https://zhuanlan.zhihu.com/p/107350079
作者:Xu LIANG
编译:ronghuaiyang (AI公园)
介绍最基本的XLNet的原理,理解XLNet和BERT的直觉上的不同点。


在发布后不到一周,我周围的NLP领域的每个人似乎都在谈论XLNet。
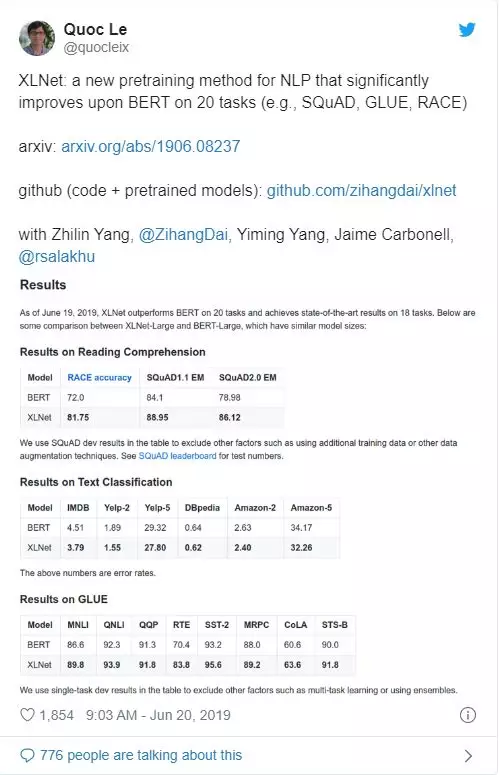
是的,“在20个任务上比BERT做得更好”确实吸引了我们的眼球。但更重要的是理解它是如何工作的,以及为什么它比BERT表现得更好。所以我写了这个博客来分享我读了这篇文章后的想法。
内容结构如下。
- 什么是XLNet?
- XLNet和BERT有什么不同?
- XLNet是如何工作的?
什么是XLNet?
首先,XLNet是一个类似于bert的模型,而不是一个完全不同的模型。但它是一个非常有前途和潜力的。总之,XLNet是一种广义的自回归预训练方法。
那么,什么是自回归(AR)语言模型?
AR语言模型是利用上下文单词预测下一个单词的一种模型。但是在这里,上下文单词被限制在两个方向,要么向前,要么向后。
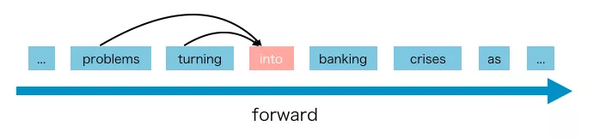
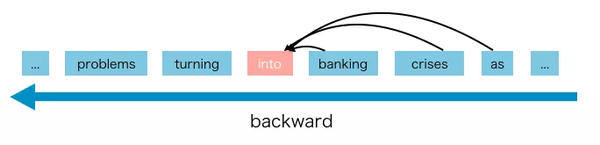
GPT和GPT-2都是AR语言模型。
AR语言模型的优点是擅长NLP生成任务。因为在生成上下文时,通常是正向的。AR语言模型在这类NLP任务中很自然地工作得很好。
但是AR语言模型有一些缺点,它只能使用前向上下文或后向上下文,这意味着它不能同时使用前向上下文和后向上下文。
XLNet 和BERT的区别是什么?
与AR语言模型不同,BERT被归类为自动编码器(AE)语言模型。
AE语言模型的目的是从损坏的输入中重建原始数据。
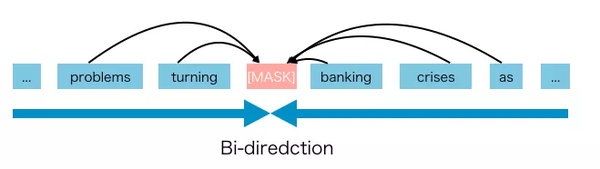
损坏的输入意味着我们使用在训练前阶段将原始tokeninto替换为 [MASK] 。我们的目标是预测into来得到原来的句子。
AE语言模型的优点是它可以在向前和向后两个方向上看到上下文。
但是AE语言模型也有其不足之处。它在预训练中使用了[MASK],但是这种人为的符号在finetune的时候在实际数据中时没有的,导致了预训练 — finetune的不一致。[MASK]的另一个缺点是它假设所预测的(mask掉的)token是相互独立的,给出的是未掩码的tokens。例如,我们有一句话“It shows that the housing crisis was turned into a banking crisis”。我们盖住了“banking”和“crisis”。注意这里,我们知道,盖住的“banking”与“crisis”之间隐含着相互关联。但AE模型是利用那些没有盖住的tokens试图预测“banking”,并独立利用那些没有盖住的tokens预测“crisis”。它忽视了“banking”与“crisis”之间的关系。换句话说,它假设预测的(屏蔽的)tokens是相互独立的。但是我们知道模型应该学习(屏蔽的)tokens之间的这种相关性来预测其中的一个token。
作者想要强调的是,XLNet提出了一种新的方法,让AR语言模型从双向的上下文中学习,避免了AE语言模型中mask方法带来的弊端。
XLNet如何工作?
