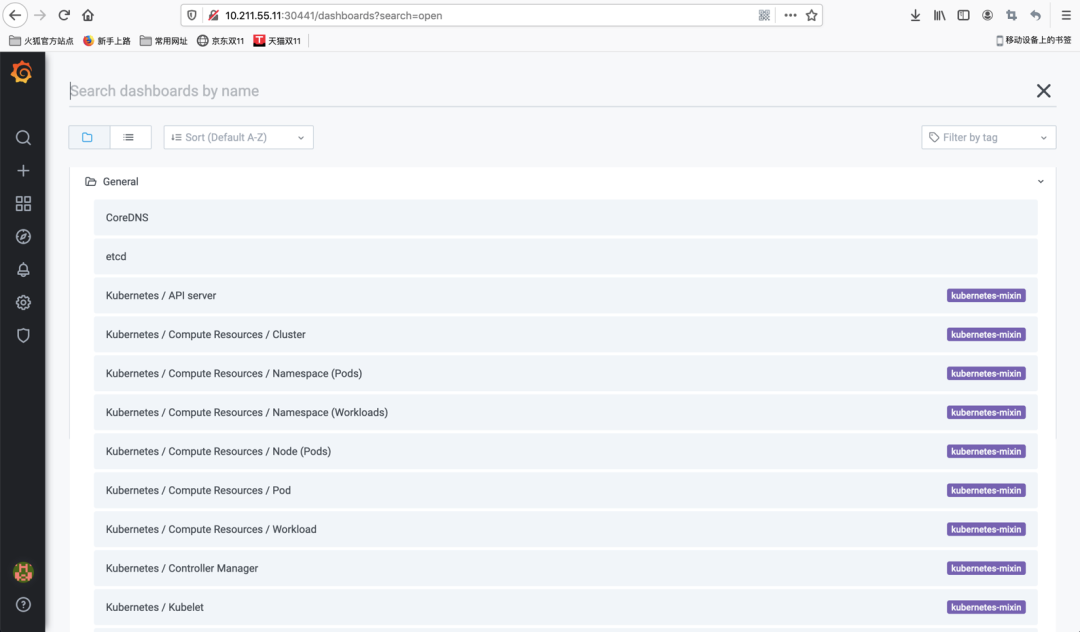
可以看到部署完成的Grafana已经默认内置了许多针对Kubernetes平台的企业级监控Dashboard,例如针对Kubernetes集群组件的“Kubernetes/API server”、“Kubernetes/Kubelet”,以及针对Kubernetees计算资源的“Kubernetes/Compute Resources/Pod”、“Kubernetes/Compute Resources/Workload”等等。
这里我们找一个针对Kubernetes物理节点的“Nodes”监控Dashboard,点击打开后看到的监控效果如下图所示:
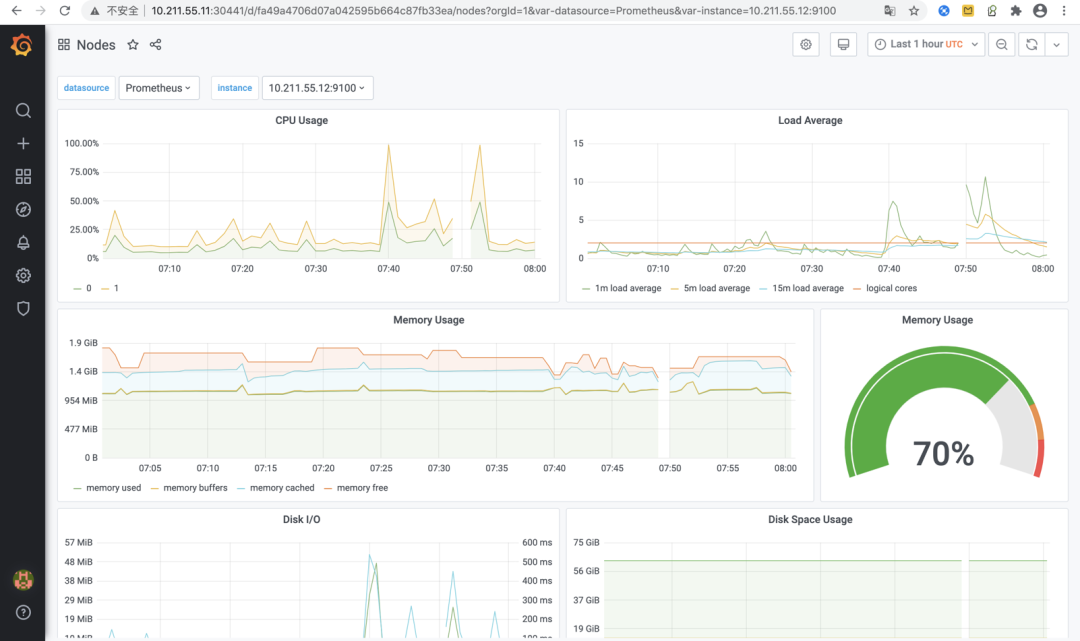
上图所示的Dashboard中展示了Kubernetes集群所在的各物理节点CPU、负载、内存、磁盘I/O、磁盘空间、网络传输等硬件资源的使用情况。从这些丰富的视图可以看出Grafana强大的监控指标可视化能力!
后记
本文给大家从理论到实践简单介绍了Kubernetes微服务监控体系的构建步骤,希望能够对大家学习Kubernetes有所帮助。目前以Kubernetes为代表的容器化技术已经成为现代软件应用发布的标准方式,作为一名普通研发人员,对Kubernetes的学习将有助于我们更深入的理解整体软件系统的构建原理,也是我们进阶提升必不可少的知识储备!在本公众号的《Devops专栏》中汇总了关于Kubernetes学习的相关文章,感兴趣的朋友可以进来看看!
—————END—————

本文分享自微信公众号 - 无敌码农(jiangqiaodege)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/3550665/blog/4769168