背景
日志系统接入的日志种类多、格式复杂多样,主流的有以下几种日志:
-
filebeat采集到的文本日志,格式多样 -
winbeat采集到的操作系统日志 -
设备上报到logstash的syslog日志 -
接入到kafka的业务日志
以上通过各种渠道接入的日志,存在2个主要的问题:
-
格式不统一、不规范、标准化不够 -
如何从各类日志中提取出用户关心的指标,挖掘更多的业务价值
为了解决上面2个问题,我们基于flink和drools规则引擎做了实时的日志处理服务。
系统架构
架构比较简单,架构图如下:
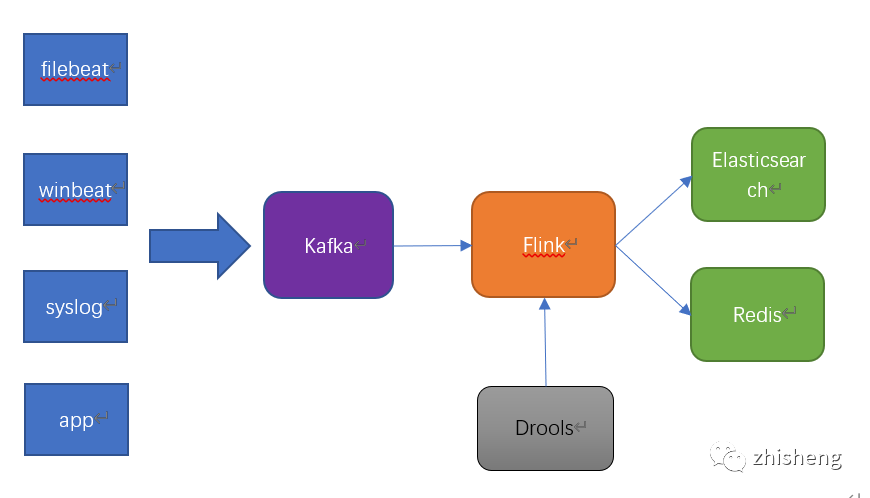
各类日志都是通过kafka汇总,做日志中转。
flink消费kafka的数据,同时通过API调用拉取drools规则引擎,对日志做解析处理后,将解析后的数据存储到Elasticsearch中,用于日志的搜索和分析等业务。
为了监控日志解析的实时状态,flink会将日志处理的统计数据,如每分钟处理的日志量,每种日志从各个机器IP来的日志量写到Redis中,用于监控统计。
模块介绍
系统项目命名为eagle。
-
eagle-api:基于springboot,作为drools规则引擎的写入和读取API服务。
-
eagle-common:通用类模块。
-
eagle-log:基于flink的日志处理服务。
重点讲一下eagle-log:
对接kafka、ES和Redis
对接kafka和ES都比较简单,用的官方的connector(flink-connector-kafka-0.10和flink-connector-elasticsearch6),详见代码。
对接Redis,最开始用的是org.apache.bahir提供的redis connector,后来发现灵活度不够,就使用了Jedis。
在将统计数据写入redis的时候,最开始用的keyby分组后缓存了分组数据,在sink中做统计处理后写入,参考代码如下:
String name = "redis-agg-log";
DataStream<Tuple2<String, List<LogEntry>>> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime)).trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.process(new ProcessWindowFunction<LogEntry, Tuple2<String, List<LogEntry>>, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<LogEntry> iterable, Collector<Tuple2<String, List<LogEntry>>> collector) {
ArrayList<LogEntry> logs = Lists.newArrayList(iterable);
if (logs.size() > 0) {
collector.collect(new Tuple2(s, logs));
}
}
}).setParallelism(redisSinkParallelism).name(name).uid(name);
后来发现这样做对内存消耗比较大,其实不需要缓存整个分组的原始数据,只需要一个统计数据就OK了,优化后:
String name = "redis-agg-log";
DataStream<LogStatWindowResult> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime))
.trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.aggregate(new LogStatAggregateFunction(), new LogStatWindowFunction())
.setParallelism(redisSinkParallelism).name(name).uid(name);
这里使用了flink的聚合函数和Accumulator,通过flink的agg操作做统计,减轻了内存消耗的压力。
使用broadcast广播drools规则引擎
1、drools规则流通过broadcast map state广播出去。
2、kafka的数据流connect规则流处理日志。
//广播规则流
env.addSource(new RuleSourceFunction(ruleUrl)).name(ruleName).uid(ruleName).setParallelism(1)
.broadcast(ruleStateDescriptor);
//kafka数据流
FlinkKafkaConsumer010<LogEntry> source = new FlinkKafkaConsumer010<>(kafkaTopic, new LogSchema(), properties);env.addSource(source).name(kafkaTopic).uid(kafkaTopic).setParallelism(kafkaParallelism);
//数据流connect规则流处理日志
BroadcastConnectedStream<LogEntry, RuleBase> connectedStreams = dataSource.connect(ruleSource);
connectedStreams.process(new LogProcessFunction(ruleStateDescriptor, ruleBase)).setParallelism(processParallelism).name(name).uid(name);
具体细节参考开源代码。
小结
本系统提供了一个基于flink的实时数据处理参考,对接了kafka、redis和elasticsearch,通过可配置的drools规则引擎,将数据处理逻辑配置化和动态化。
对于处理后的数据,也可以对接到其他sink,为其他各类业务平台提供数据的解析、清洗和标准化服务。
项目地址:
https://github.com/luxiaoxun/eagle
作者:阿凡卢
出处:http://www.cnblogs.com/luxiaoxun/


本文分享自微信公众号 - 浪尖聊大数据(bigdatatip)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/4590259/blog/4534314