AR语言模型只能使用前向或后向的上下文,如何让它学习双向上下文呢?语言模型由预训练阶段和调优阶段两个阶段组成。XLNet专注于预训练阶段。在预训练阶段,它提出了一个新的目标,称为重排列语言建模。我们可以从这个名字知道基本的思想,它使用重排列。
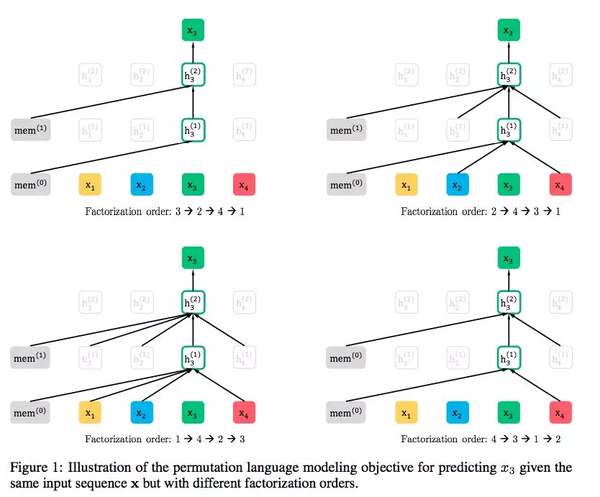
这里我们用一个例子来解释。序列顺序是[x1, x2, x3, x4]。该序列的所有排列如下。
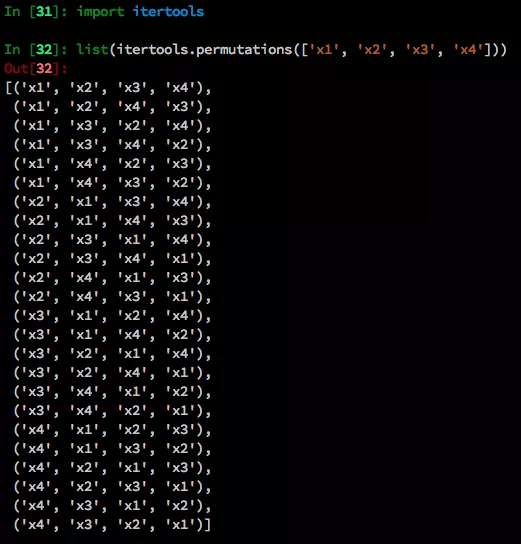
对于这4个tokens (N)的句子,有24个(N!)个排列。假设我们想要预测x3。24个排列中有4种模式,x3在第1位,第2位,第3位,第4位。
[x3, xx, xx, xx]
[xx, x3, xx, xx]
[xx, xx, x3, xx]
[xx, xx, xx, x3]
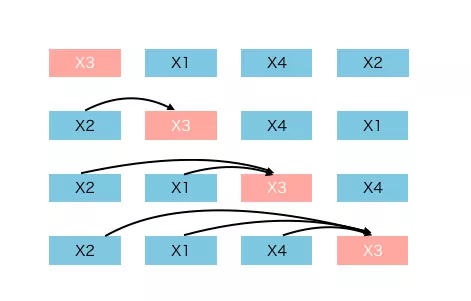
在这里,我们将x3的位置设为第t位,它前面的t-1个tokens用来预测x3。
x3之前的单词包含序列中所有可能的单词和长度。直观地,模型将学习从两边的所有位置收集信息。
具体实现要比上面的解释复杂得多,这里就不讨论了。但是你应该对XLNet有最基本和最重要的了解。
来自XLNet的灵感
与BERT将mask方法公布于众一样,XLNet表明重排列法是一种很好的语言模型目标选择。可以预见,未来在语言模型目标方面的探索工作将会越来越多。
英文原文:https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
来源:oschina
链接:https://my.oschina.net/u/4381258/blog/3204860